I have tested the PDF to Text extraction and I can see a dump of the text. I would like to know how I would target particular text to be stored in an xml which will used to import into a logistics application (Cargowise).

It looks like your topic is missing some important information. Could you provide the following if applicable.
- n8n version:
- Database (default: SQLite):
- n8n EXECUTIONS_PROCESS setting (default: own, main):
- Running n8n via (Docker, npm, n8n cloud, desktop app):
- Operating system:
Hi @gezburga
Traditionally you would probably look for text patterns and use regex or other string manipulations to modify the output so it can be parsed to XML.
But you could probably let a LLM do that for you, since it’s very good with text and pattern recognition, you have to make to sure that it returns the output as JSON and then you can use the XML node.
Here’s an example using a simple LLM chain node:
Feel free to also check out our template collection for other ideas:
Thanks.
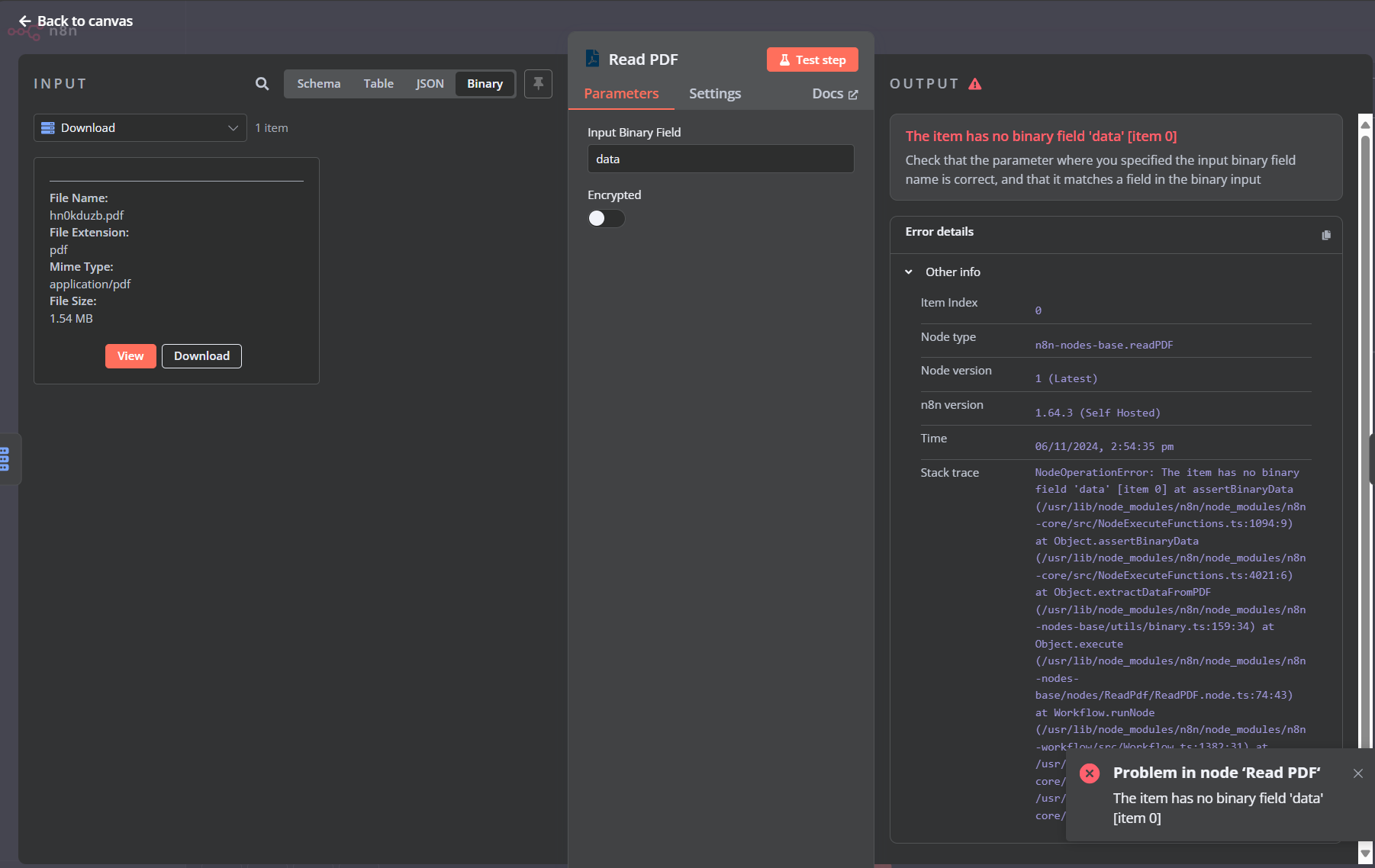
I am having an issue reading from PDF after download from FTP. I keep seeing
“NodeOperationError: The item has no binary field ‘data’ [item 0] at assertBinaryData”. I cannot see Binary data from the PDF
What I would like to accomplish is.
- Connect FTP
- Read first PDF file and extract targetted text
- Store results
- Move the file to a subfolder within FTP
- Download the next PDF and loop through until there’s no more PDF files.
In the Download node you should name Put Output File in Field
as data then you can use it in Read PDF node.
BTW there is no need to use Code node to obtain first item, you just can use an expression in Download node {{ $input.first().json.path }} and don’t forget to switch on Execute Once in Settings of this node.
Or you can use Filter and Limit nodes:
Thanks Ruslan, that is working now.
I was just wondering if there’s an easier way to read the PDF using AI to extract the required Text.
I have a Llama Parsing API and sending the PDF there.
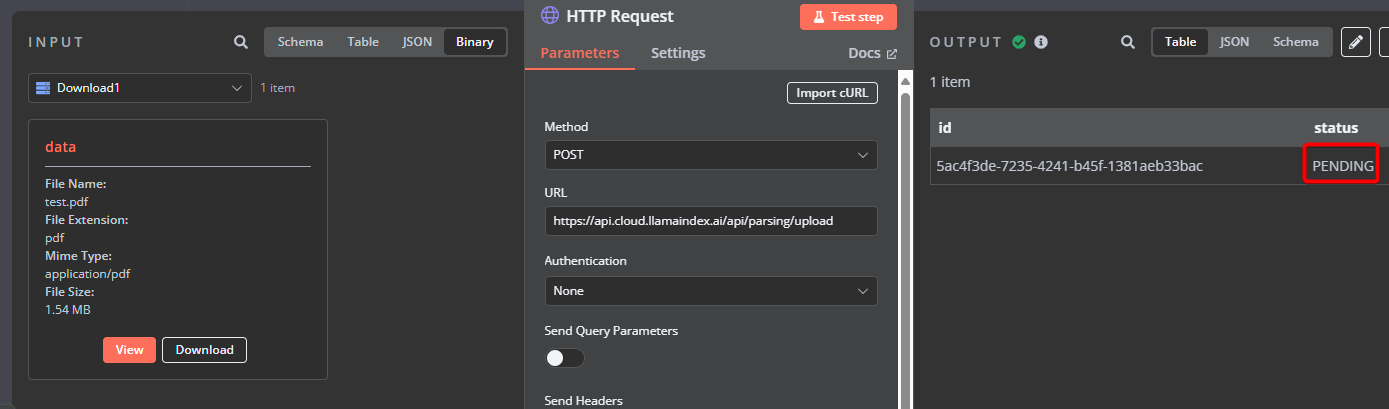
I have the status pending
Then trying toi check the status but I am not sure if this ID is a pipeline ID.
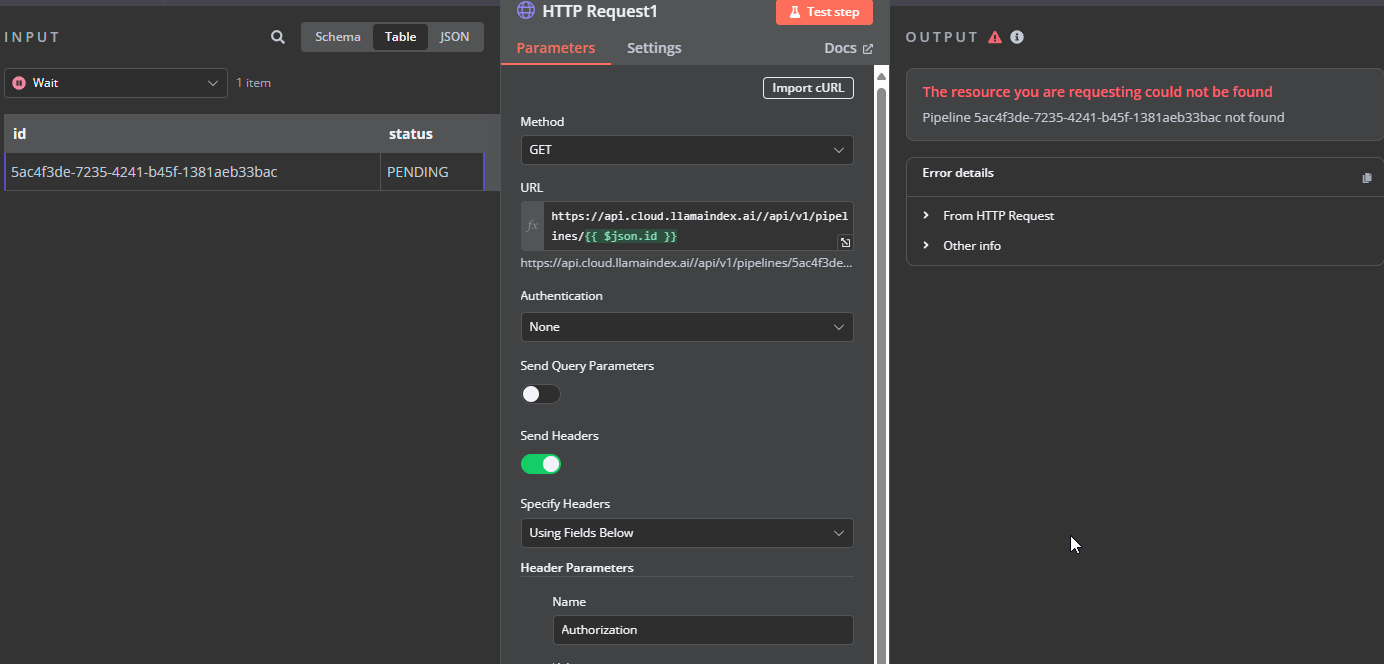
Hey, as I can see in documentation you should wait until status change to ready I suppose.
Check the status of the parsing job:
curl -X 'GET' \
'https://api.cloud.llamaindex.ai/api/parsing/job/<job_id>' \
-H 'accept: application/json' \
-H "Authorization: Bearer $LLAMA_CLOUD_API_KEY"

Just copy it under Import cURL
OK thankyou for that.
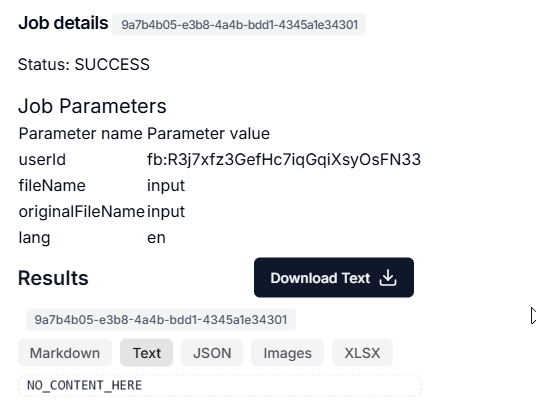
I am also trying to send the request with the query to target 1st page and extract the text, but it doesn’t look like it’sending these queries
curl -X ‘POST’
‘https://api.cloud.llamaindex.ai/api/parsing/upload’
-H ‘accept: application/json’
-H ‘Content-Type: multipart/form-data’
-H “Authorization: Bearer $LLAMA_CLOUD_API_KEY”
–form ‘target_pages=“1”’
–form ‘Extract SWB No., Extract Shipper, Extract Consignee, Extract Notify Party / Address, Extract Vessel and Voyage, Extract Port of Loading, Extract Port of Discharge, Extract Type of Service=“string”’ \
This is a question abot how to properly use the cloud.llamaindex.ai API, unfortunately am not familiar with their API.
I can’t see this part on their documentation.https://docs.cloud.llamaindex.ai/API/upload-file-api-v-1-parsing-upload-post
Thankyou for your help thus far. I found I was not actually sending the PDF in the first place. I added the below and it’s now sending it successfully.
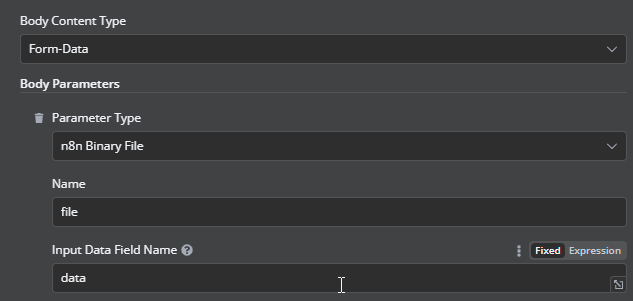
I have a HTTP Request to GET the results but is not showing any output
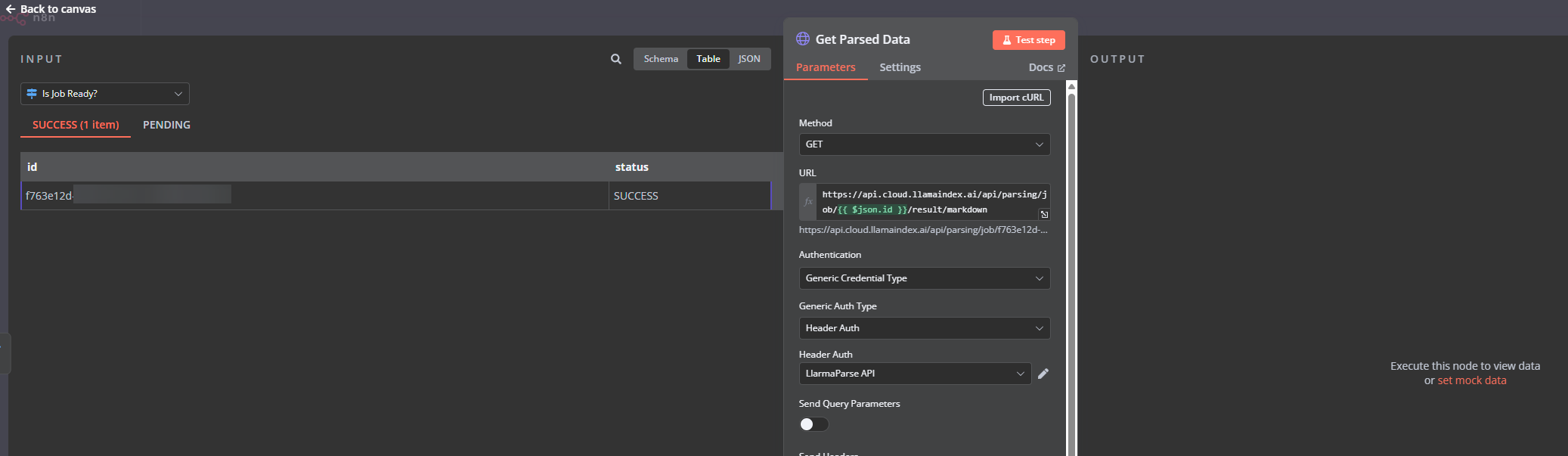
I pasted the link into browser and it is returning the data
Just an update on this, if I run the whole workflow it works OK. Not sure why it doesn’t work when testing the node.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.