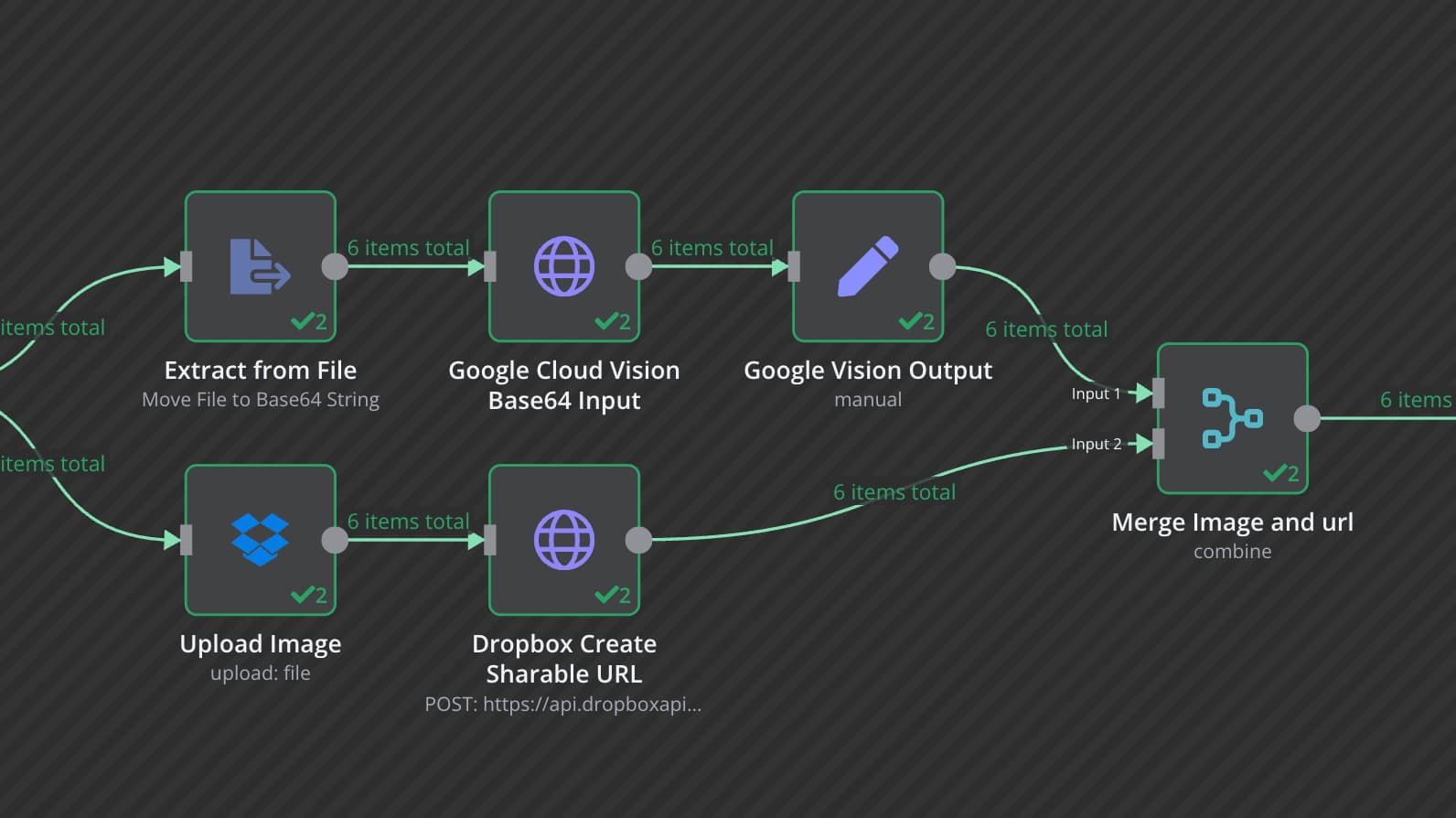
I utilize it for OCR input images. However, the issue is that it provides both the content and the vectorized data which I don’t need. With over 1,400 items to process in a loop, the workflow frequently stopped due to memory problems. How can I improve this node in such a situation? Like is there a method to eliminate the data after each iteration?
You might want to try first defining a “fieldMask” in your DocumentAI request which should allow you to filter down the response. See documentation
FIELD_MASK: Specifies which fields to include in the Document output. This is a comma-separated list of fully qualified names of fields in FieldMask format.
Example: text,entities,pages.pageNumber
Ultimately, 1400 documents in a single execution will still require a huge amount to be kept in memory. One way to optimise would be looking to run those documents on separate executions instead and for this purpose, a message/job queue in combination with n8n queue mode might be what you’re looking for. eg. SQS, RabbitMQ
Thank you for the suggestion regarding the memory issue.
I tried creating a sub-workflow to loop the items, but it didn’t work very well.
Do you think it would help if I increased the size of my server from 2GB to something like 4GB? I am looking for a quick and simply way to fix this situation