When you’re testing single nodes that are hooked up (especially with multiple inputs) it makes sense to keep some pinned data in the previous nodes, otherwise the tested node will always try to run all previous nodes to get some live input data, which sometimes can lead to the error you’ve got there.
As for the AI Service, can you check if you see anything in your browser console logs when that happens?
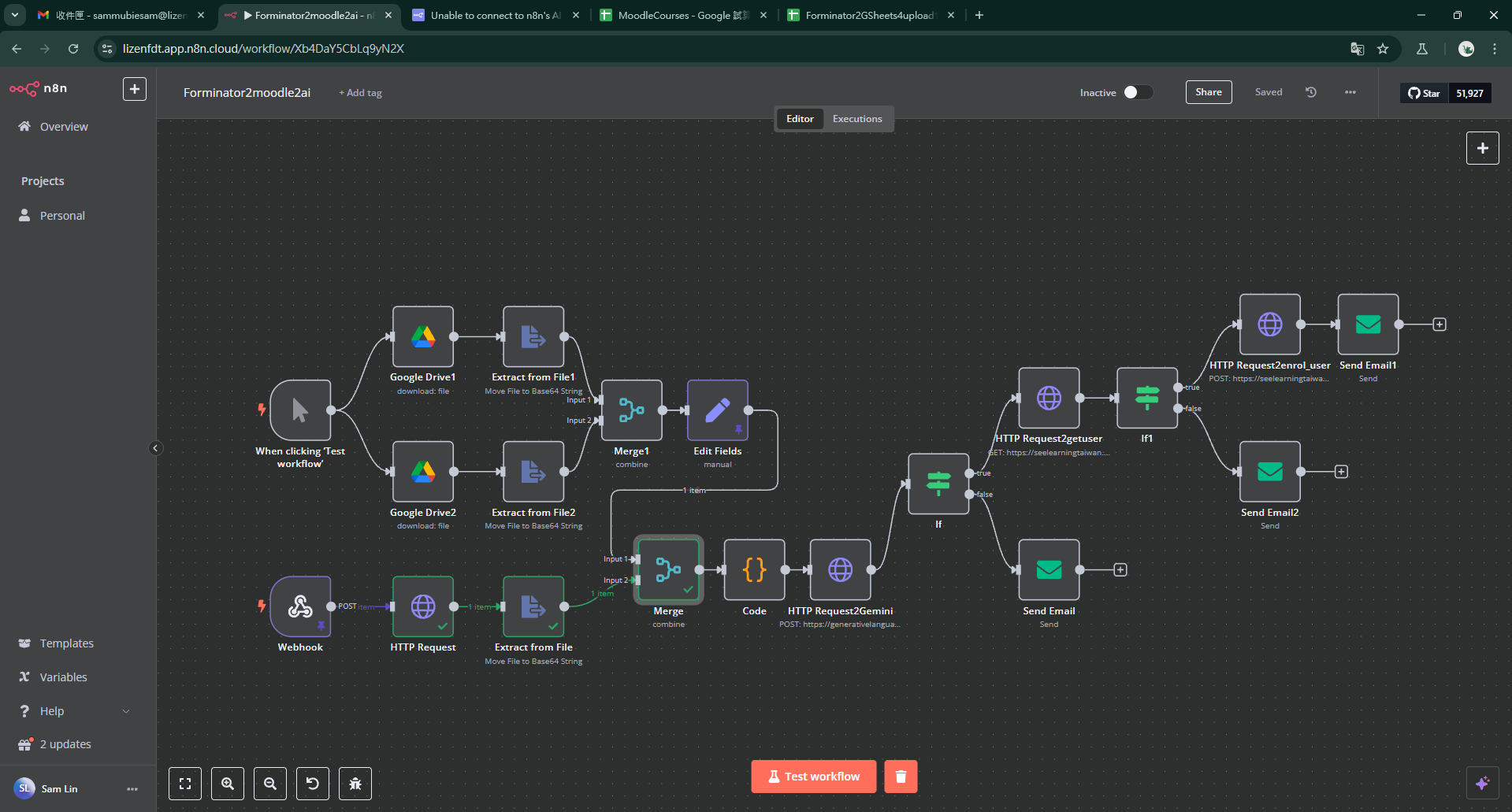
I have modified the workflow as screenshot, and pined the 2 example files in the “Edit Fields” node. But executing workflow will not include all the 3 files in Merge node sometimes, any suggestion what should I add?
As for the AI Service, it was not happening after changing to this workflow until today, the DevTools shows…
Failed to load resource: the server responded with a status of 500 ()
Output:
The service was not able to process your request
An internal error has occurred.
Clicked “Ask Assistant” will get “Unable to connect to n8n’s AI service: ()”
Sorry for the late reply! We took a look into our AI assistant service and it seems that this error is because it received too much payload in the context (possibly from the merge nodes in your workflow)
We’re working on providing a better error description for cases like this… Thank you for reporting!
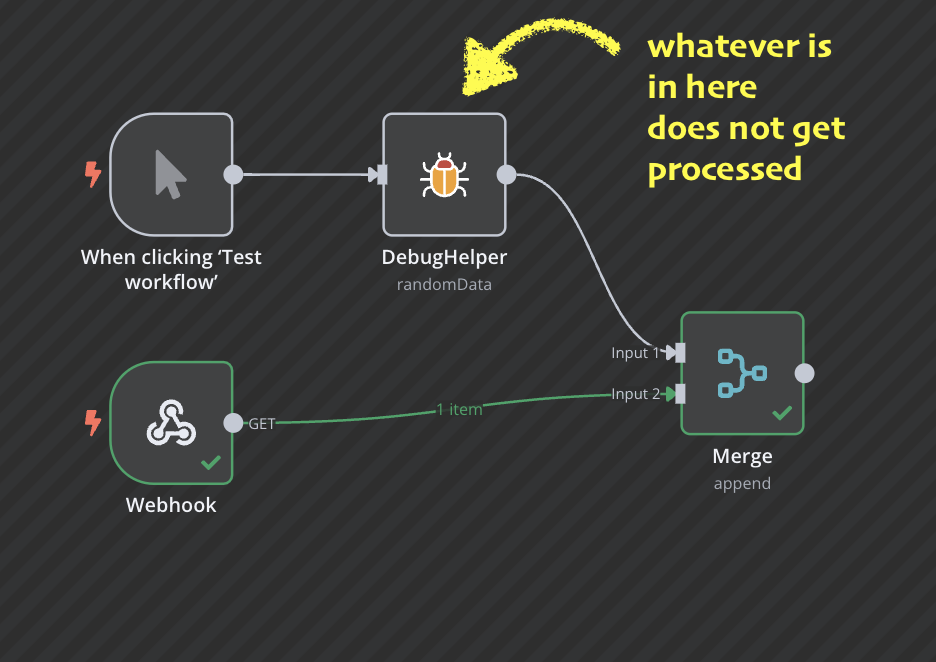
Regarding your workflow: bear in mind that the merge node only continues when both inputs have completed. In your current setup, the workflow gets triggered from a webhook but will actually never complete because the other part of the merge node input is dependent on a manual workflow start !
What kind of data do you need to “store” ? There’s several ways you can “persist” data across workflows, but the important part is that when your workflow is triggered (Webhook) the flow needs to “touch” the data that you’ve stored in order to include it in the processing.
When you have a look in your previous executions you can see the green lines (which is your data flow) and you can see that the upper part of your workflow was not processed at all.
Here’s a simplified illustration of what I mean:
If you have any data that is static, that you want to include in every run of your workflow, you will need to contain that in nodes that will run in the same “flow” after the respective trigger.
There’s different solutions, depending on what you need to store: