We have 2 instances of n8n setup on the same server: staging and prod. Many of our workflows fail between 0s and 0.003s when triggered by a schedule execution, but manual execution work correctly.
We cannot identify a common point between workflows having an issue, because they are all almost identical (an HTTP node to query an API, a code node to process the data, a Postgres node to store it in our DB), and because the workflows triggered automatically and working / triggering an error are not the same every day, but for some reason we see some trends (some of them work 80% of days, some do not 80% of days).
Refactoring some workflows into separate workflows that trigger each other did not help. There are no error messages, it just fails.
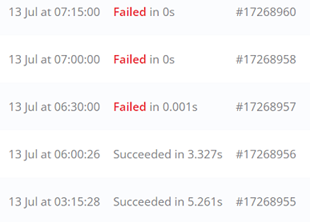
Additional info:
We have the exact same problem as this previous issue, but we checked and we do not have the same configuration issue that was at the origin of the case.
Even if the issue is present on both our instances, many more workflows are working properly on our production instance than our staging instance which fails almost 100% (they are the exact same workflows just plugged to staging datasources/credentials). Both prod and staging workflows all work fine when executed manually.
Information on your n8n setup
- n8n version: 0.221.2
- Database: PostgreSQL
- Execution mode: queue
-
Running n8n via:
PROD-instance: docker-compose
STAGING-instance: docker-compose
SHARED: Redis - Operating system: Ubuntu 18.04.5 LTS