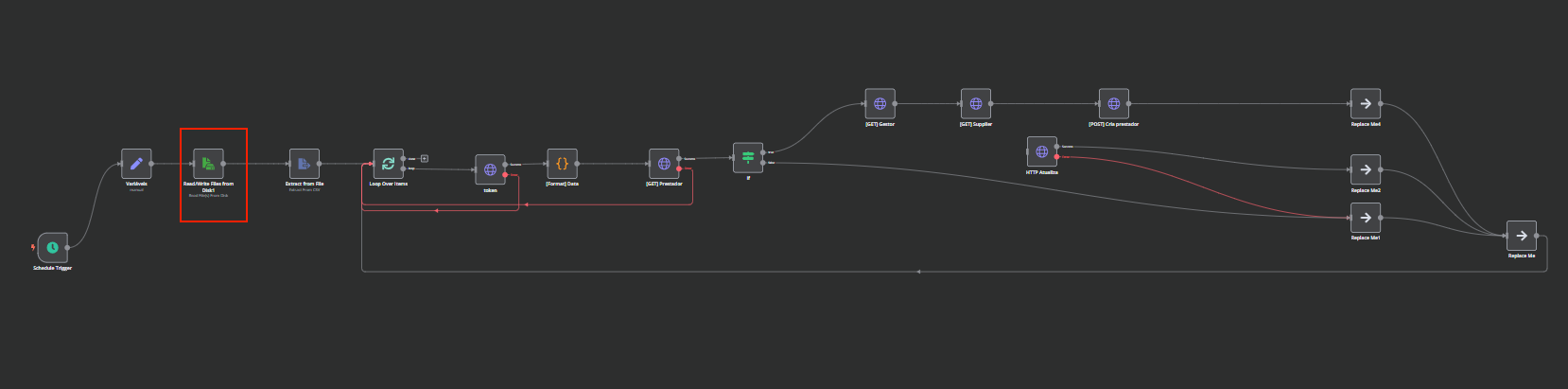
I am using the Read Write component in n8n to load users from a CSV file stored locally on the same machine running n8n. The CSV contains around 39,000 records, but the process takes a very long time to execute. Additionally, I need the users to be loaded so they can be processed in a loop over items. Is there any way to optimize this workflow to improve performance?
Thanks for posting here and welcome to the community!
I cannot see the rest of your workflow to well from the screenshot but you can optimize it by using sub-workflows. This is a way to modularize your data flows so some parts of it can run in parellel and also clean up some memory that’s not needed anymore for the other processes. This generally improves performance.
Have a look in our docs on how to do it:
Additionally for very large datasets, it might be more efficient to import the CSV into a database first, then use database queries to process the data in chunks.
You can find some examples in our workflow template collection:
The issue of importing the csv to a bank was the first scenario I tested, but still, I felt a slowness in processing, the N8N gets slow after a while, I even started scheduling it to see if running with a schedule it would run better, I’ll test it again. form of subworkflow and see as an employee whether it would meet my needs