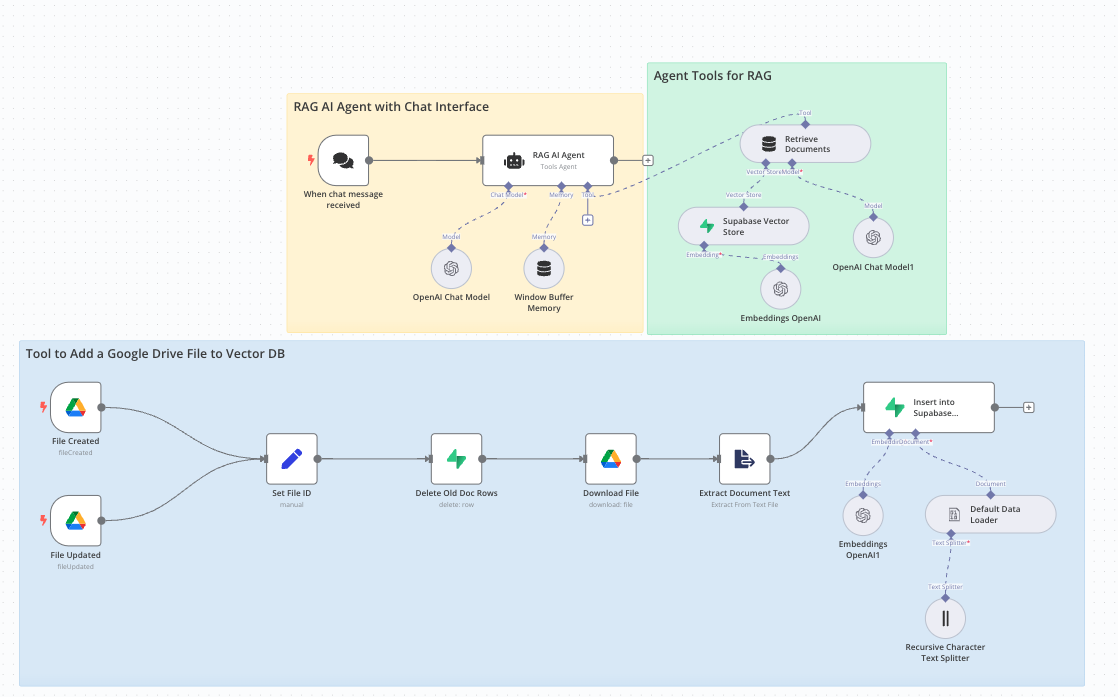
Hello, I have created a Google drive to Supabase Vector DB connection so I can then query my documents and it works. In order to input data into the db I need to embed it using OpenAI or another provider. I got it working and when I import a document into my google drive it will then store it in my vector DB.
I created my vector DB using the Supabase vector Quickstart (from the documentation) which creates the columns: id, content, metadata and embedding. I can then query the db and have it return results.
My question is
If I wanted to add an additional column to the db, how can I add it and then make it searchable as well? I had tried creating an additional column with a text field in Supabase and it is not searchable
Would this be done in Extract from Text Action? Or would I need to modify the Query Name of match_documents?
Just curious to get a better understanding of where to look as documentation is sparse around it so any advice someone could give would be greatly appreciated!
I’m assuming you can just do simple SQL over the text field as well - if that’s the case, then you could use the “Supabase tool” for your agent.
My only caveat is to think about that lifecycle of the data. If you needed to wipe some/all the documents from the vector store table, how easy is it to rebuild this extra column? and vice-versa? Splitting your tables by “usage” is a common pattern to manage this.