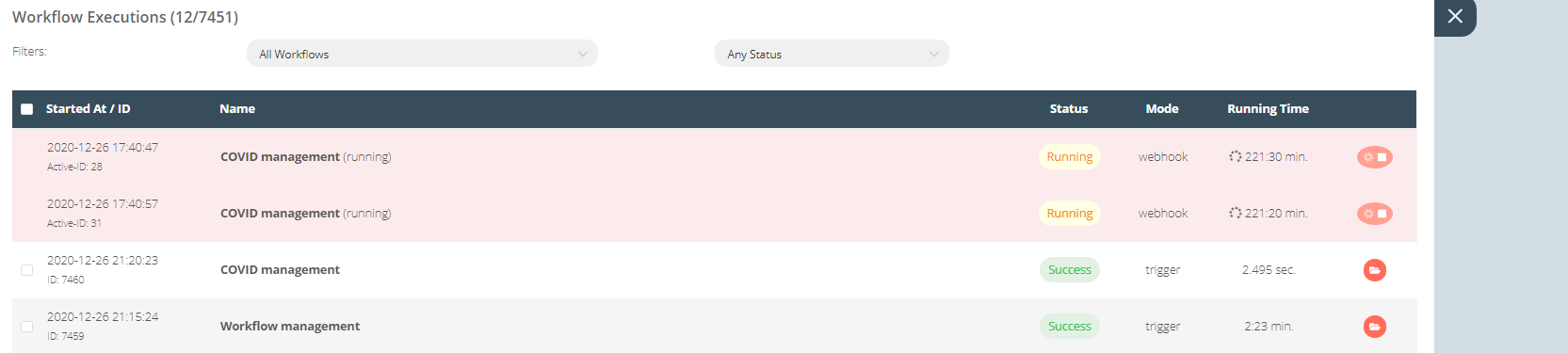
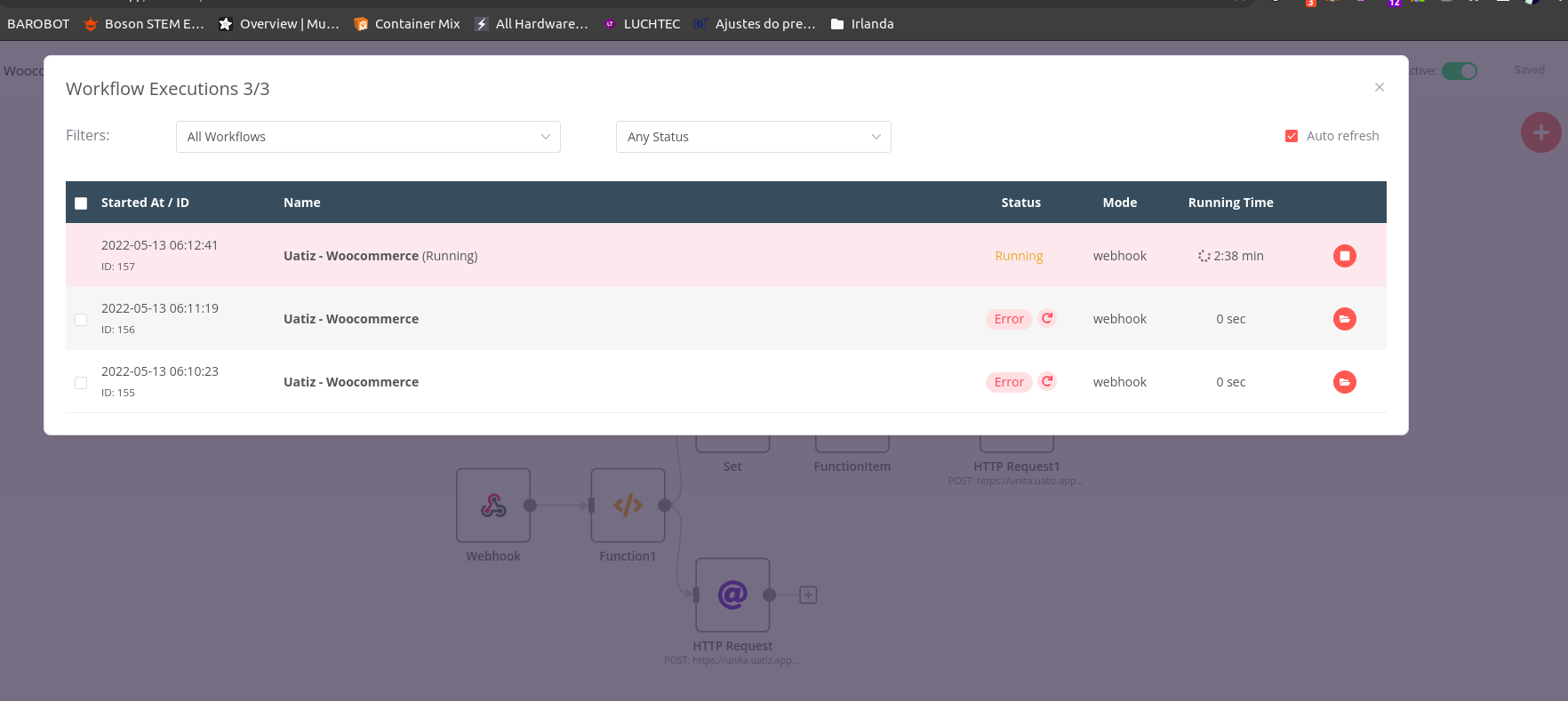
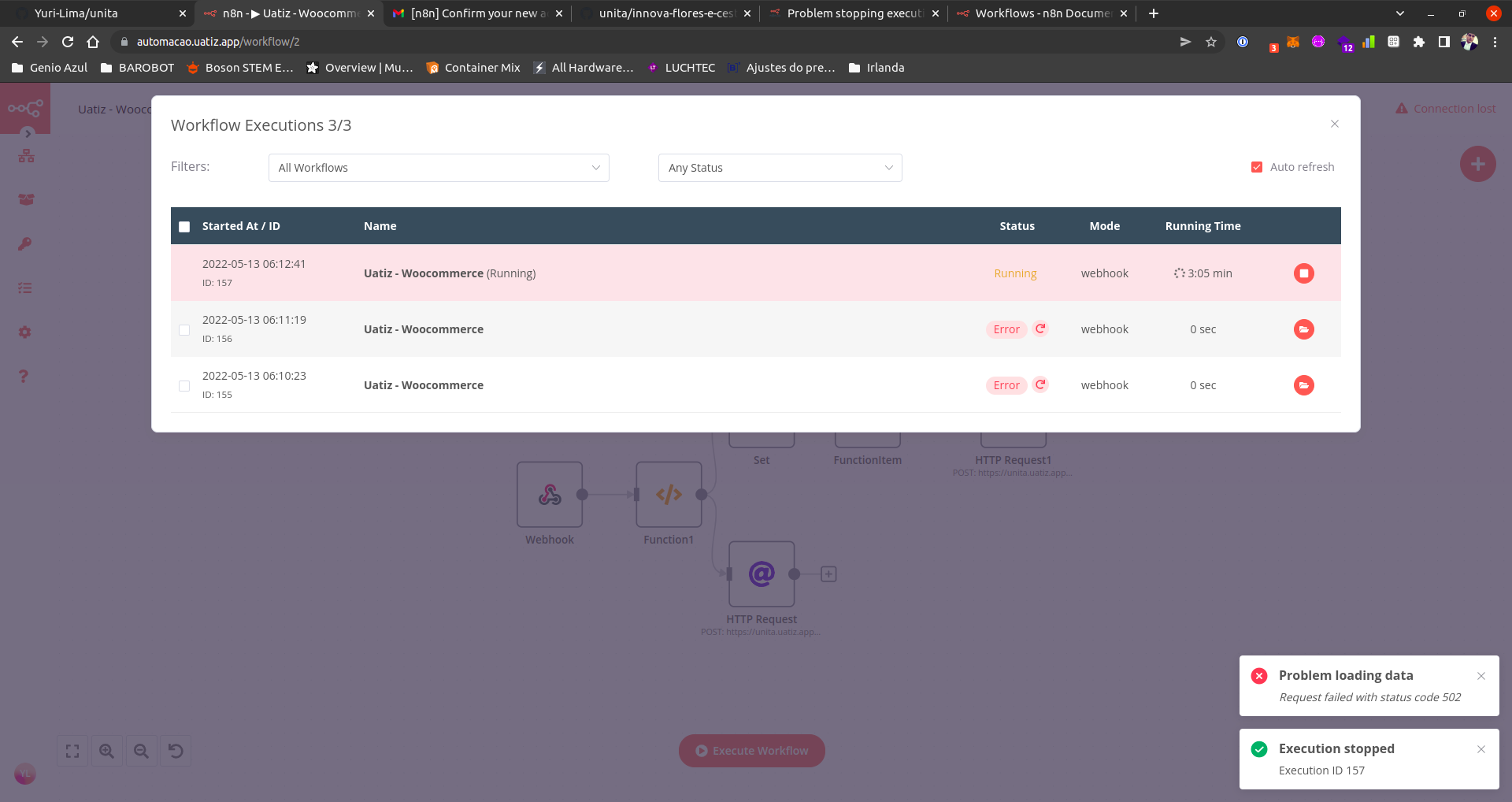
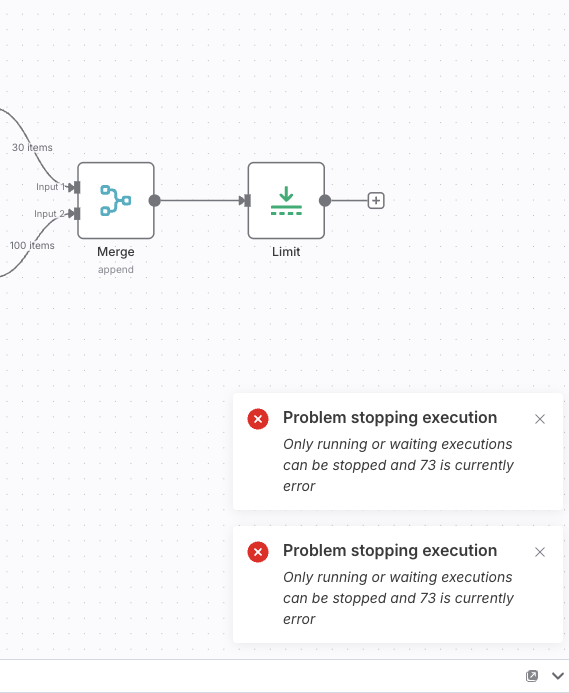
When I am trying to execute the following workflow step by step (by clicking on the play button for each step), I am unable to stop it. It seems the error arises from the fact that the HTTP request returns an error 463 and when the “Function” tries to parse the output of the “HTTP request” output, it fails. However, when I am trying to stop the workflow, I am getting the following error: “this.activeExecutions[executionId].workflowExecution.cancel is not a function” (see attached image).
I also installed N8N on Digital Ocean and experience the same problem with longer “SplitinBatches” Loops. The workflow hung and when I want to stop it, it gives the " Problem stopping execution" error message.
I think it can be reproduced like this:
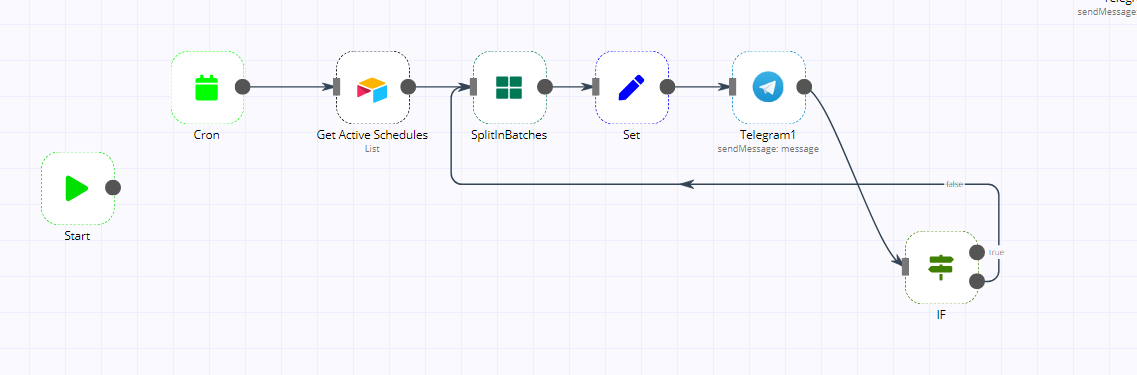
Make a “Google Sheet” with a column with a few thousand items and loop through it with “SplitinBatches”. In my case I used a batch size of 10 and experienced the freeze after 58 rounds.It also looks like the loop is slowing down the longer it runs.
