I’m currently working on a workflow that helps me create a summary of a YouTube transcript in a way that allows for pre-reading. To achieve that I use summarization chain with custom prompts that give me the structured output.
What is the error message (if any)?
After updating the prompts, there are numerous calls for the “Individual Summary Prompt” (approximately 50), which are very costly to generate, and it seems that they are not necessary because the data was already summarized in previous steps. This behavior is inconsistent, as for certain models like LLama 4 Maverick, the number of prompts is correctly equal to n+1, where n is the number of text chunks + 1 for summary.
Please share your workflow
Share the output returned by the last node
The output is correct and expected, but there are too many recalls for the “Individual Summary Prompt.”
After testing the workflow, I noticed something strange:
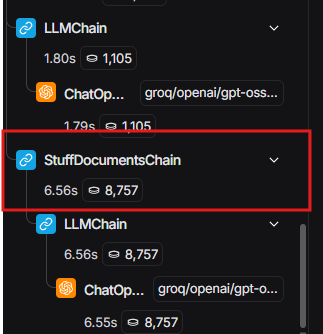
The Summarization Method is configured as “Map Reduce” but when I run it and check the logs (external logs), it actually uses StuffDocumentsChain!!
First of all, thank you for your kind words and for your investigation.
I find this interesting; I wasn’t aware of that. How did you use these external locks? What tool did you use for them?
From what I can see, there is only the “Summarization Chain” node along with numerous calls to the model beneath it. However, only the first five calls are related to chunks created from the text. The rest are “Individual Summary Prompts” based on the summaries from the previous steps.
What is also interesting is that if I use LLama 4 Maverick, there are only 6 calls for the same file, and it’s the correct number since I have 5 chunks of text plus 1 for the summary.
This is LangSmith, you can easily integrate it with n8n, look here:
Regarding the calls, when I increased the video length I was testing with, I started getting a lot more calls which seems normal..
However, I still end up with a StuffDocumentsChain at the end.
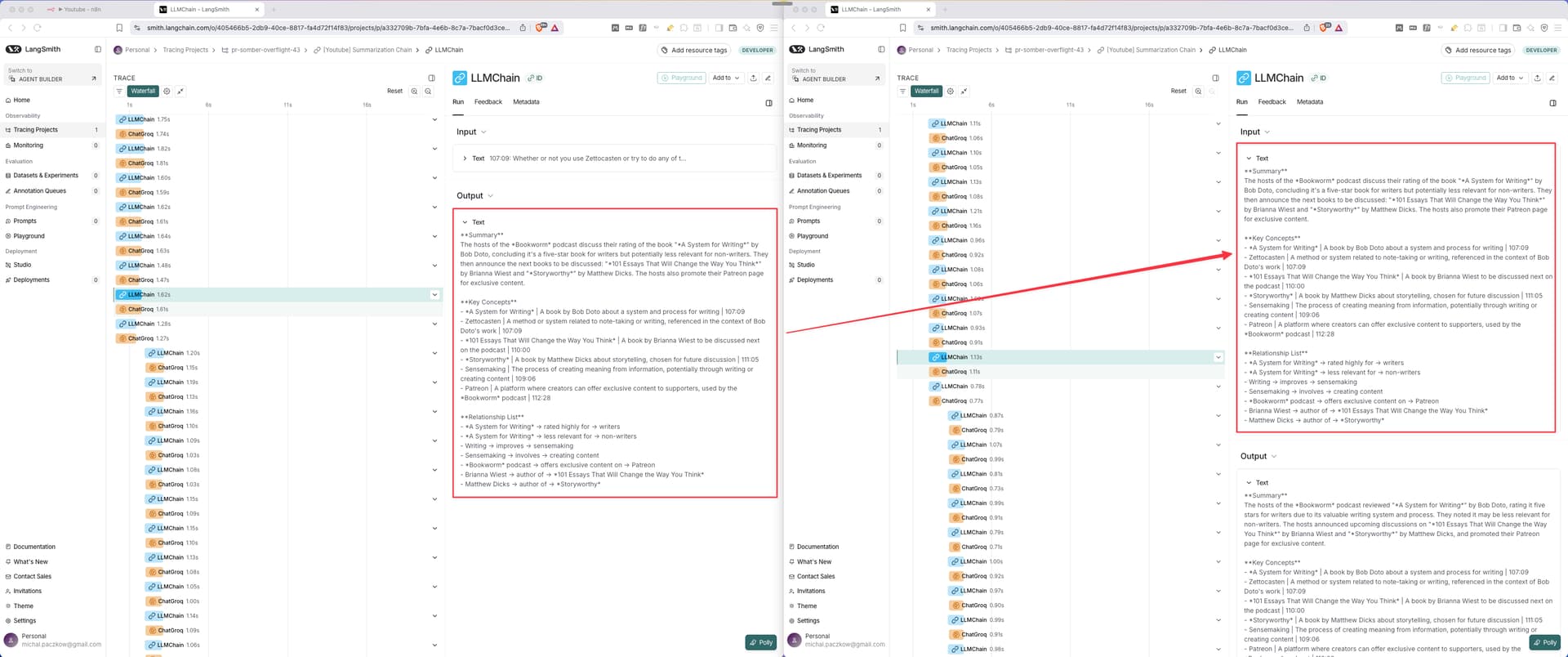
I connected it, and it seems that there are multiple phases of summary chunks related to “Individual Summary Prompt”. In the first phase, a summary is generated from the transcript chunk, as expected. However, additional LLM chains are created that summarize the output from the previous step. I’m not sure if this is the expected behavior or if it’s a bug.