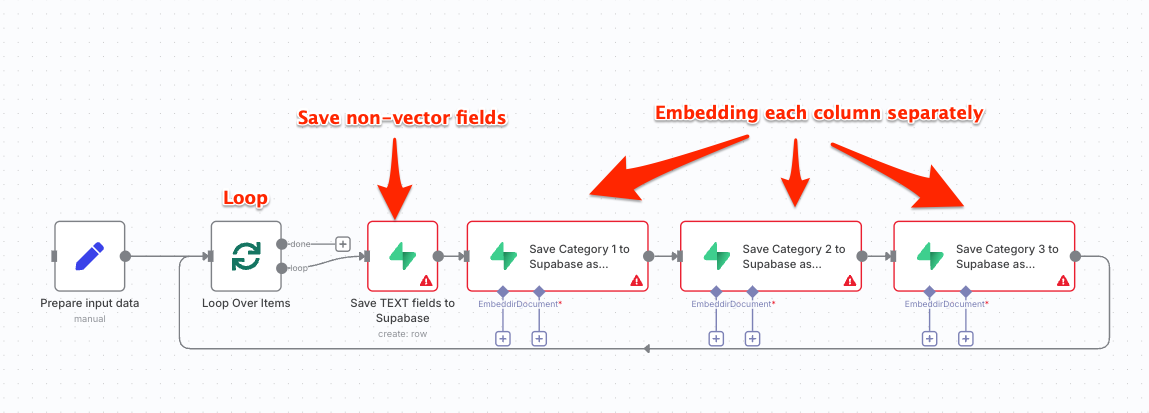
You’re on the right track, Zohar - saving both raw text and its vector representation is a solid pattern, especially when you want traceability or future metadata-based filtering alongside similarity search.
Best Practices for Your Setup:
 1. Store Clear Text and Vectors in the Same Table
1. Store Clear Text and Vectors in the Same Table
Yes, you can absolutely store the text fields (category_1, category_2, etc.) as TEXT columns and their embeddings in dedicated VECTOR columns in the same Supabase table - that’s a common hybrid RAG approach.
Your schema might look like this:
CREATE TABLE categories (
id uuid PRIMARY KEY,
page_id TEXT,
url TEXT,
execution_id TEXT,
timestamp TIMESTAMPTZ,
category_1 TEXT,
category_1_vector VECTOR(1536),
category_2 TEXT,
category_2_vector VECTOR(1536),
category_3 TEXT,
category_3_vector VECTOR(1536)
);
 2. Embedding: One Node per Category Field
2. Embedding: One Node per Category Field
If you’re using an embedding model (like OpenAI, Cohere, etc.) inside n8n or Make:
- You do need a separate call per field unless you’re batching them (and can later map results properly).
- Many APIs let you send multiple strings at once, but the response is typically an array — make sure you’re aligning output correctly (e.g.
response[0] → category_1_vector).
So you can:
- Use a loop (or series of API calls) if you’re going sequential
- Or use a batch call + mapping logic if your platform allows that cleanly
 3. Supabase Write: Single Node or Split
3. Supabase Write: Single Node or Split
If you’re inserting/upserting everything at once and all values are already computed (text + embeddings), one Supabase node is fine. Just construct the full payload.
But if you’re embedding fields asynchronously (e.g., spaced across nodes or delayed), you may need:
- A staging object to collect data
- Or a multi-step flow where the final node writes the full record
Let me know if you want to see a visual (like an n8n workflow or SQL example). Also happy to share how we do this internally at Hashlogics for RAG apps that use hybrid filtering and vector search in Supabase.
Feel free to connect: Calendly