Hi!
I’m working with long PDFs to extract text/scans into a data base but right now my problematic is that the PDFs are just too long.
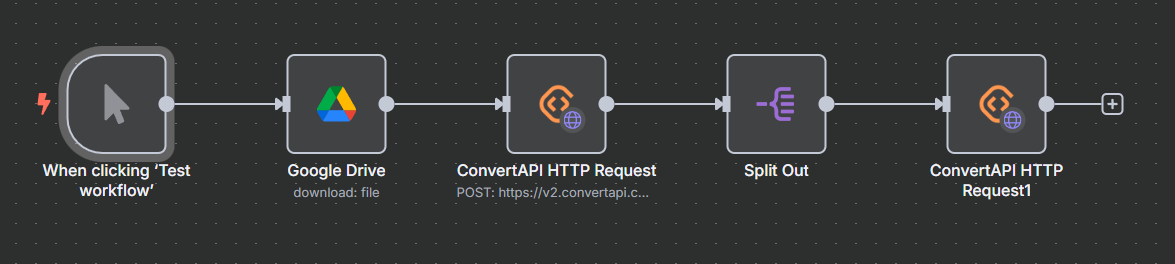
What would be the ideal workflow to split a PDF (from my Drive) into 5 pages PDFs to then extract the data from each and merge this data together in my SupaBase?
for example, name each section something like Split 1, Split 2, etc. If you’re using a vector store, this kind of structure can really help it pick things up more accurately.
Working with PDFs, you can split them into chunks first. I’m pretty sure there’s either:
you could call an external service,
or even run a bit of Python code in a Code node or external script to handle the splitting.
the GUI editor when running in test mode handles around 20mb I think I heard okay, but anything over u may see browser issues (test with small data), and when running production it should run correctly with much larger data etc, as it runs more backend etc
Is it not valid to write the answer and format it with chatgpt? My native language is Spanish, in my opinion I think it helps me to clarify the idea of the answer, and this is not simply copy and paste, I know what I’m saying and doing, I do not know what case they are trying to compare me with, but if language limitations prevent us from sharing what we know how to do, I would understand that it is not the place or sense of community.
Your doing it an awful lot I’ve noticed over the last few days. Up to you, but maybe try format less gpt like ahaa it’s not my call but they could ban you,
"We will! However, we debated if we should let it answer questions on the forum and we decided against it as that would most likely quickly harm the community dynamic (it would basically turn the forum into a public chatbot, and remove all incentives for humans to interact with each other).
Instead, we’re exploring a chatbot that tries to help you before you post, quickly solving the common issues, while still leaving the interesting conversations on the forum itself.
I find this interesting because many of the problems here are repetitive, and I’ve noticed that we don’t bother checking to see if they’re resolved before asking.
I’ve also seen that with the official documentation, most people don’t read the documentation on how to configure the nodes.
If you’d allow me, I could help with something like this, develop it, and contribute.
it’s up to you, but I notice it makes it hard to read what actually needs doing. my suggestion would be use to format ofcourse, my english is bad (grammer etc) but I’ve always used computer to aid me, grammerly, gpts, but if you look back what you posted. Not many reply because it’s just confusing.
I’m trying to helpout and learn to know more than @mohamed3nan he knows to much haha, but in all seriousness learn how to use N8N as a lot of the replies I ve seen posted are a bit off, this will really help the community more
Looking for the simplest way to split a long PDF into smaller chunks? Try the Softaken PDF Splitter Software. It is designed for quick and hassle-free PDF separation.With this tool, you can split any PDF file by page number, page range, or even into single pages. It’s fully offline, works on all Windows versions, and doesn’t affect the original layout, text, or images. Perfect for both personal and professional use.There’s also a free demo version available so you can test its features before buying.