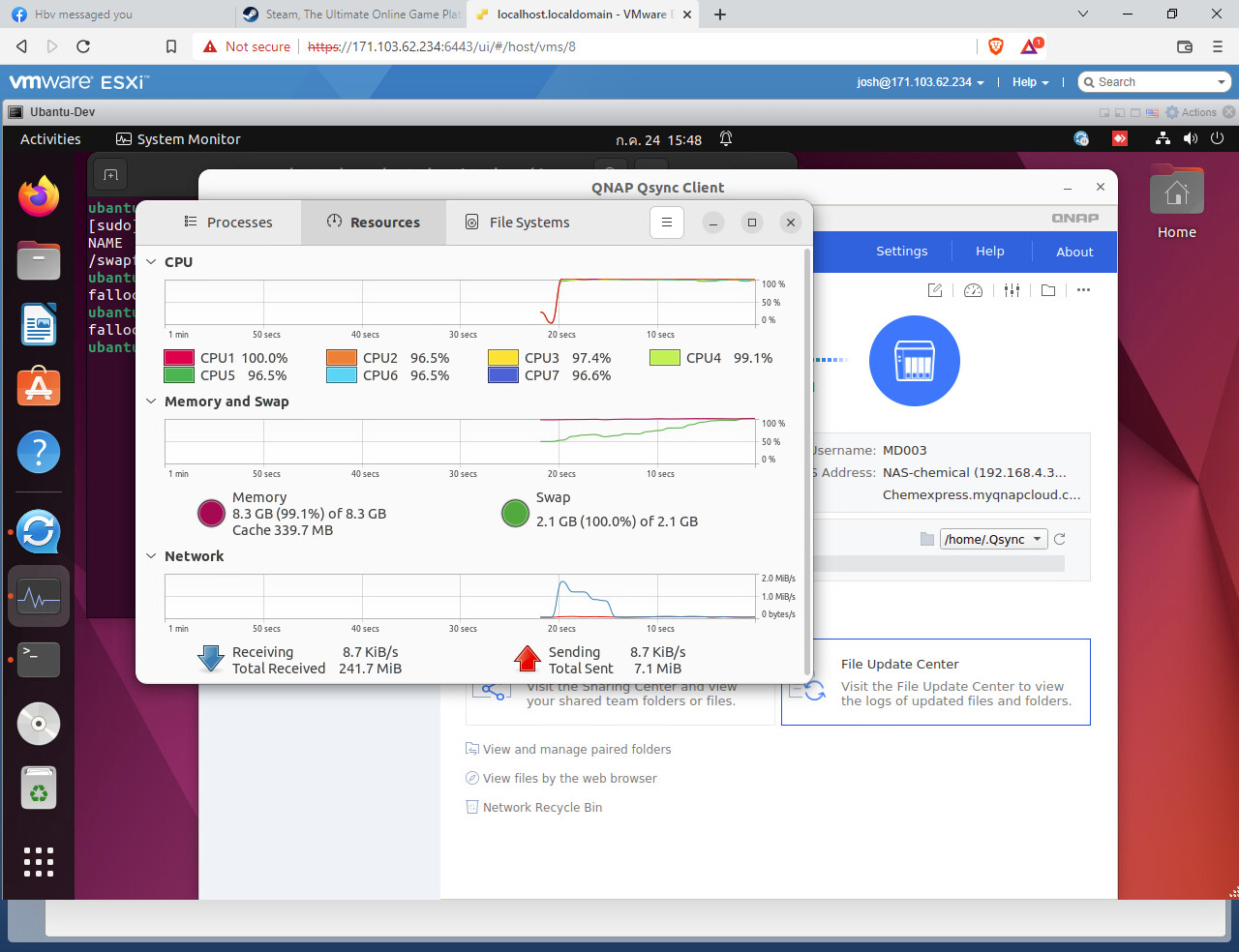
As I said in the previous issue https://github.com/n8n-io/n8n/issues/1583, I sus…pected that the Redis node doesn't close its connections after an execution. It seems to be the case, keeping the connections open until something goes wrong with it. In my case, the RabbitMQ server does not handle it well and just hangs the server, so I have to reboot...