I think it could be a performance or technical Issue with Digital Ocean or a bug in the Node. I hope this information helps to find a solution for that.
n8n did not get created to process huge amounts of data. It has simply the wrong design for it as literally all data from the execution stays in the memory until the workflow stops.
So if big amounts of data gets loaded at some point will the workflow execution take up so much data that n8n crashes. That crash can happen while it executes or also at the end, when the execution should get saved. So it is possible that every node executes perfectly but n8n is configured to save successful executions and it crashes then. The reason for that is that saving the data to the database will more than double the required memory for a short amount of time (for example to stringify the data).
Another thing that also increases the required memory, is running workflows manually. Because also then does the data has to get copied (to send it to the browser).
If you want to process larger amounts of data you have to design the workflows in a certain way. Best to have a main-workflow which takes care of the scheduling and a sub-workflow which does the actual work. The main workflow can then for example simply send in the sub-workflows the IDs of items that should be processed, or start & end index. The sub-workflow would then depending on that data load only the required data and do the actual work. It is however important that that the sub-workflow does not return a lot of data (best almost nothing). After all does the data of the last node get send back to the main-workflow and we would so end up again where we started. So best to have a Set-Node there which overwrites all data.
Also make sure to use the latest n8n version. Earlier versions used different execution IDs (so after a crash the ID was unknown) or had a few bugs after we changed that behaviour. The latest version should handle that better.
thanks Jan, I’ll try to digest it, independently of your suggestion I actually set it to the latest safe version now (which I already had before the crash several weeks back).
The latest version should be much better than any of the versions the last week’s. So hope it helps. If you still have problems and they are not crash related please report back that we can try to fix. Thanks!
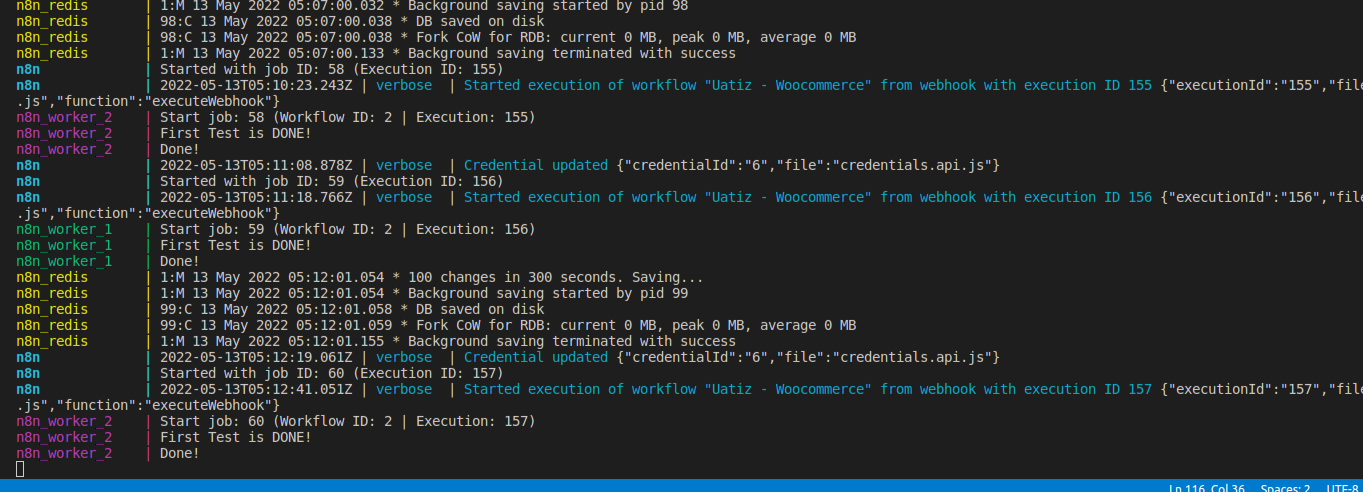
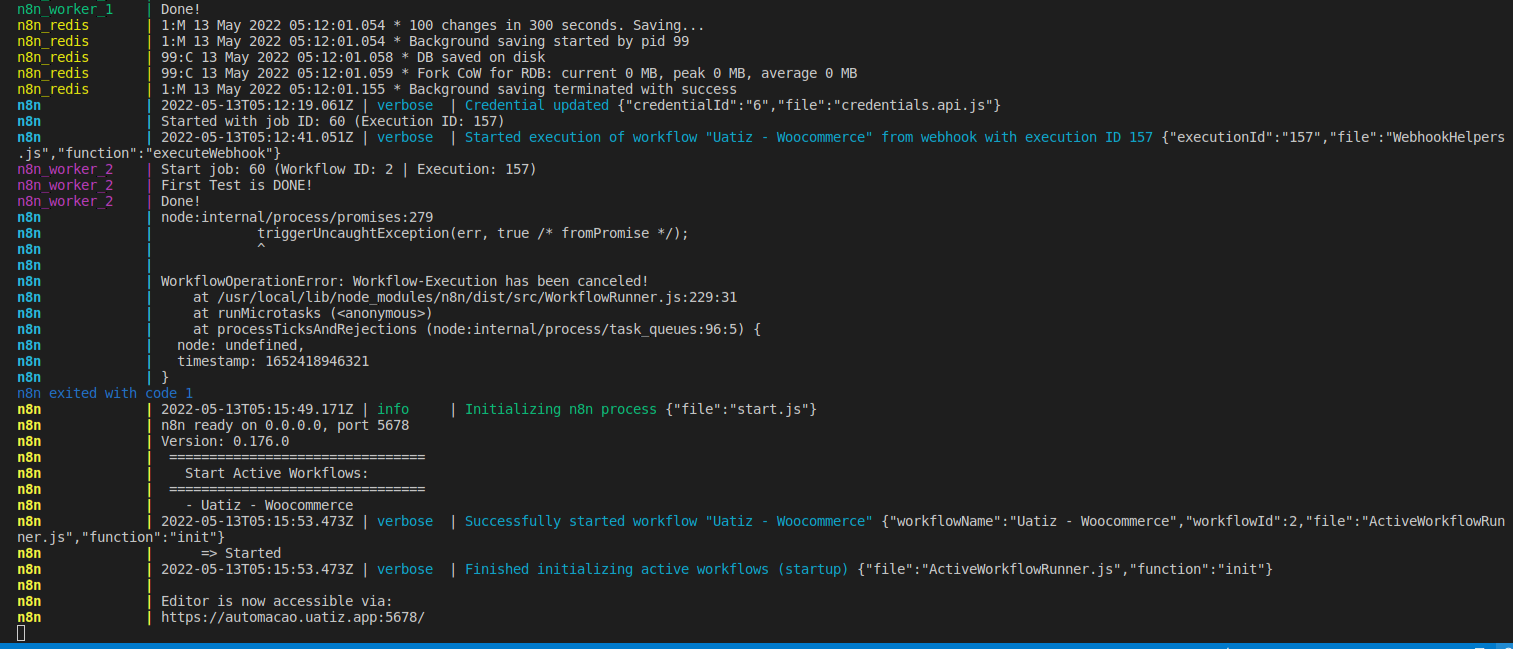
5. This pic above is the Docker-compose logs, we have the main process and 2 workers, as you can see we got an uncaught exception from the Promise the famous (try cath may did not used) so it shows that workflow was canceled, however, when we click on the execution button it shows that workflow keeps running.
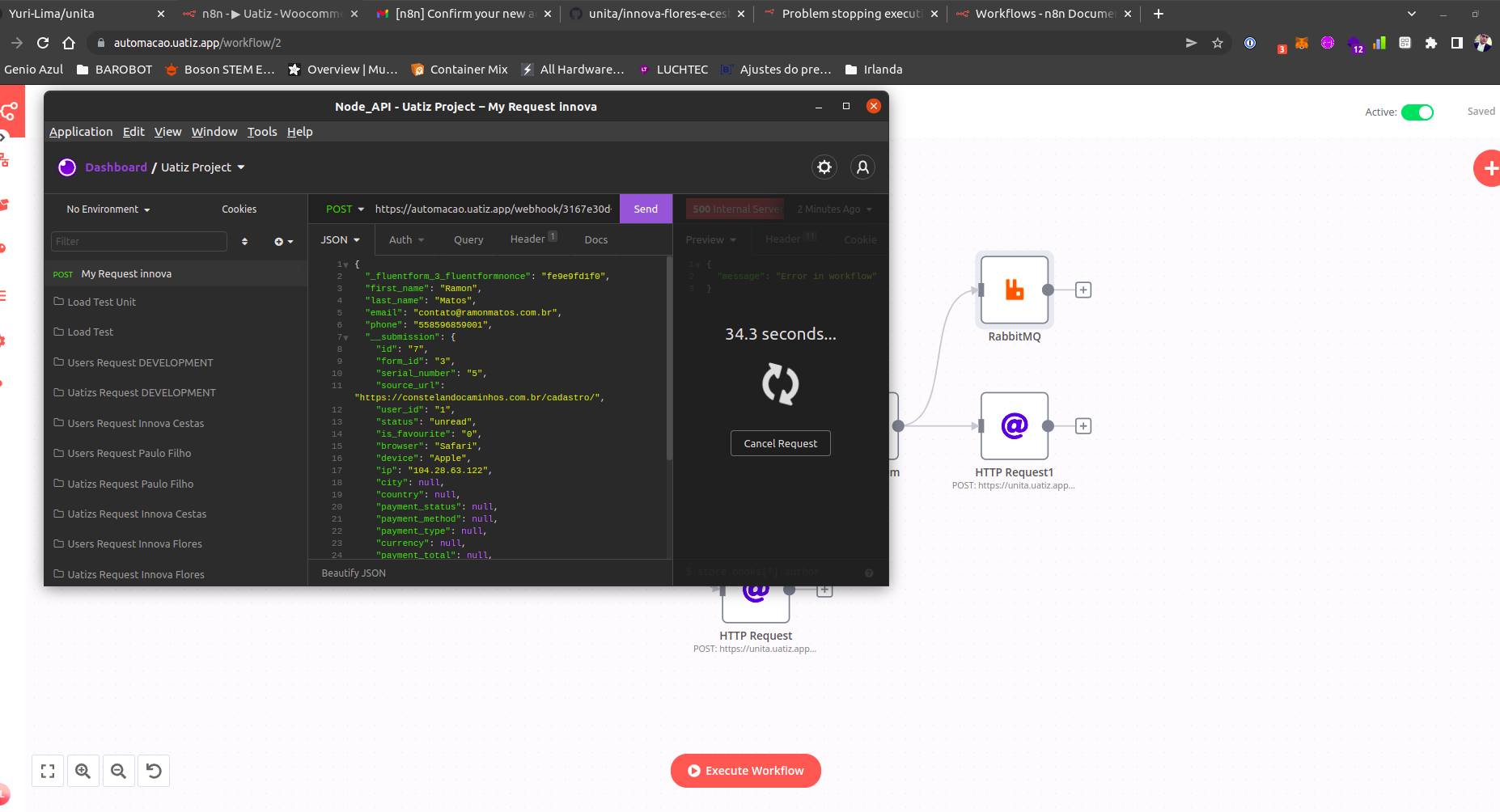
All data node is below here, just keep in mind that, the main source of the problem was adding the Rabbitmq Node to publish data in an exchange route key.