Hello everyone!
i’m new using the n8n but already loved it…someone can help me with technique tips?
I read the n8n documentation and analyzed some examples and i know that is possible with n8n using “Read Binary File”, " Spreadsheet" and some node functions…
Roadmap:
- Open .txt
- Read one row per time
- Catch value on specific position of row
- Save to postgreSQL
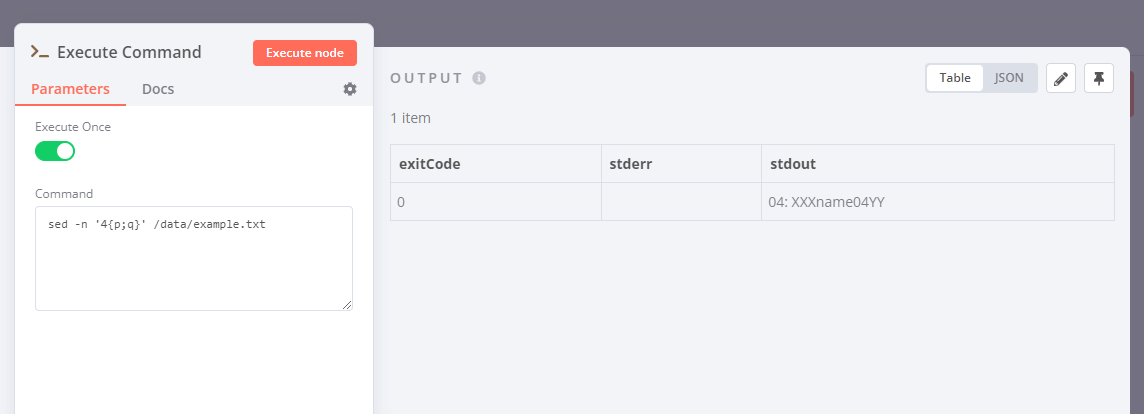
.txt structure example:
01: XXXname01YY
02: XXXname02YY
03: XXXname03YY
04: XXXname04YY
the value that i need catch is:
- Position: 04
- Size: 06
But my question is, what is the best way to do it when i have 5 millions of row to be read and sliced the value, for example: the n8n workflow must read “line 01” and catch the data position at 04 and the next 06 characters (result: name01) to save in PostgreSQL and continue the execution…
Thanks in advance!