I have a multi-agent workflow. I am using PGSQL for both vector DB and storing chat history as well. In my sample workflow, I am using the same PG DB to generate SQL.
In credential I have create a Postgres Account and I have been able to connect to it. But there is not parameter there where I can mention the connection pool configurations.
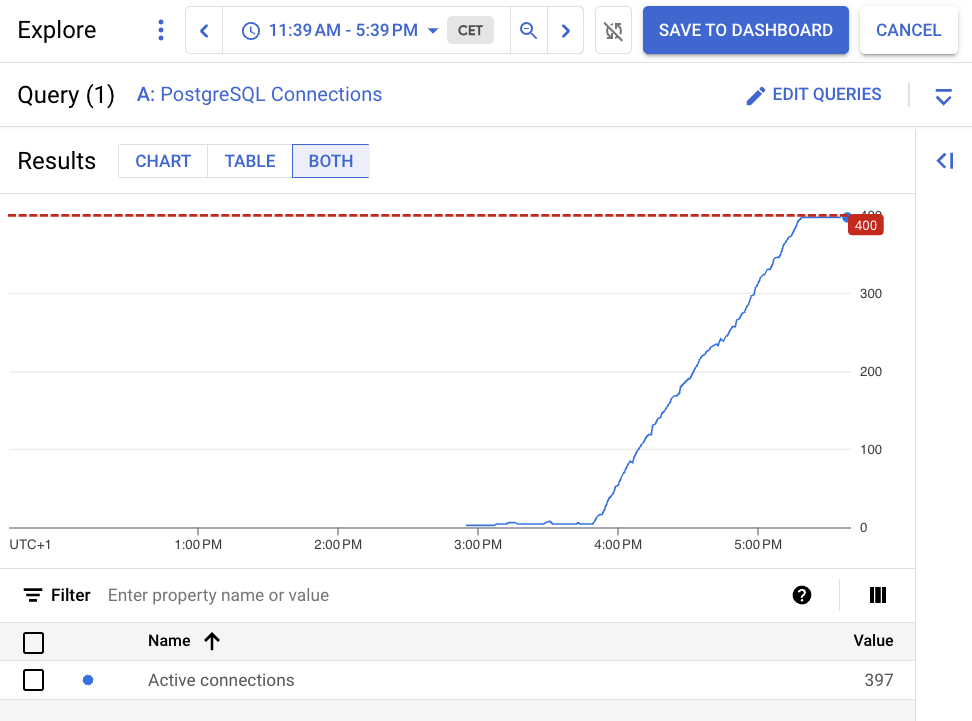
It was running fine for few rounds, but I see the following error sometimes.
If I restart the DB, the error goes away for sometime.
When researching further, I feel that n8n is opening a new connection every time it is trying to access the DB.
In my opinion, in a multi-agent workflow where the same DB when accessed across different steps it is opening a new connection rather than utilising the same connection or use the connection from the connection pool.
Ideally it should create a connection pool for each item in credentials section and reutilise wherever possible. NOTE: This is my assumption, and I may be wrong
Yes - It is a multi-agent workflow. So yes, based on the input request there may be multiple queries that may be used to query the chat-table.
The question here is that why the workflow is initiating multiple connections, it should first create a connection pool. The workflow should get the connections from the connection pool.
We need to fix connection pooling in the postgres node to support reusing the pool consistently across all executions that need that same postgres connection.
I’ve created an internal ticket, and we’ll try to prioritize this soon.
Great to hear you are addressing it, any ETA @netroy? This is a real blocker, unless I miss something. I have “ingestion” workflow that uses PGVector Vector Store in a loop to Insert Documents, and I hit this error after few dozens of operations.
Unfortunately I can’t offer any ETA on this, especially around the holiday season, as many folks are unavailable.
If this is urgent for you, a workaround could be to setup more workers with lower concurrency on the n8n side, and maybe setup a pgbouncer before the postgres.
Hopefully we’ll have an ETA in the first week of January.
Hello
I also ran into the same issue and understand how frustrating it can be. I shared a PR that resolves connection loss issues in the PostgreSQL pool, specifically in the VectorStorePGVector node. This solution ensures that connections are released correctly, avoiding blockages and workflow issues.
I hope this solution can be useful
Even on 1.77.0 ? can you share more details? like the error message that you are seeing? did you configure the number of connections in the postgres credential?
Checked my n8n cloud version and was still on 1.70.xx, did my update to the latest 1.77.x version right now. Checked the change log on git and tons of changes has been made. <3
I ended up placing an executeSQL node directly after the pgvector store node with the following:
SELECT pg_terminate_backend(pid)
FROM pg_stat_activity
WHERE state = ‘idle’
AND pid <> pg_backend_pid();
This resets all the idle connections prior to running the next insertion. It’s a temporary fix until corrected in n8n.
I highly recommend against this temporary fix for anyone using n8n in production.
This will likely cause more issues when you have concurrent executions, since a connection could go idle during the lifecycle on an execution, and it you force terminate it, that execution might fail on the next postgres node.
If you are seeing any issues like these on versions above 1.77, please let us know, and we’ll try our best to fix them.
If you are on versions below 1.77, please upgrade