I am facing downtime issues with n8n. I have implemented n8n queue mode. I have checked the metrices i.e CPU utilization and memory utilization of containers is not more than 20%. Is there any way to scale up n8n master nodes or reduce downtime? Any help will be appreciated. Thanks
Hi @sulabhsuneja, what exactly do you mean by downtime issues? Does your main n8n instance crash or something? If so, which error exactly are you seeing?
There is no supported scenario for having multiple main instance I am afraid. The idea would be to have one main instance and multiple workers.
Hi @MutedJam
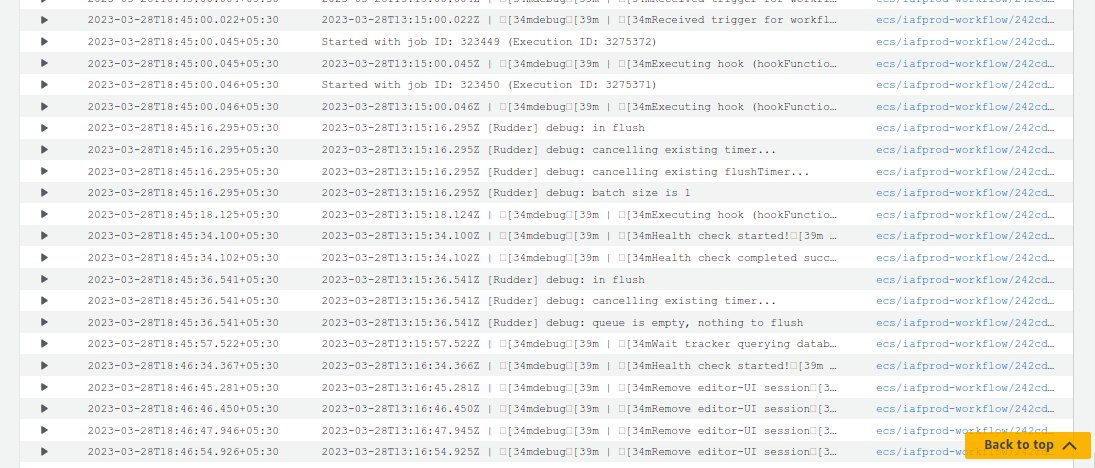
Yes, main n8n instance gets crashed. I have attached a screenshot of the Cloudwatch logs above. I am not able to find any error statement. It just gives 502 error. I am assuming it is not able to connect with RDS server during that time but I am not sure of the reason behind this issue.
The logs you have shared don’t suggest a crash I am afraid. Even without any error you’d see the instance restarting in such cases, meaning there’d be log lines such as n8n ready on 0.0.0.0, port 5678. Perhaps you can search for these and investigate the log entries just before? These should give you an indicator as to what might be happening here.
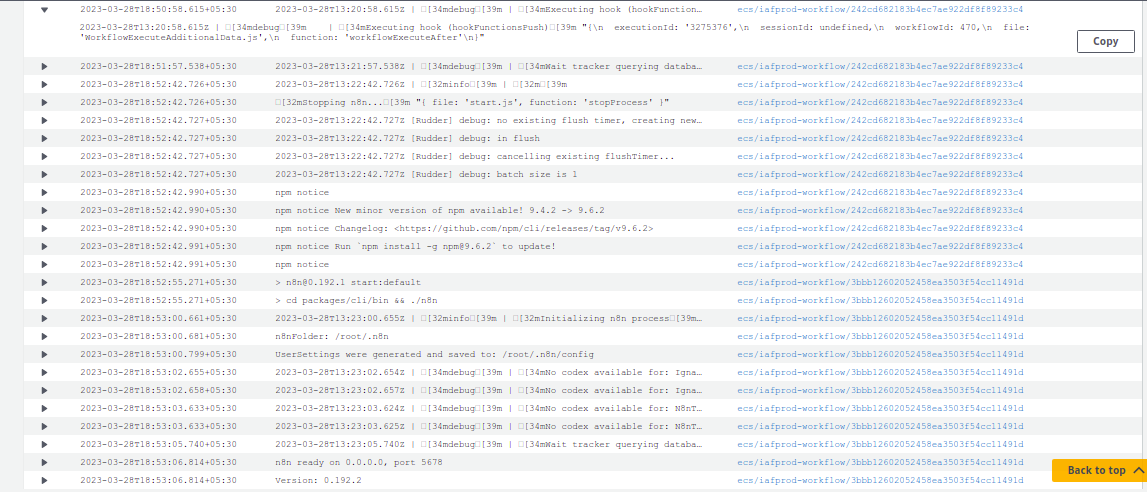
Here in the below attached logs screenshot, I am able to see logs of “Stopping n8n…” and n8n getting restarted but not able to figure out if the workflow i.e (workflow ID: 470) listed is the one causing crash of main instance.
Thanks for sharing @sulabhsuneja! The Stopping n8n… line suggests an intentional graceful stop rather than a crash. So this would suggest that something in your environment is sending a SIGTERM (or SIGINT) signal rather than n8n crashing, and you might want to investigate in that direction.
Thanks @MutedJam. I will start looking into environment configuration. Is there any way you can help in identifying SIGTERM or SIGINT signal? What could be the potential reasons behind this?
Unfortunately not, as I am not familiar with AWS. It might be worth checking with their support team directly. Is there perhaps some auto scaling at play (as in one container shutting down and a new one with additional resources starting instead or vice versa)?
Oh, Ok. Yes I have implemented autoscaling group for the ECS instances which run the docker containers. Usually, there is only one ECS instance on which only one master node is running in the container.