Hello, good morning. I am in the learning phase, conducting tests with the tool, and I noticed that all executions or logs, I’m not sure which, are saved inside the container. I saw in the documentation that there are some environment variables; I tested some, but it didn’t work. Here is the list of variables I tried to use:
Not sure if I understand correctly.
But if you are talking about the executions of workflows, then they are in the database.
If you setup the postgresql connection then the executions like workflows will be in the database. So this could be external, where ever you put that database.
My workflow runs for a long time and involves multiple loops. Because of this, several files are being saved inside the Docker container as if they were execution logs. This is filling up the memory of the server where the Docker container is located, right?
I believe these files are execution logs, and I would like them not to be saved inside the container to avoid occupying disk space.
This doesn’t ring a bell for me.
Executions logs are not stored as files they are only in the database postgres or sqlite.
Maybe it is the docker logs, but I don’t know why this would fill the disk. What logging level do you have set for n8n container?
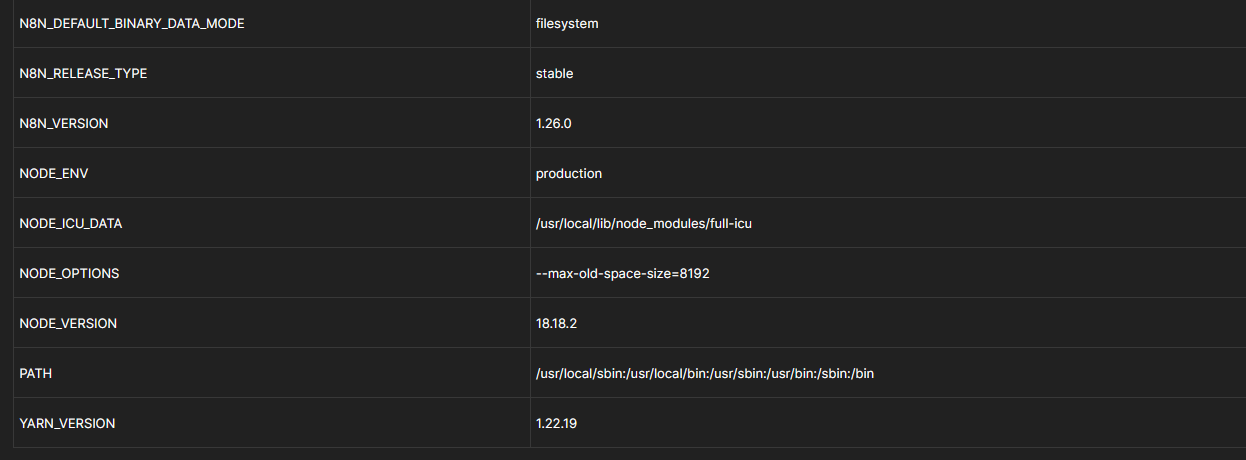
The logging level should be listed here if you changed it. But it isnt.
What I do see is the Binary data mode which you set to filesystem. This means that all binary data that are processed in the flows are written to the filesystem, so this is probably what you are seeing.
Are you processing lots of files?
When extracting the file without the variable, it returns the error I mentioned above,
And with the variable, it can extract, but it runs into the issue I mentioned, filling up the disk with many files.
Ok so this runs a very long time for lots of files?
As long as this flow is running it will keep the files so you are probably messing it up that way.
It would help splitting it up with a queue to make sure the workflow isnt constantly running and retaining the files. As I think they are deleted after the flow was completed.
Ps. Please do not tag me a second time if I do not reply directly. This makes me not want to help you any further…
You can send the data for the files like filename or url to a queue like RabbitMQ and then have a workflow be triggered by that queue. Make sure to edit the parallel processing option. There should be a few examples on the forum on this.
it is fine to mention just not a second time like this: