It might not be running out of memory and it could be something else, The error message you see is fairly generic and indicates that n8n has crashed the most likely cause is normally memory.
Does the docker log file show a memory issue? Are you also able to share the complete worklfow and sample file so we can take a look at what you are doing?
Hey @Jon , sending you the actual data with a simplified workflow via DM.
The docker log was initially showing a ‘javascript heap out of memory’ error, but since then, i adjusted the container and n8n config to accommodate for that (as given in the docker run command above).
Subsequently, no error is actually being shown in the docker log.
If you can share it in the post it might be easier as there are a few of us on the team and I may not be the one that ends up looking into this
It sounds like it has moved from a memory issue then to maybe something else, Don’t forge the code node needs to set up a new sandbox for each item depending on what you are doing which can consume more resources so it could be that the best solution is to use a sub worklfow and break down your items into chunks.
Maybe even look into queue mode and having multiple workers as well so you can make the most of the resources you have available.
Currently, the ‘Code1’ node, where items retrieved from a binary (txt) file are being formatted and separated for batching/load division, is the one that’s failing (hanging, along with the n8n instance in general).
Would love to know how to simply this further!
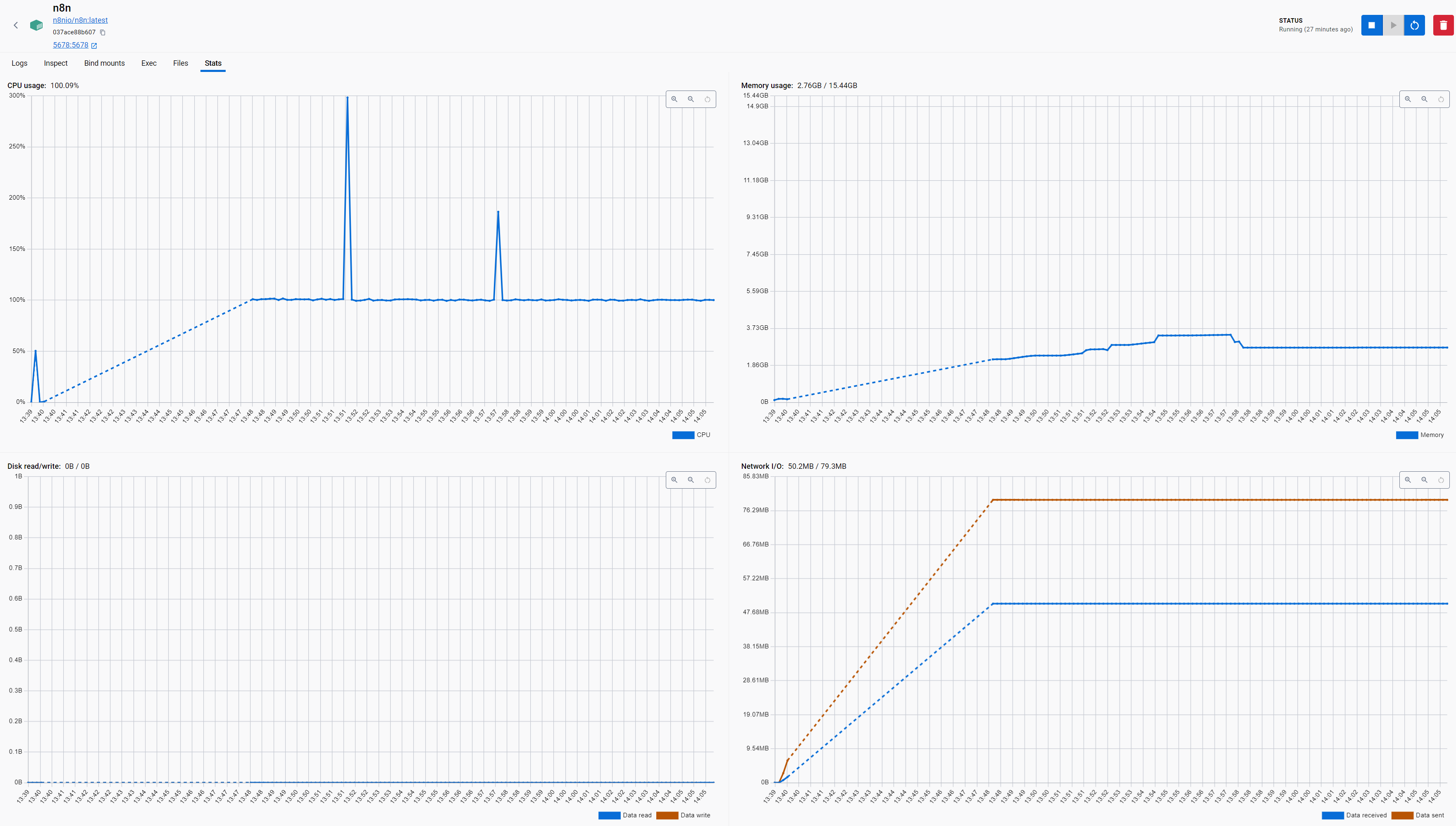
The following charts are for an approximate duration of 25 mins. since this workflow execution was started (no other workflow is being executed during this time):
So that Binary file if I download the file from Binary to JSON crashes a text editor on my local machine so I am not surprised that n8n is having a hard time with it.
What I would do is write the file to disk then read the data in chunks to process it maybe using the csv-parse package we ship with as well to take care of some of the heavy lifting.