𝐘𝐨𝐮𝐫 n8n 𝐰𝐨𝐫𝐤𝐟𝐥𝐨𝐰𝐬 𝐚𝐫𝐞 𝐟𝐚𝐢𝐥𝐢𝐧𝐠 𝐢𝐧 𝐬𝐢𝐥𝐞𝐧𝐜𝐞; 𝐀𝐧𝐝 𝐢𝐭’𝐬 𝐜𝐨𝐬𝐭𝐢𝐧𝐠 𝐲𝐨𝐮.
𝗜𝗺𝗮𝗴𝗶𝗻𝗲 𝘁𝗵𝗶𝘀:
You’ve built the “perfect” automation. It’s saving you hours. You’ve moved on to other things, confident that your system is humming in the background.
Then, you get that message or that client ![]()
“Hey, why hasn’t this updated since Tuesday?”
You check n8n. 500 failed executions. ![]()
One small API change. One expired token. One silent error that went unnoticed for 48 hours because, by default, n8n doesn’t shout when it breaks. It just… stops.
n8n failures go silently; 𝗯𝘂𝘁 𝗻𝗼 𝗺𝗼𝗿𝗲
I recently discovered a “Life-Saving Assistant” for any automation enthusiast:
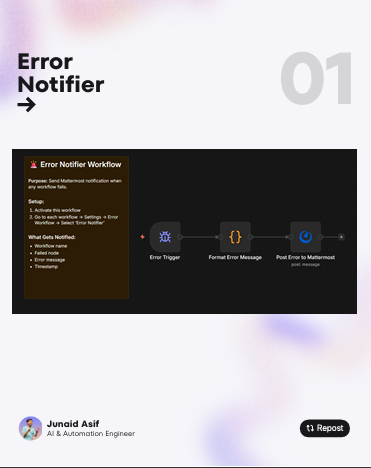
![]() 𝗧𝗵𝗲 𝗘𝗿𝗿𝗼𝗿 𝗡𝗼𝘁𝗶𝗳𝗶𝗲𝗿
𝗧𝗵𝗲 𝗘𝗿𝗿𝗼𝗿 𝗡𝗼𝘁𝗶𝗳𝗶𝗲𝗿
It’s a simple, dedicated workflow that acts as a 24/7 sentinel. The moment any of your workflows trip, it catches the fall, formats the details, and pings you immediately. No more guessing. No more waking up to a mess.
𝗧𝗵𝗲 𝗯𝗲𝘀𝘁 𝗽𝗮𝗿𝘁? You can build this for yourself in under 5 minutes using only these 3 actual n8n nodes:
![]() 𝗘𝗿𝗿𝗼𝗿 𝗧𝗿𝗶𝗴𝗴𝗲𝗿: This is your sentinel. It’s a special trigger node that listens for failures across your entire instance (or specific workflows). When something breaks, this node wakes up.
𝗘𝗿𝗿𝗼𝗿 𝗧𝗿𝗶𝗴𝗴𝗲𝗿: This is your sentinel. It’s a special trigger node that listens for failures across your entire instance (or specific workflows). When something breaks, this node wakes up.
![]() 𝗖𝗼𝗱𝗲: This is the brain. Use this to format the raw error data into a human-readable message. It grabs the workflow name, the specific node that failed, and the error message so you know exactly what to fix before you even open your laptop.
𝗖𝗼𝗱𝗲: This is the brain. Use this to format the raw error data into a human-readable message. It grabs the workflow name, the specific node that failed, and the error message so you know exactly what to fix before you even open your laptop.
![]() 𝗠𝗮𝘁𝘁𝗲𝗿𝗺𝗼𝘀𝘁/𝗦𝗹𝗮𝗰𝗸/𝗗𝗶𝘀𝗰𝗼𝗿𝗱/𝗘𝗺𝗮𝗶𝗹: This is your messenger. It sends that formatted alert directly to your pocket. I personally use Mattermost, but the beauty of n8n is that it’s your choice. Plug in Slack, Discord, or even Telegram; wherever you’re most likely to see it.
𝗠𝗮𝘁𝘁𝗲𝗿𝗺𝗼𝘀𝘁/𝗦𝗹𝗮𝗰𝗸/𝗗𝗶𝘀𝗰𝗼𝗿𝗱/𝗘𝗺𝗮𝗶𝗹: This is your messenger. It sends that formatted alert directly to your pocket. I personally use Mattermost, but the beauty of n8n is that it’s your choice. Plug in Slack, Discord, or even Telegram; wherever you’re most likely to see it.
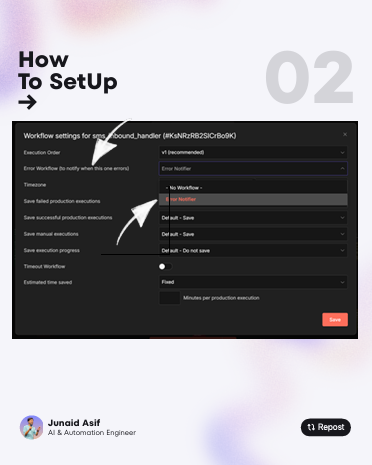
𝗧𝗵𝗲 𝘀𝗲𝘁𝘂𝗽 𝗶𝘀 𝘀𝗶𝗺𝗽𝗹𝗲:
Create your Notifier workflow.
In your other workflows, go to Settings → Error Workflow → Select your Notifier.
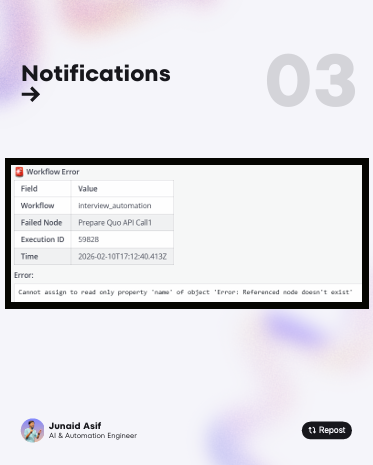
Now, instead of “discovering” a break through a frustrated client, you get a notification that says: “𝗛𝗲𝘆, 𝘁𝗵𝗲 𝗦𝗠𝗦 𝗛𝗮𝗻𝗱𝗹𝗲𝗿 𝗳𝗮𝗶𝗹𝗲𝗱 on the ‘Set’ node. Logic Error.”
You fix it in 30 seconds. You look like a pro. Your systems stay bulletproof.
Stop letting your workflows fail in the dark.![]()