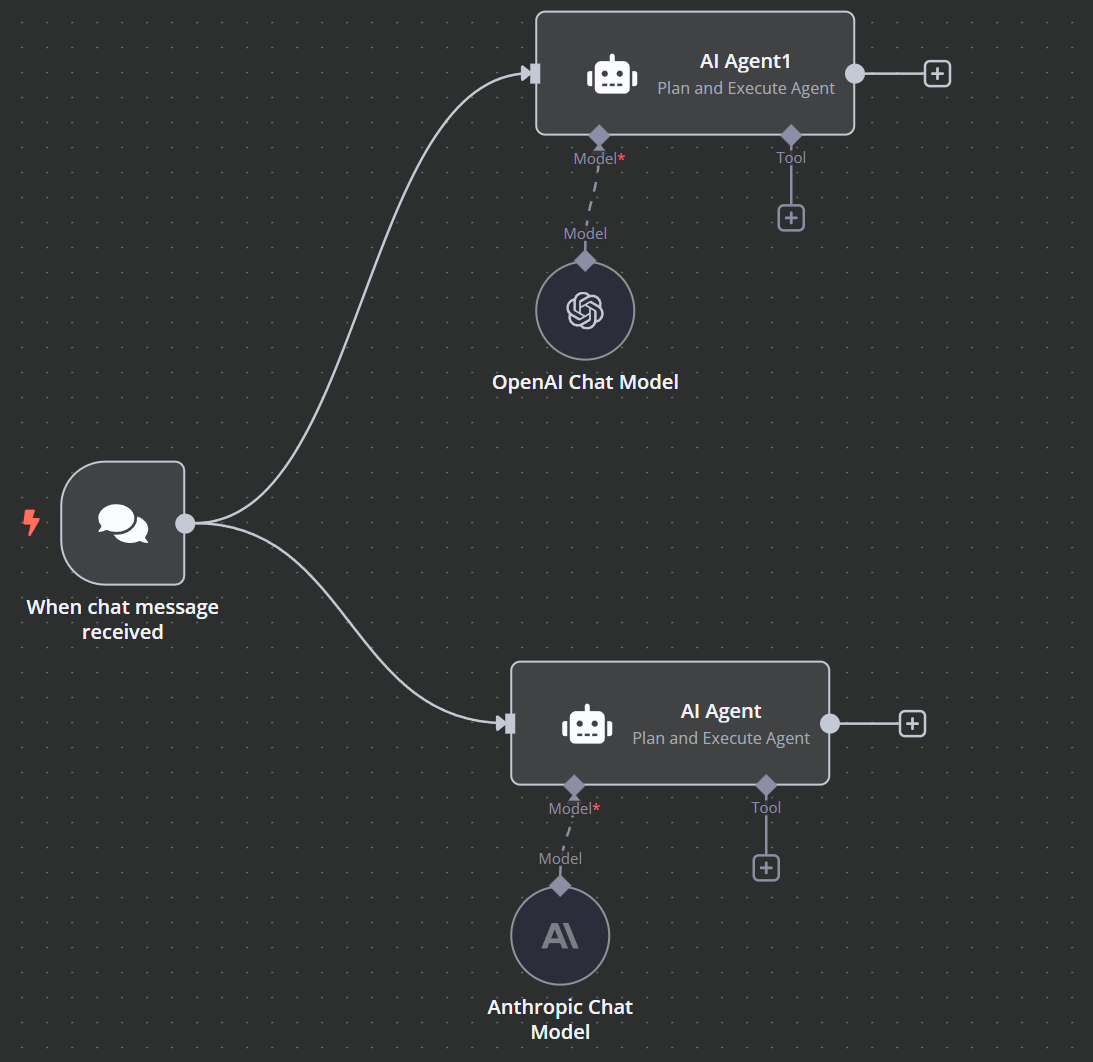
Hello everyone,
I am currently testing the Plan and Execute Agent using two models—Claude Haiku 3.5 and GPT-4o. My workflow is relatively simple: a chat message takes user input as a prompt, which is then processed by the models.
Through various tests with both basic and more complex prompts, I have noticed a significant difference in their performance. For simpler tasks, both models perform comparably. However, when handling more advanced prompts, Claude Haiku 3.5 tends to struggle.
Specifically, Haiku seems to drift off-topic, using substantially more tokens than GPT-4o while still failing to complete the assigned task properly. I wanted to ask if there is a known reason for this behavior. Is this simply a characteristic of the Claude model, or could it be related to how the Plan and Execute Agent operates internally? Could there be some underlying issue with how n8n interacts with Claude models?
Aside from refining the prompt or adjusting model parameters, are there any potential fixes for this? Of course, one option is to use GPT-4o instead, but my personal preference leans towards Claude. ![]()
Thanks for any ideas!