I’m running a HTTP request to a service that scrapes website data and sends it back. Unfortunately, it is in HTML format and I’ve been trying to extract a few values from the returned data using regex.
I tested the regex code on regex101.com and have been able to extract the data, but I am unable to set it up on n8n.
Here is the code I’ve been using in the ‘code’ node:
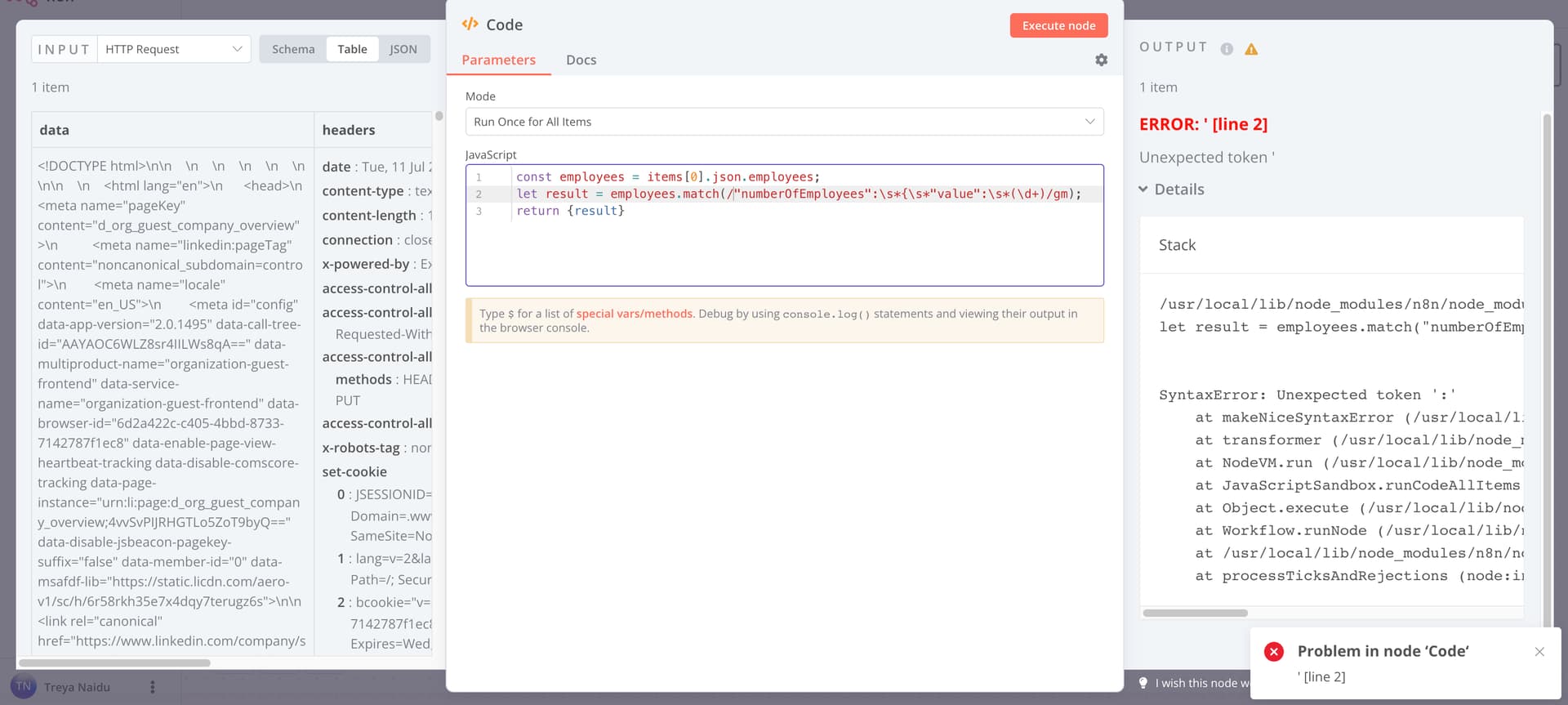
const employees = items[0].json.employees;
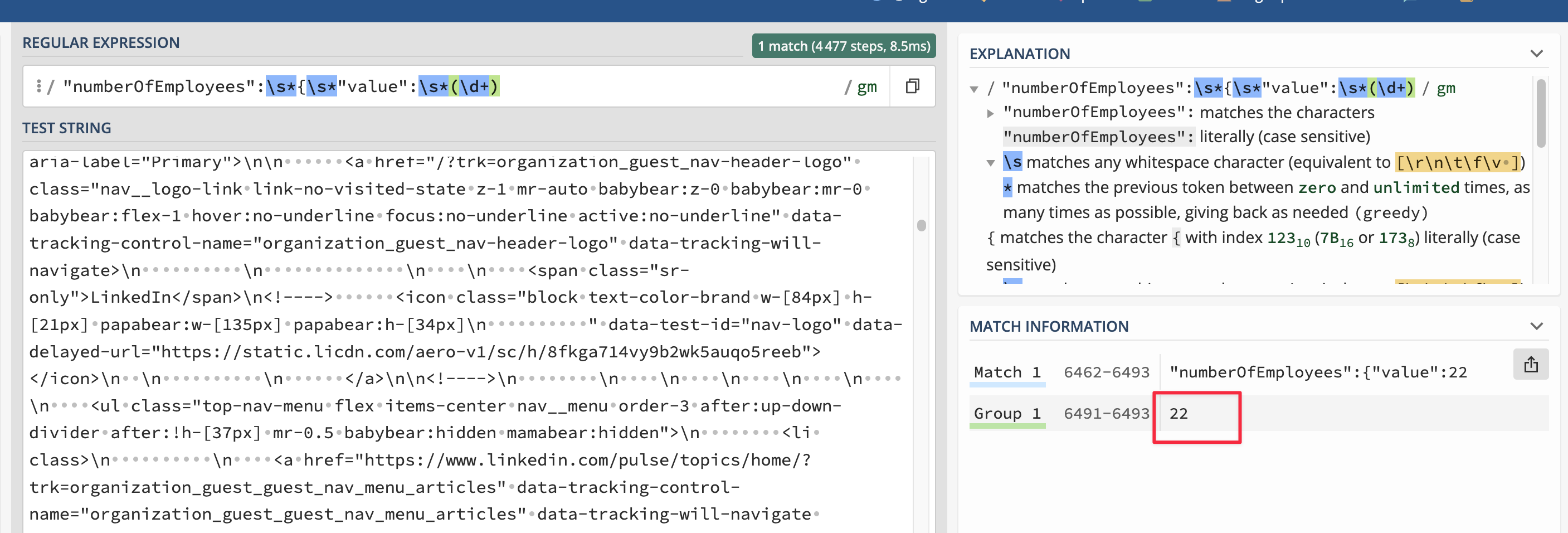
let result = employees.match(/“numberOfEmployees”:\s*{\s*“value”:\s*(\d+)/gm);
return {result}
Can someone help me with the correct way to execute the regex in the code node?
