I deleted my containers and their associated Volumes. And redeployed. I am getting the same error.
Is there is a component in the provided Docker Compose Starter Kit (from this site) missing? Does the postgres container need another system extension / module “vector” installing in this step? Or included with the base image? (Also my first dabble into Postgres, using the PGAdmin GUI as well)
Have I misconfigured something?
I have changed the Credentials tab, and both Postgres and Local Ollama have a successful tick.
This at least executes and does not error. However, it does not seem to import data into the database, therefore subsequent chats do not use this uploaded info.
Can I ask for assistance to resolve this behaviour?
Ensure to copy your n8n workflow and paste it in the code block, that is in between the pairs of triple backticks, which also could be achieved by clicking </> (preformatted text) in the editor and pasting in your workflow.
```
<your workflow>
```
That implies to any JSON output you would like to share with us.
Make sure that you have removed any sensitive information from your workflow and include dummy or pinned data with it!
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE IF NOT EXISTS embeddings (
id SERIAL PRIMARY KEY,
embedding vector,
text text,
created_at timestamptz DEFAULT now()
);
Looking up the container image you have used, on the Docker Hub page, it says to use the pgvector/pgvector if you want pgvector 0.6.0+, so it seems prudent to keep my choice of image.
Where & how is your SQL script executed, within the Docker Compose definition?
A (if simple) explanation of why an embeddings table is created? Is this a specific naming convention? I am expecting it is not auto-generated on the first DB write?
You can execute the script manually if you wish. I just prefered to have it run automatically when container is created.
I simply added the file “pgvector-init.sql” to the repository before running docker compose create.
To execute the SQL manually,
Go to the “pgvector” container in Docker and click on Exec tab
Use psql CLI to login, psql -h <CONTAINER_NAME> -p 5432 -d <DATABASE_NAME> -U <USER> -W
Run the queries
A (if simple) explanation of why an embeddings table is created? Is this a specific naming convention? I am expecting it is not auto-generated on the first DB write?
It could be called anything but you need a table to record your data to. To be honest, I’m not sure if the table could be created automatically when using the Node but it looks like you would have to enable/create vector first, CREATE EXTENSION IF NOT EXISTS vector;.
So I deleted my Docker Compose, including the Volumes.
Then added in the extra volumes line to the docker-compose.yml file as you described.
Then I brought the “new” Docker Compose stack up again. Using PGADmin, I can see an embeddings table of the same structure as in the SQL file, so I have to assume this executed as expected.
I created a new n8n Workflow, as below. This is able to read in the TXT file I upload, and I can see this in the right-hand side Output view when I click on the Extract from File node.
This should be passed on to my PGVector node. It executes successfully, but there is no data in the Postgres DB (checked again via PGAdmin).
I noticed when clicking into the PGVector Store node, under Options, if I choose Column Names it lists:
ID Column Name: id
Vector Column Name: embedding
Content Column Name: text
Metadata Column Name: metadata
The oddity here is that we did not create a metadata column in the embeddings table definition. Is it required? What datatype does this need to be? Why is it not included in your sample code, @ihortom ?
Equally, when I add in a new Collections option to this node, which I called my_docs_collection, then re-run the Workflow, I can see this new table in PGAdmin, and also it is populated with 1 row.
This also creates a new collection_id column in the embeddings table.
All this behaviour suggests there is no issue with writing to the database from the credentials I have within n8n…
I have data written into my Postgres DB! There are further issues, but this ticket can be closed.
My progress…
You can delete the Postgres DB tables. On the next Workflow, the tables are recreated with the correct columns and data types.
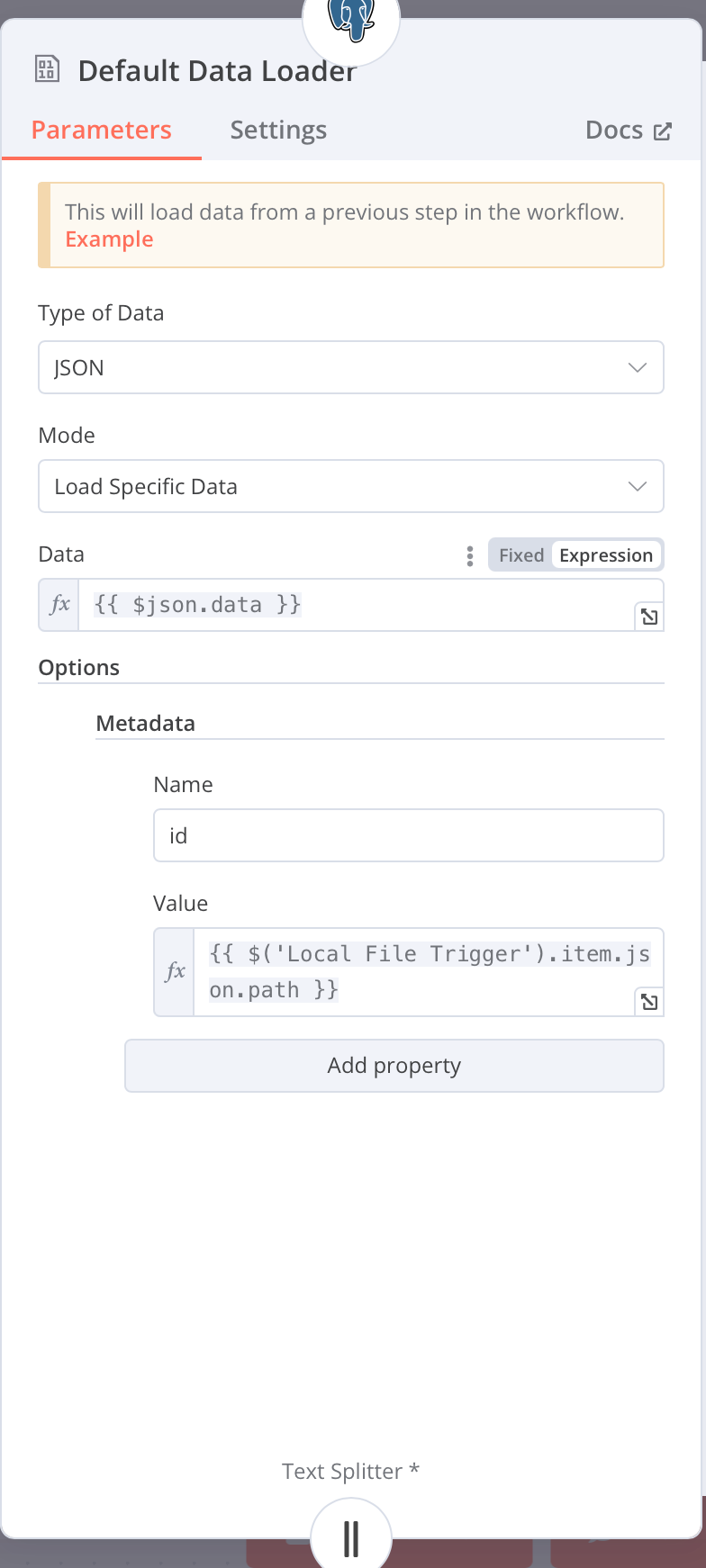
I had to add some more config to the Default Data Loader node, I guess to pass-through variables from a previous step or the DB insert command needed a minimum number of parameters, which I am not aware of. I only learnt of this following Cole Medin on YouTube. I am adjusting to use local Docker containers of pgvector/pgvector rather than the supabase/supabase, though both are Postgres underneath.
I still have issues with my Workflow, but the content of this thread is sufficiently resolved. I got the “vector” extension installed and writing to the database.