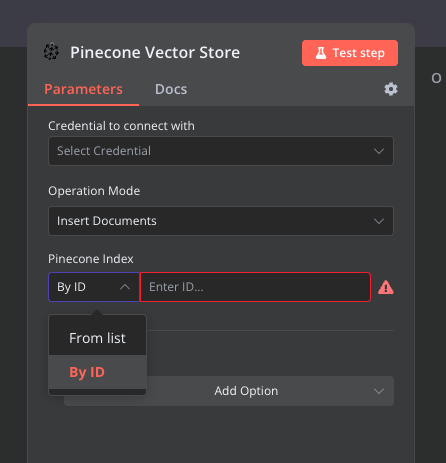
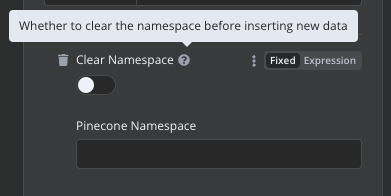
Hello, I’m facing the same issue. The only solution I found was to delete the namespace and then reinsert all the data. I’m a developer, and fortunately, I’ve worked on a project that used a vectorized database called Chroma. In that project, I created a system to assign an ID to chunks. Before inserting any data, I would check if the data was already present based on the ID. This way, I avoided adding duplicate data to Chroma. The code looked like this
import argparse
import os
import shutil
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.schema.document import Document
from langchain.vectorstores.chroma import Chroma
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.embeddings import OpenAIEmbeddings
import tempfile
CHROMA_PATH = “data/chroma”
DATA_PATH = “data/filtred-data”
def save_chunks_to_file(chunks):
output_file = “data\chunks\all_chunks\all_chunks.txt”
temp_file_path = None
try:
with tempfile.NamedTemporaryFile(mode=‘a’, delete=False, encoding=‘utf-8’) as temp_file:
for chunk in chunks:
str_chunk = str(chunk)
temp_file.write(f"{str_chunk}\n{‘_’ * 100}\n\n")
temp_file_path = temp_file.name
shutil.move(temp_file_path, output_file)
print("Chunks salvos com sucesso no arquivo.")
return chunks
except Exception as e:
print(f"Erro ao salvar os chunks no arquivo: {e}")
return chunks
def create_and_update_data_base():
# Check if the database should be cleared (using the --clear flag).
parser = argparse.ArgumentParser()
parser.add_argument("--reset", action="store_true", help="Reset the database.")
args = parser.parse_args()
#if args.reset:
# print("✨ Clearing Database")
# clear_database()
# Create (or update) the data store.
documents = load_documents()
chunks = split_documents(documents)
add_to_chroma(chunks)
def load_documents():
loader = DirectoryLoader(DATA_PATH, glob=“*.txt”)
documents = loader.load()
return documents
def split_documents(documents: list[Document]):
text_splitter = RecursiveCharacterTextSplitter(
separators=‘-’ * 100,
chunk_size=1000,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
chunks=text_splitter.split_documents(documents)
save_chunks_to_file(chunks)
return chunks
def add_to_chroma(chunks: list[Document]):
# Load the existing database.
db = Chroma(
persist_directory=CHROMA_PATH, embedding_function=OpenAIEmbeddings()
)
# Calculate Page IDs.
chunks_with_ids = calculate_chunk_ids(chunks)
# Add or Update the documents.
existing_items = db.get(include=[]) # IDs are always included by default
existing_ids = set(existing_items["ids"])
print(f"Number of existing documents in DB: {len(existing_ids)}")
# Only add documents that don't exist in the DB.
new_chunks = []
for chunk in chunks_with_ids:
if chunk.metadata["id"] not in existing_ids:
new_chunks.append(chunk)
if len(new_chunks):
print(f" Adding new documents: {len(new_chunks)}")
new_chunk_ids = [chunk.metadata["id"] for chunk in new_chunks]
db.add_documents(new_chunks, ids=new_chunk_ids)
db.persist()
else:
print("✅ No new documents to add")
def calculate_chunk_ids(chunks):
# This will create IDs like "data/monopoly.pdf:6:2"
# Page Source : Page Number : Chunk Index
last_page_id = None
current_chunk_index = 0
for chunk in chunks:
source = chunk.metadata.get("source")
page = chunk.metadata.get("page")
current_page_id = f"{source}:{page}"
# If the page ID is the same as the last one, increment the index.
if current_page_id == last_page_id:
current_chunk_index += 1
else:
current_chunk_index = 0
# Calculate the chunk ID.
chunk_id = f"{current_page_id}:{current_chunk_index}"
last_page_id = current_page_id
# Add it to the page meta-data.
chunk.metadata["id"] = chunk_id
return chunks
def clear_database():
if os.path.exists(CHROMA_PATH):
shutil.rmtree(CHROMA_PATH)
print(“\ndata base resetado\n”)
if name == “main”:
create_and_update_data_base()
#clear_database()
Unfortunately, I couldn’t implement this function in n8n. However, maybe it can help you. If you manage to implement it, I’d be grateful if you could let me know how you did it.