I am trying to extract information from http request node but the error of exceeding max token keeps coming. I have tried to set the parameter to maximum token allowed, but it still is not working. Please help. TIA
1 Like
Hi @Affaaf
How much information are you sending into the model? The limit only applies to the output tokens, it won’t truncate the input?
Do you have a workflow you can share?
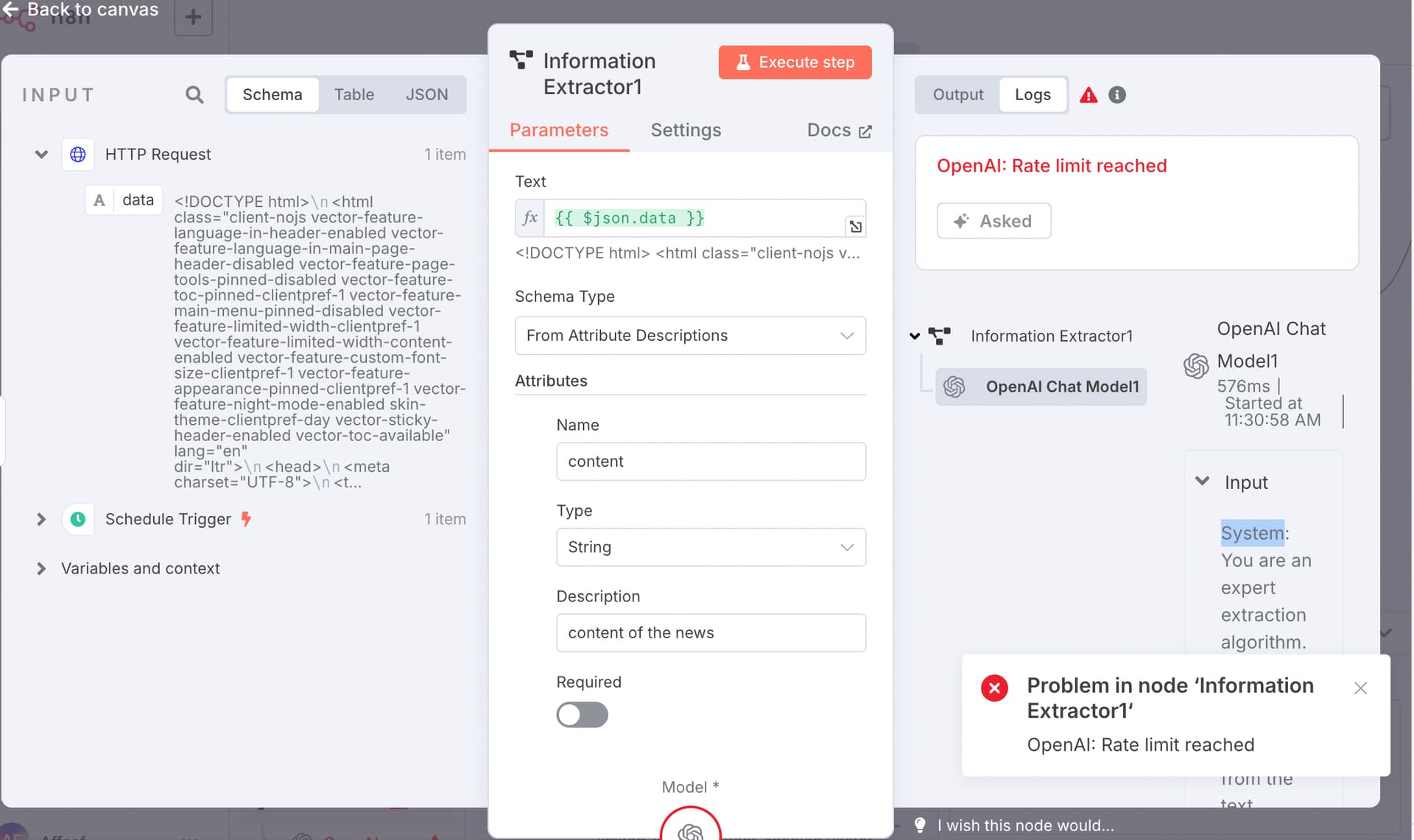
That page has a lot of content to send to an llm. What are you trying to do with the content? I’ll check if there is a model that can take in that much content.
1 Like
try either the html node to convert the payload from the http request to plain text or use the markdown node to convert html to markdown. This will reduce your token size significantly.
2 Likes
I connected to the site and found that chunking your data, then sending it through multiple agents is the best way to go. I’ll include the code for chunking below.
Even chunking your text into chunks of 3k size results in 197 results. You can summarize each of the 197 results, then summarize the results of those. The llm will run a total of 198 times.
Again, your content is gigantic. What are you attempting to accomplish with the summarization?
const text = $json[“text”]; // your long input string
const chunkSize = 3000; // characters per chunk
const overlap = 300; // overlap between chunks
let chunks = ;
for (let i = 0; i < text.length; i += chunkSize - overlap) {
const chunk = text.slice(i, i + chunkSize);
chunks.push({ json: { chunk } });
}
return chunks;
1 Like
I want to get the salient feature of the content. I guess I should be using a different attribute?
The code you have mentioned, where should I enter it?
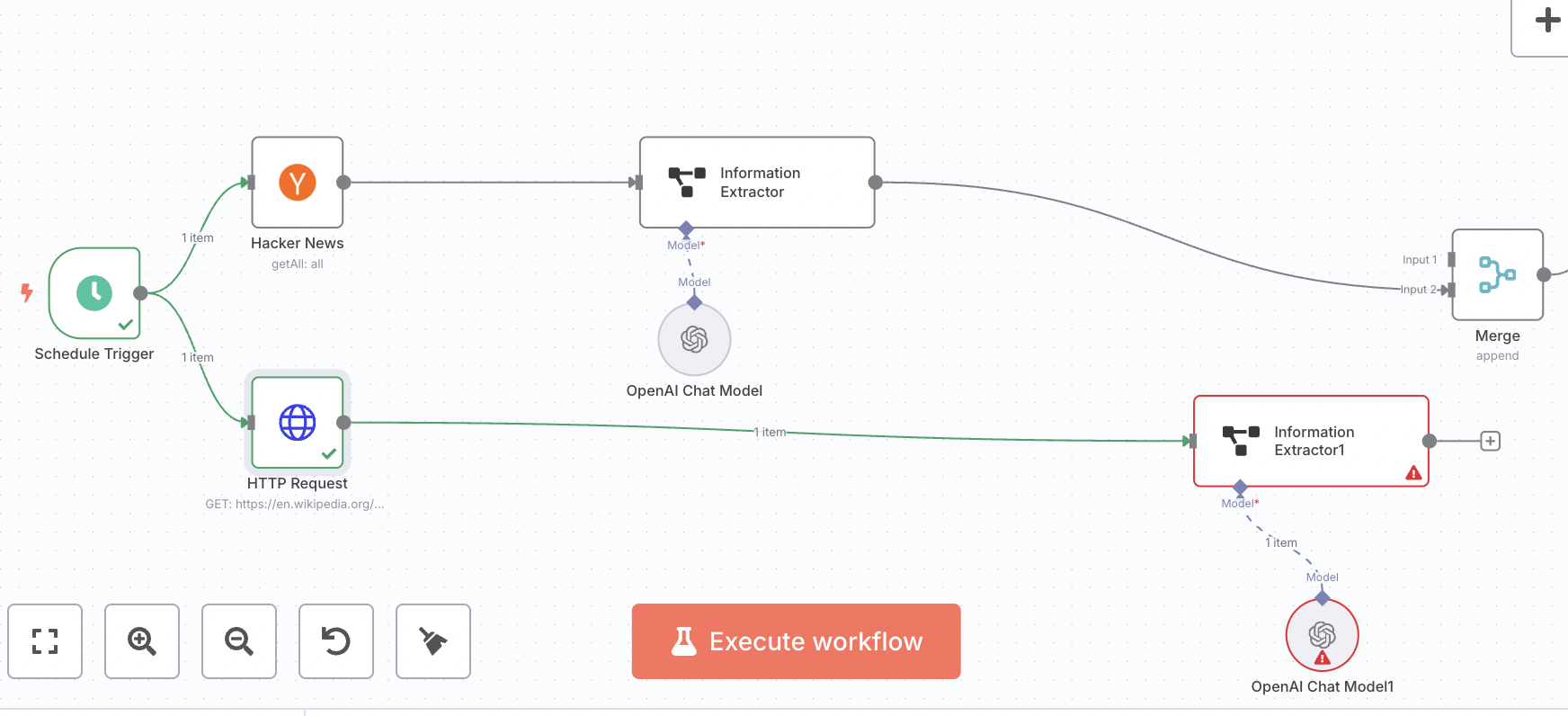
Basically what I am trying to do is get news from both news source (hacker news and any other website that delivers news) and then the news on the same topic from different sources, I want to upload it in a document. Right now I am just testing my logic. I am very new to n8n (started this month) so still trying to understand everything.
