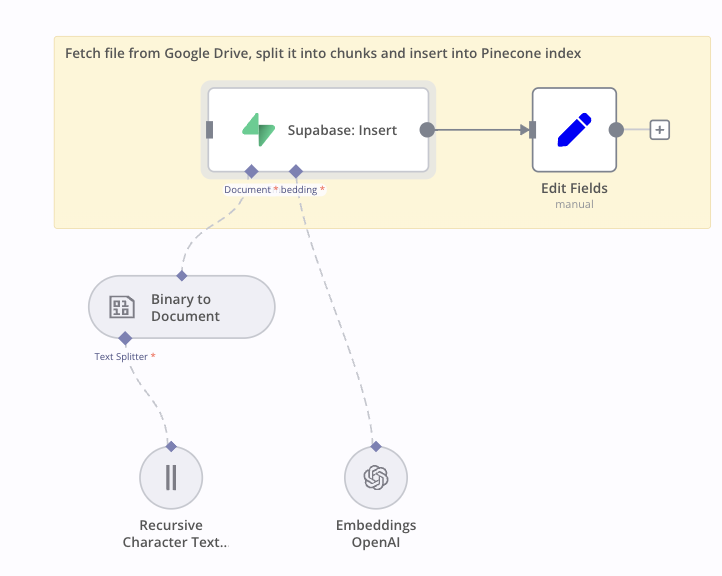
When we insert some binary data to supabase, it sends all data in predefined format for documents table. We would like to keep some extra meta data per each row but Supabase insert node does not output inserted row ids and we cannot add meta data to supabase insert node.
How can we manage to mark each supabase row with an id for document?
@jan Yes, definitely something I want to implement next week. @emrek Could you share more about your use-case? What metadata are you interested in? Are they already in your workflow in some previous step or would you expect to populate them dynamically based on the content of the file?
@oleg When I was trying to implement a Q&A based on some documents, I can use supabase insert to push all vectors to db. But issue is, when document gets deleted or changed, I need to clear out those rows from the table and create new rows. When I index like 20 documents, it becomes hard to find which rows belong to which document.
Currently I implemented a method to sha265 all return contents and match them by their hash value and create a document relation table in supabase.
If supabase insert had these two functions it would be much easier,
an input where we can set a json object value that will be merged with each row’s meta values. I would like to use this to find references to file url’s that contains given information.
output of supabase insert to have inserted rows’ ID values.
it would also be nice to have a select columns parameter where we can define which column values gets returned from insert output.