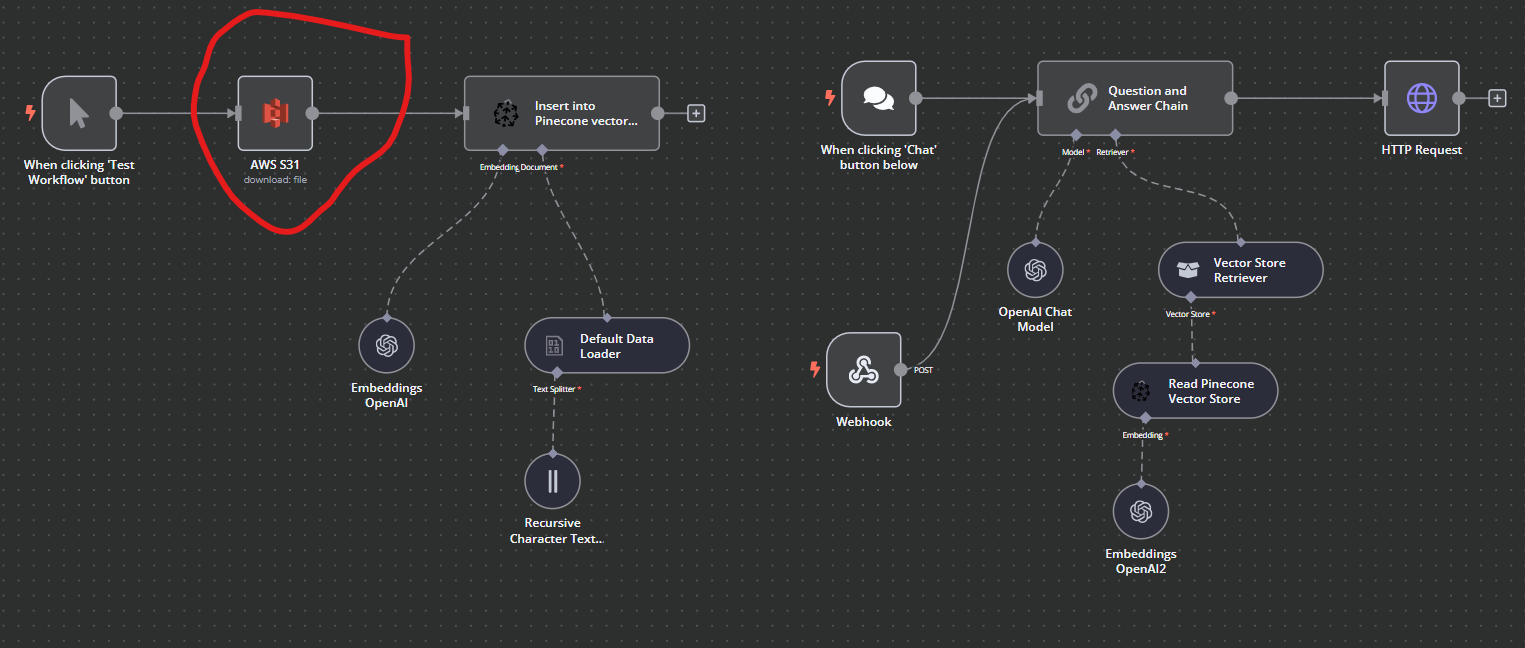
I am hosting n8n on a vps and have set up the standard rag flow, using embeddings and a pinecone vector store.
Content is PDFS, held in an AWS S3 bucket. The challenge I face is being able to download and insert say, 100 PDFs into the vector database. I have no problem getting one but for many, perhaps I need a javascript node?
If anyone has figured this out, whether Gdrive, Onedrive, S3, it’d be a tremendous help!
Hi there, thanks! I need to know how to set up and configure the cloud storage so it downloads many or loops through files in my S3 bucket and inserts into Pinecone pls: