I built an AI-Agent based decision workflow that auto-fixes incidents using Prometheus + n8n + bash scripts (based on what you defined).
The visualization of the flow:
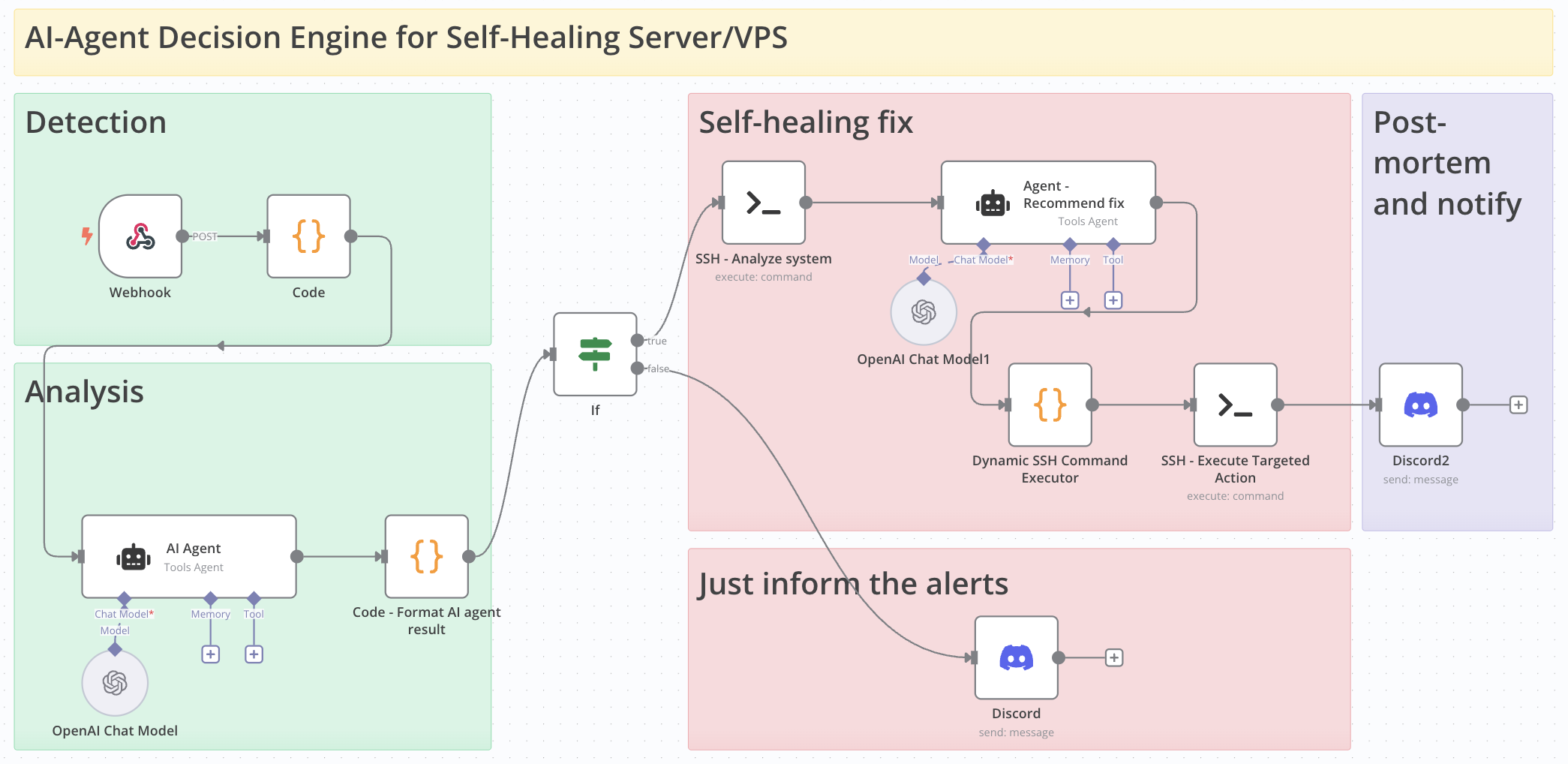
Overall how it works
- CPU spike or Disk almost full detected
- Analyzed the runaway process
- Try to reload core service and clean un-necessary logs
- Performance restored
- Inform, report and postmortem
N8n components I’m using:
- Prometheus - Grafana: For monitoring and metrics collection.
- Alertmanager: To send alerts, and n8n to orchestrate a workflow
- First bash script: To do a system check and analyze
- First AI-agent node: To analyze the result from the system check scripts. The agent will evaluate how to interact with the issues (just notify or take immediate action).
- If it’s medium and low cases, just send a notification to Discord. If it’s kind of urgent actions, go the critical flow
- Second AI-agent node (in critical flow): Analyzes the actual system state and creates specific fix commands. The commands could be clean logs, try to restart some services to release the resources.
- Second bash script: to run the commands under AI-agent suggestions.
- Finally, send some post-mortem and reports through Discord.
𝗟𝗶𝗺𝗶𝘁𝗮𝘁𝗶𝗼𝗻𝘀 and considerations of this flow:
- Non-deterministic AI behavior: We won’t know would it will constantly fix the issues
- Data privacy concerns: server data is sent to OpenAI to analyze
I’ve shared all materials in Github repo:
I hope this helps you to apply in your server or VPS, to help you self-fix your services just in case of an emergency. I would love to hear your feedback and collaboration to improve the flow.