Hi friends,
Describe the problem/error/question
in our n8n cluster EXECUTIONS_MODE=queue
Our n8n setup contains redis(3 pod statefulset), n8n main( 1 pod deployment), n8n worker(5 pod deployment) and postgresql database(3 pod statefulset) containers.
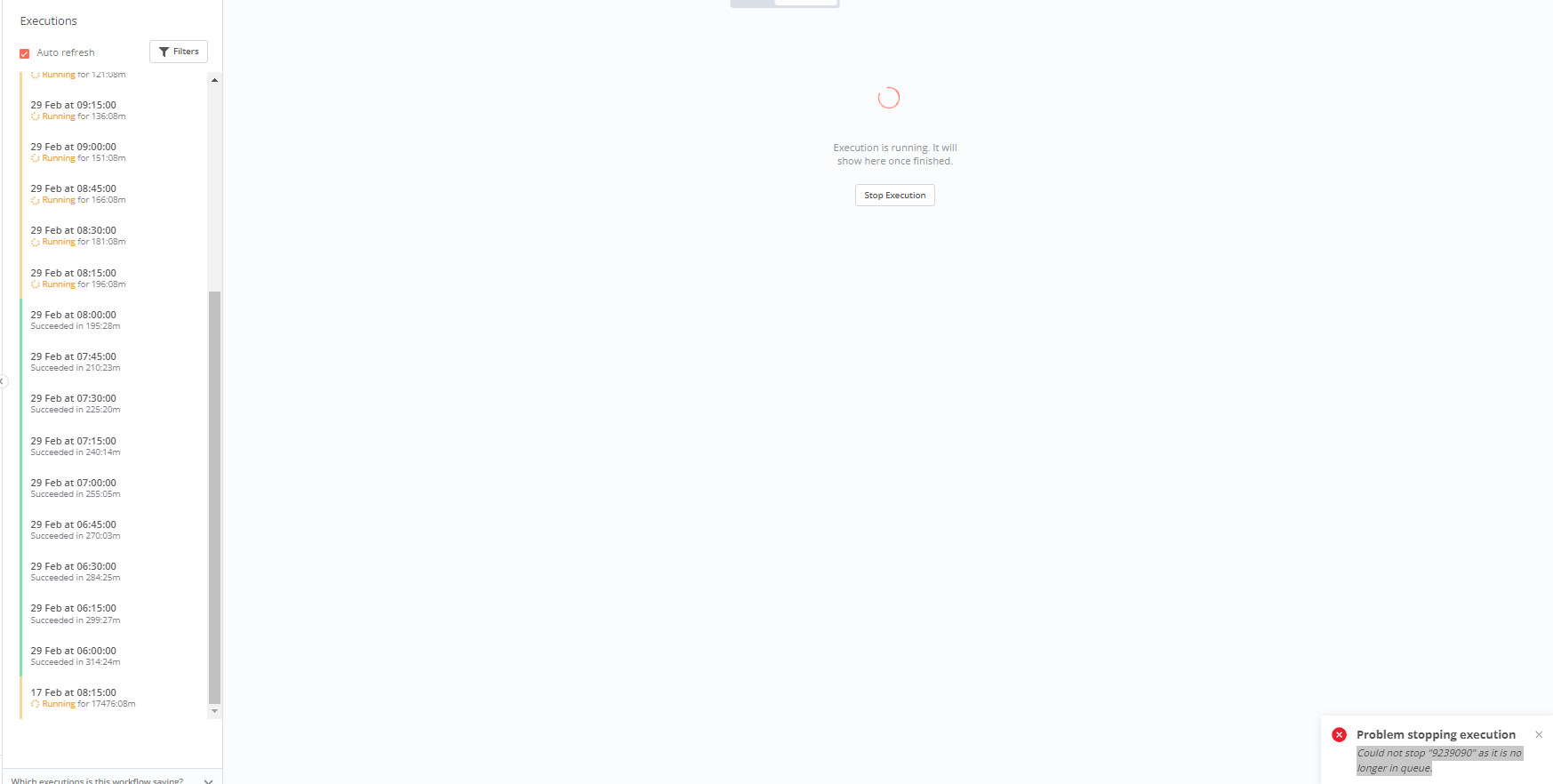
on n8n web UI we saw too many executions are running since two week ago. We wanted to stop the executions but we couldnt stop. The error message is “could not stop as it is no longer in queue”
We have changed state of this executionId to failed by modifying execution_entity table in database. Now executions became failed on n8n web UI. We wonder the root cause of this problem.
What is the error message (if any)?
The error message is “could not stop as it is no longer in queue”
Please share your workflow
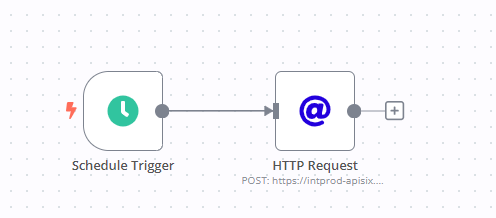
(Select the nodes on your canvas and use the keyboard shortcuts CMD+C/CTRL+C and CMD+V/CTRL+V to copy and paste the workflow.)
Share the output returned by the last node
Information on your n8n setup
- **n8n version:n8nio/n8n:1.12.2
- **Database (default: SQLite):postgresql
- **n8n EXECUTIONS_PROCESS setting (default: own, main):default
- **Running n8n via (Docker, npm, n8n cloud, desktop app):openshift
- **Operating system:openshift 4.12