This isn’t a bug in PG Memory it’s a context scoping issue.
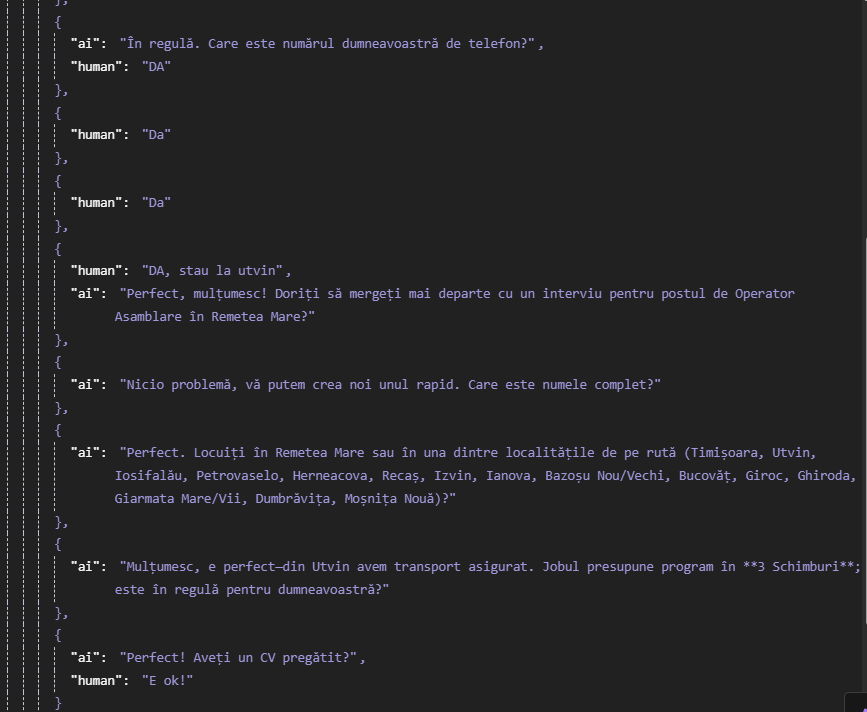
Your PG Memory is mixing conversations because all executions are writing to / reading from the same memory scope. Without a unique identifier, PG Memory treats every run as the same conversation.
Why it happens
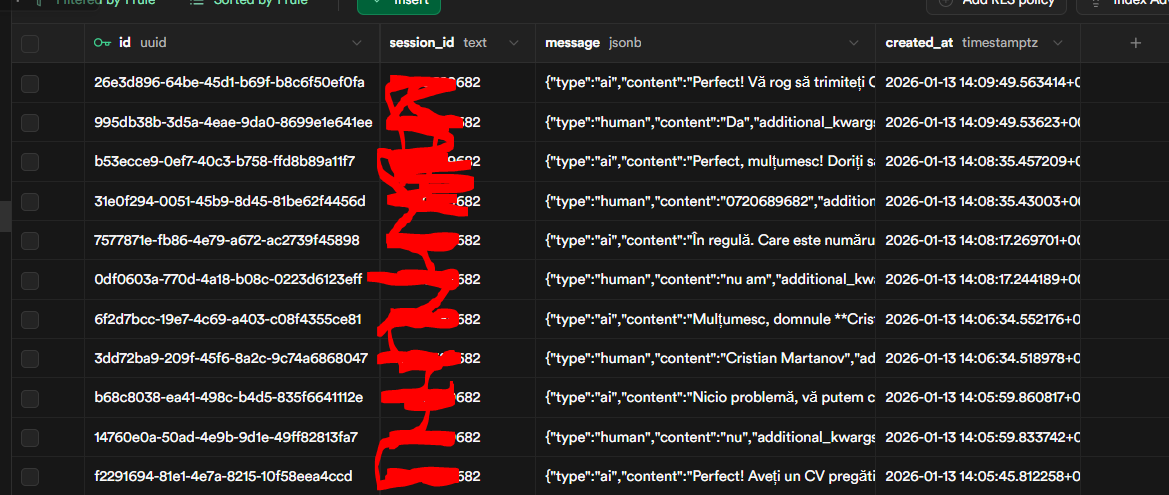
No unique session_id / conversation_id / user_id
PG Memory retrieves embeddings globally instead of per conversation
Result: unrelated past messages leak into the current context
How to fix it
Generate or pass a unique conversation key (e.g. WhatsApp number, user ID, thread ID)
Store it with every memory write
Filter memory reads by that same key
Example approach:
Use a Set node before PG Memory:
conversation_id = {{$json.from || $execution.id}}
Configure PG Memory to store + query by that ID (metadata / namespace)
Once memory is scoped per conversation, the context will stop getting mixed up.
This is expected behavior if memory isn’t partitioned PG Memory is doing exactly what it’s told to do.