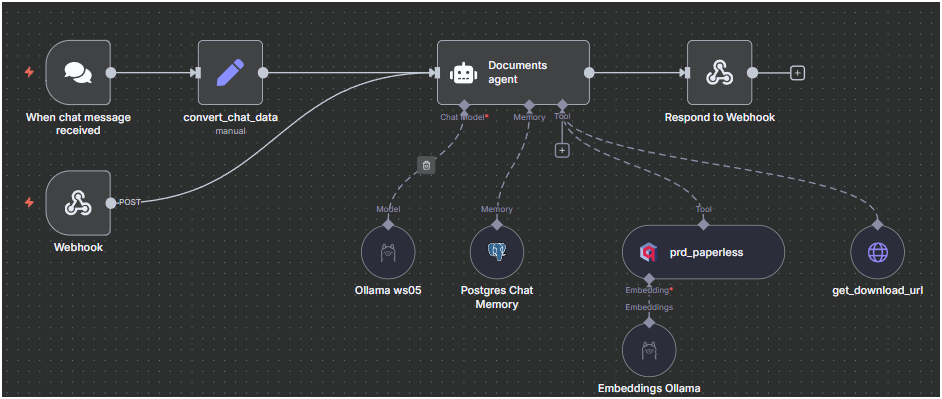
Hello everyone!
I’m building a Retrieval-Augmented Generation (RAG) agent in n8n using the Qdrant Vector Store node, and I’m encountering an issue with Hybrid Search that persists across different LLMs (Gemini, etc.).
The knowledge base consists of documents sourced from Paperless-ngx. The Qdrant collection is fully structured for hybrid retrieval:
- Vectors: Document text content is chunked and embedded.
- Metadata (Payload): The metadata is rich, containing Paperless-ngx fields like tags, document type (_doc_document_type), correspondent, storage path, etc.
- Indexing: Payload indexes have been successfully created on all key metadata fields. The collection integrity is verified.
The Symptom (Filter Failure)
When a user asks a query that requires a metadata filter, the LLM consistently performs a wide semantic search and ignores the filter instruction.
Asking, “List documents where the document type is ‘invoices’.”, the agent retrieves a large set of semantically relevant chunks (limited only by topK), rather than precisely filtering the result set down to only documents of type ‘invoices’.
Question
Is this behavior normal for the current n8n retrival node, or am I missing a configuration?
Hybrid search is a part of the retrival node and it’s only a prompt issue or I miss something?
Sorry in advance in case of stupid questions ![]()
Thank you for the support