1 Like
wow… thank you. I was able to resolve the rate issue by using html node. Is there a limit of token on which this will work?
1 Like
Well depends on your model, gemini has a pretty large token context window.
1 Like
You are using OpenAI so let’s find some information about it

Use 4o-mini as example.
Tier 1 and Tier 2 has very different limit :
RPM : Request per minute
RPD : Request per day
TPM : Token per minute
I believe you hit RPM or TPM quite often if you are in Tier1
Because sending the whole html to AI is causing some amount of the tokens.
You can follow the document to check what tier you are and considering upgrade it by deposit more credits.
https://platform.openai.com/docs/guides/rate-limits#usage-tiers
Or not sending the whole html to AI. Find some other way to minimize the tokens
1 Like
Glad you found a model that could use that much text. Are you trying to have people ask questions of the documents? To find more info?
An Agent may not be very useful with that much content. You could also move your data into a vector store in smaller chunks, and have the agent use the document’s data.
Let me know if you are looking for a solution like that.
Best,
Robert
I am trying to compile news about same topic from different sources. I then want to send them in a google doc. Initially I was thinking of extracting news from different news website and then merge the news that are similar but that is not working out so I am going to change my approach and now get news from one source and then get matching news from different http request nodes and see how that goes.
Like I said I am very new to n8n and am still understanding the functionality. I will look into the vector store and what is that. Right now I have gotten stuck with credential for google doc. Have you ever tried them?
1 Like
Are you looking to summarize content from multiple sources, then send out a google doc?
What error are you getting?
yes that is waht I am doing. I have managed to do so. Now I just need to put the similar news together under one big heading. Any idea, how to do so? I tried the sql query in the merge node but it didnt work since the data coming from different sources had different wordings despite talking about the same topic
1 Like
Hi @Affaaf
Try sending both outputs into an ai agent. Use a system message to say something like…
“Combine these two summarizations into one clean document detailing the topic”
![]() If this response helped you, please click the heart to show that it is useful
If this response helped you, please click the heart to show that it is useful
![]() If this response solved your issue, mark it as the solution to help the community
If this response solved your issue, mark it as the solution to help the community
1 Like
Let me know if you were able to solve your issue. Or if you need more help.
Actually I have not been. I am trying another approach and will tell you how it went. With AI agent, the agrent returns data in 1 item. I would prefer to get it into multiple items.
Another issue that I am seeing is that only one news is being extracted from the html node. I am trying ot understand why would it get only one news item when in the http node I see many links.
1 Like
Can you paste your workflow into a preformatted text block so I can see you html node?
here is the json file.
Let me know if it is helpful. I am still workign on it so it is full of errors but you can see the http and html nodes and their content. I am able to extract multiple articles I think. But some of the information is not in the form I want. I don’t want the links in the output. Just the news from those links. Which I am still working on how to extract. Any idea?