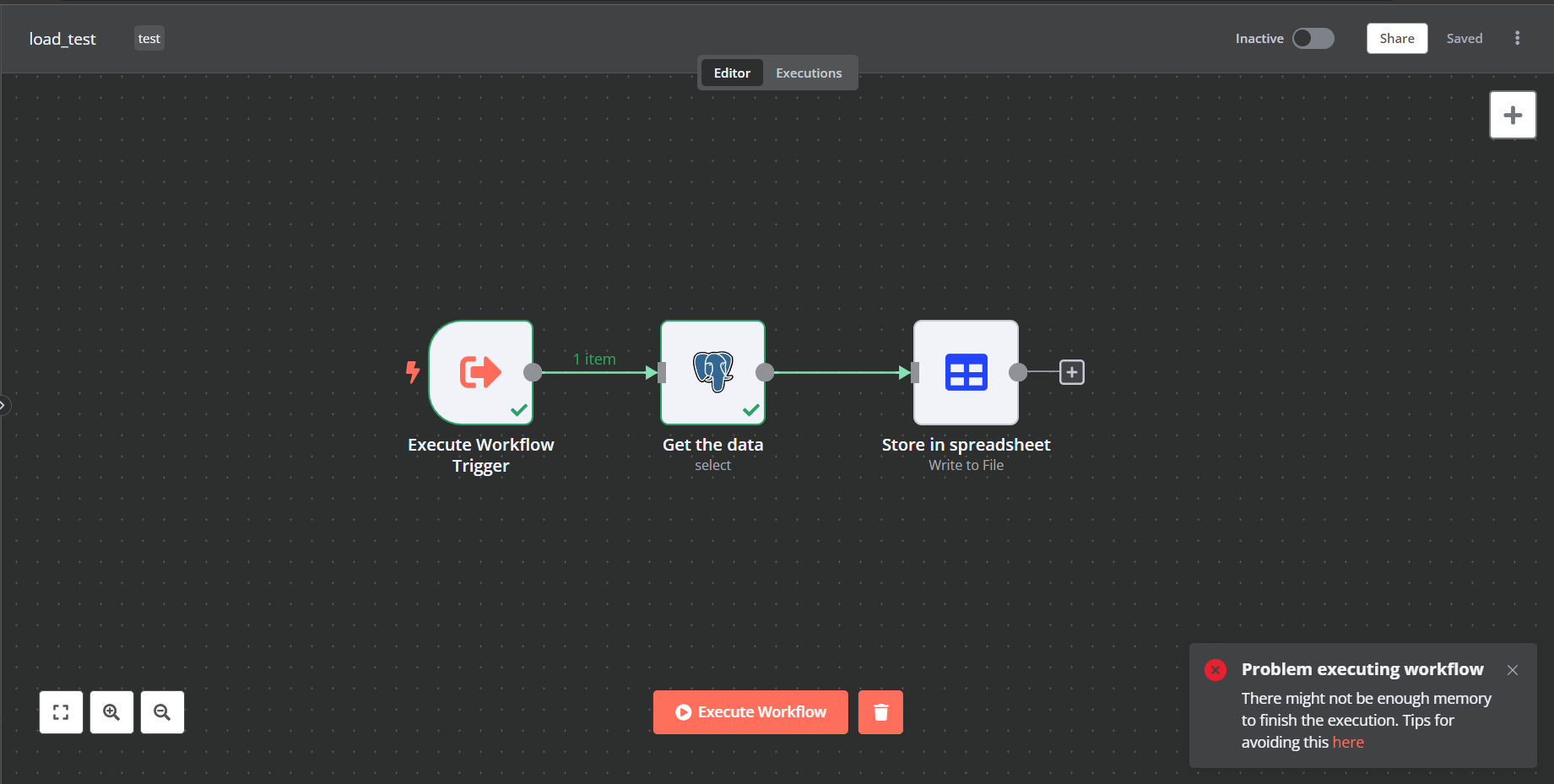
I am trying to retrieve data from a PostgreSQL table and insert it into a CSV file and then push the file to S3 bucket. The table has around 170,000 rows and should be around 40MB. But when I run the workflow it gives me an out of memory error. If I disable the Spreadsheet node and run the workflow I am still getting the same error.
I tried to call this workflow from a separate parent workflow as well but with no luck. Any help would be appreciated.
At 170,000 records I suspect you are hitting the memory limit for your cloud plan, I don’t think we have a way to append to a spreadsheet either so working around this could be tricky.
Thanks @Jon - the file is a csv/text file. Does another node support appending data to a flat file? Even though the job processes 170k rows of data, the data is relatively lightweight (40-80mb total). It doesn’t seem that this would or should cause any type of memory issues even if the dataset is processed in a single batch.
We are also encountering the same out of memory issues in a self-hosted instance of the community version. Using a t3.large instance in AWS (2 vCPUs, 8GB RAM), a similar job with a total data size of around 150mb errors out for memory-related issues.
We have followed the guidance here (Memory-related errors | n8n Docs), but without much success. Are there other recommendations related to either workflow design or resource provisioning that we should follow? Does upgrading the cloud subscription to the Pro tier provide access to more compute resources? Thanks.
It is important to note that while the 170k rows of data might only be 40-80mb when written to disk there are a number of things that happen in n8n in memory to format the data and convert it to the data format we use internally which will consume memory.
If you can share your cloud username I can take a quick look at the logs for your instance to confirm if this is a case of the memory running out. The way I would handle this is to read the data from the database in smaller chunks and create multitple spreadsheet files or add them to something like a google sheet then download that as a CSV file using the Google Drive node.