Title:
“Referenced node is unexecuted” error in Default Data Loader — How to fix?
Message:
Hello everyone,
I’m building an n8n workflow to automatically ingest files (PDF, TXT, DOCX, Java, MD) from a local folder, extract their content using the Extract from File node, then load the data into the Default Data Loader node for indexing.
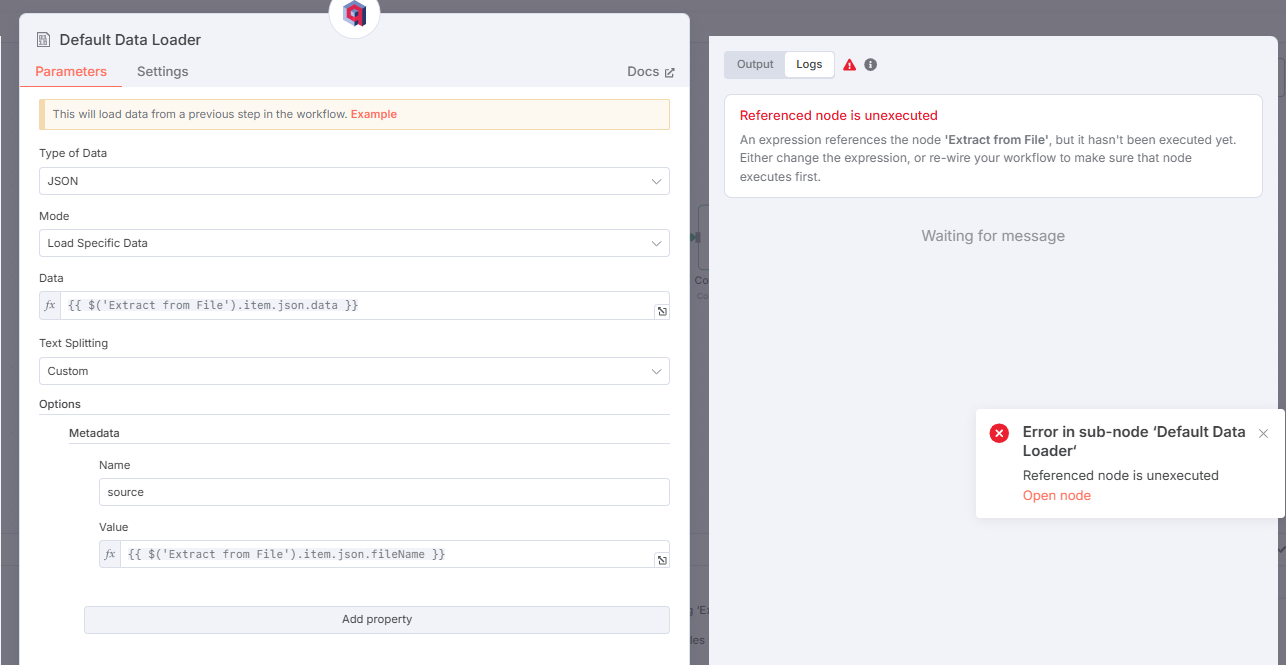
The problem I’m facing: when I run the workflow, the Default Data Loader node shows this error:
Referenced node is unexecuted
with the message:
“An expression references the node ‘Extract from File’, but it hasn’t been executed yet. Either change the expression, or re-wire your workflow to make sure that node executes first.”
What I’ve done:
The Read Files node correctly reads Java and MD files from my local folder.
The Extract from File node is configured to extract text with Keep Source = Both (JSON and Binary).
In the Default Data Loader, I use an expression like {{ $(‘Extract from File’).item.json.data }} to load the extracted data.
I’ve checked that all nodes are connected in order, but the error persists, especially when I test or run only the Default Data Loader node.
My questions:
How can I make sure the Extract from File node executes before the Default Data Loader node?
Is there a better way to write the expression to get the extracted data?
Any advice on structuring the workflow to avoid this error?
Thank you very much for your help!

{kind=link}