But, this only happens when it is a webhook triggered execution. Looking at the connections open number for the RabbitMQ server, when I execute a workflow manually (like in the one below, with 10 sequential RabbitMQ nodes), it opens and closes the executions correctly. When it happens inside an execution triggered by a webhook, it doesn't close the connections until I close the worker process that handled the executions.
I didn't test the case for other triggered executions or integrated ones, but It's probably one of those 2 cases.
**To Reproduce**
1. Setup a RabbitMQ server and the credentials
2. Use the workflow below to test it, keeping an eye on the view of the open connections of the RabbitMQ UI
2.1 You may need to adjust and create the exchanges and queues to match the workflow.
3. Test it manually, and it will behave correctly
4. Test it calling from webhook, and the connections will keep open.
4.1 To run many times, you can use the following shell one-liner (on bash or zsh):
`for i in {1..50}; do echo $i; curl http://n8n-server/webhook/rabbitmq-test &; done`
Change the number of times and the URL. `http` (httpie) can be used instead of curl.
```json
{
"name": "Test / webhook RabbitMQ",
"nodes": [
{
"parameters": {},
"name": "Start",
"type": "n8n-nodes-base.start",
"typeVersion": 1,
"position": [
300,
400
]
},
{
"parameters": {
"path": "rmq",
"responseMode": "lastNode",
"responseData": "allEntries",
"options": {}
},
"name": "Webhook",
"type": "n8n-nodes-base.webhook",
"typeVersion": 1,
"position": [
300,
200
],
"webhookId": "f8e9855d-3b50-4770-bda2-f772cf5f51d8"
},
{
"parameters": {
"mode": "exchange",
"exchange": "test.dev.null",
"exchangeType": "direct",
"routingKey": "sender",
"options": {
"arguments": {
"argument": [
{}
]
}
}
},
"name": "sentToRMQ",
"type": "n8n-nodes-base.rabbitmq",
"typeVersion": 1,
"position": [
500,
200
],
"credentials": {
"rabbitmq": "RabbitMQ DEV"
},
"continueOnFail": true
},
{
"parameters": {
"mode": "exchange",
"exchange": "test.dev.null",
"exchangeType": "direct",
"routingKey": "sender",
"options": {
"arguments": {
"argument": [
{}
]
}
}
},
"name": "sentToRMQ1",
"type": "n8n-nodes-base.rabbitmq",
"typeVersion": 1,
"position": [
650,
200
],
"credentials": {
"rabbitmq": "RabbitMQ DEV"
},
"continueOnFail": true
},
{
"parameters": {
"mode": "exchange",
"exchange": "test.dev.null",
"exchangeType": "direct",
"routingKey": "sender",
"options": {
"arguments": {
"argument": [
{}
]
}
}
},
"name": "sentToRMQ2",
"type": "n8n-nodes-base.rabbitmq",
"typeVersion": 1,
"position": [
800,
200
],
"credentials": {
"rabbitmq": "RabbitMQ DEV"
},
"continueOnFail": true
},
{
"parameters": {
"mode": "exchange",
"exchange": "test.dev.null",
"exchangeType": "direct",
"routingKey": "sender",
"options": {
"arguments": {
"argument": [
{}
]
}
}
},
"name": "sentToRMQ3",
"type": "n8n-nodes-base.rabbitmq",
"typeVersion": 1,
"position": [
950,
200
],
"credentials": {
"rabbitmq": "RabbitMQ DEV"
},
"continueOnFail": true
},
{
"parameters": {
"mode": "exchange",
"exchange": "test.dev.null",
"exchangeType": "direct",
"routingKey": "sender",
"options": {
"arguments": {
"argument": [
{}
]
}
}
},
"name": "sentToRMQ4",
"type": "n8n-nodes-base.rabbitmq",
"typeVersion": 1,
"position": [
1100,
200
],
"credentials": {
"rabbitmq": "RabbitMQ DEV"
},
"continueOnFail": true
},
{
"parameters": {
"mode": "exchange",
"exchange": "test.dev.null",
"exchangeType": "direct",
"routingKey": "sender",
"options": {
"arguments": {
"argument": [
{}
]
}
}
},
"name": "sentToRMQ5",
"type": "n8n-nodes-base.rabbitmq",
"typeVersion": 1,
"position": [
500,
400
],
"credentials": {
"rabbitmq": "RabbitMQ DEV"
},
"continueOnFail": true
},
{
"parameters": {
"mode": "exchange",
"exchange": "test.dev.null",
"exchangeType": "direct",
"routingKey": "sender",
"options": {
"arguments": {
"argument": [
{}
]
}
}
},
"name": "sentToRMQ6",
"type": "n8n-nodes-base.rabbitmq",
"typeVersion": 1,
"position": [
650,
400
],
"credentials": {
"rabbitmq": "RabbitMQ DEV"
},
"continueOnFail": true
},
{
"parameters": {
"mode": "exchange",
"exchange": "test.dev.null",
"exchangeType": "direct",
"routingKey": "sender",
"options": {
"arguments": {
"argument": [
{}
]
}
}
},
"name": "sentToRMQ7",
"type": "n8n-nodes-base.rabbitmq",
"typeVersion": 1,
"position": [
800,
400
],
"credentials": {
"rabbitmq": "RabbitMQ DEV"
},
"continueOnFail": true
},
{
"parameters": {
"mode": "exchange",
"exchange": "test.dev.null",
"exchangeType": "direct",
"routingKey": "sender",
"options": {
"arguments": {
"argument": [
{}
]
}
}
},
"name": "sentToRMQ8",
"type": "n8n-nodes-base.rabbitmq",
"typeVersion": 1,
"position": [
950,
400
],
"credentials": {
"rabbitmq": "RabbitMQ DEV"
},
"continueOnFail": true
},
{
"parameters": {
"mode": "exchange",
"exchange": "test.dev.null",
"exchangeType": "direct",
"routingKey": "sender",
"options": {
"arguments": {
"argument": [
{}
]
}
}
},
"name": "sentToRMQ9",
"type": "n8n-nodes-base.rabbitmq",
"typeVersion": 1,
"position": [
1110,
400
],
"credentials": {
"rabbitmq": "RabbitMQ DEV"
},
"continueOnFail": true
}
],
"connections": {
"Webhook": {
"main": [
[
{
"node": "sentToRMQ",
"type": "main",
"index": 0
}
]
]
},
"Start": {
"main": [
[
{
"node": "sentToRMQ",
"type": "main",
"index": 0
}
]
]
},
"sentToRMQ": {
"main": [
[
{
"node": "sentToRMQ1",
"type": "main",
"index": 0
}
]
]
},
"sentToRMQ1": {
"main": [
[
{
"node": "sentToRMQ2",
"type": "main",
"index": 0
}
]
]
},
"sentToRMQ2": {
"main": [
[
{
"node": "sentToRMQ3",
"type": "main",
"index": 0
}
]
]
},
"sentToRMQ3": {
"main": [
[
{
"node": "sentToRMQ4",
"type": "main",
"index": 0
}
]
]
},
"sentToRMQ4": {
"main": [
[
{
"node": "sentToRMQ5",
"type": "main",
"index": 0
}
]
]
},
"sentToRMQ5": {
"main": [
[
{
"node": "sentToRMQ6",
"type": "main",
"index": 0
}
]
]
},
"sentToRMQ6": {
"main": [
[
{
"node": "sentToRMQ7",
"type": "main",
"index": 0
}
]
]
},
"sentToRMQ7": {
"main": [
[
{
"node": "sentToRMQ8",
"type": "main",
"index": 0
}
]
]
},
"sentToRMQ8": {
"main": [
[
{
"node": "sentToRMQ9",
"type": "main",
"index": 0
}
]
]
}
},
"active": true,
"settings": {},
"id": "16"
}
```
**Environment:**
- OS: Fedora Linux 33 (x86_64)
- n8n Version: 0.112.0
- Node.js Version: v14.16.0
- Postgresql: 12.6
- Relevant envs:
- `DB_TYPE=postgresdb`
- `EXECUTIONS_PROCESS=main`
- `EXECUTIONS_MODE=regular`