I did try other methods too…using the Set node…HTML extract node and I have been unsuccessful in all of those even after spending several hours and taking chatgpt’s help too.
Defeated, I come ot the community for help with this. Would greatly appreciate it if anyone can look at the code and lmk if I am doing something incorrectly.
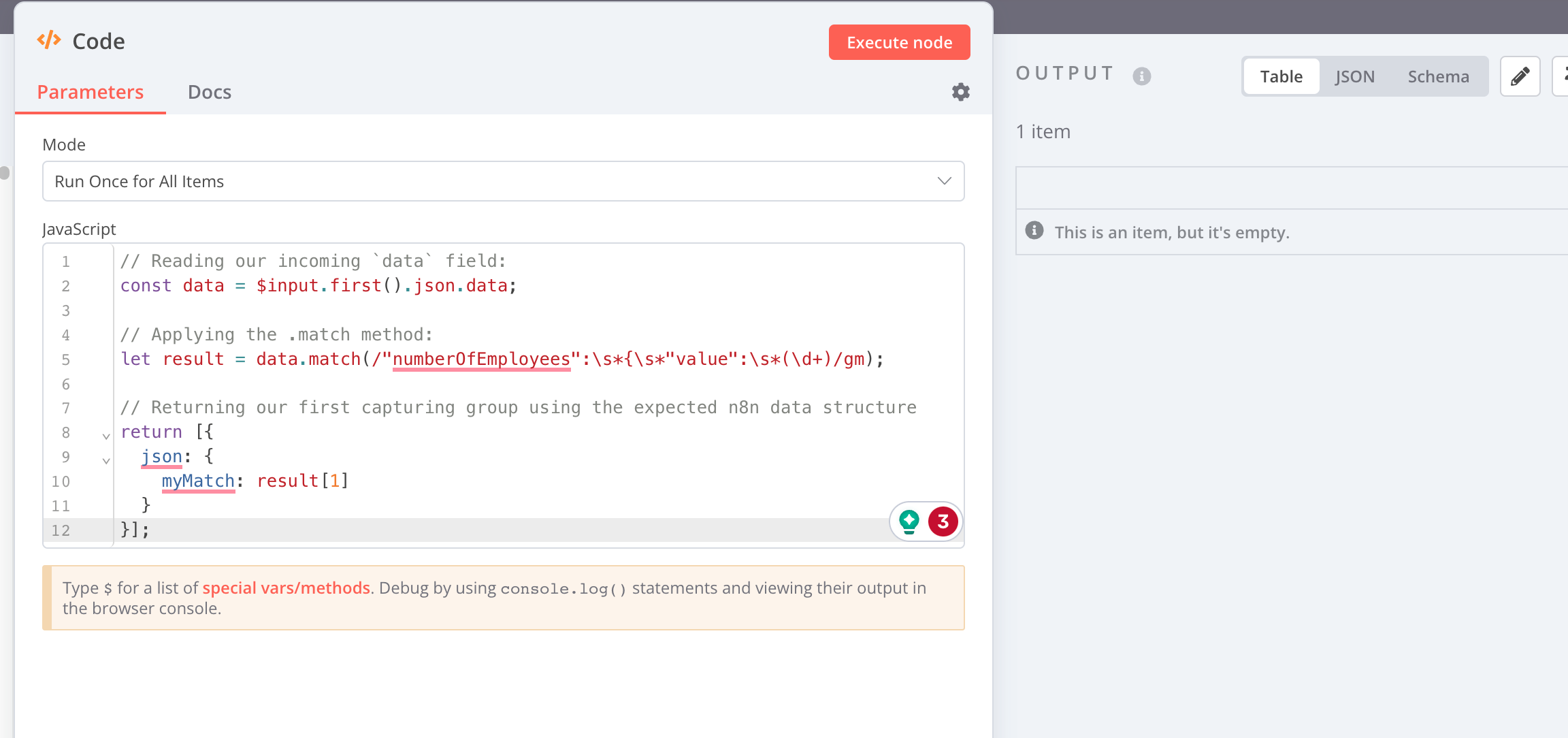
I am very sorry you are having trouble. From looking at the code you have shared I can see three potential problems.
In recent versions of n8n, you’d typically reference incoming data using $input… variables and methods documented here
It seem you are performing your matching against an employees field:
const employees = items[0].json.employees;
let result = employees.match(/"numberOfEmployees":\s*{\s*"value":\s*(\d+)/gm);
return {result}
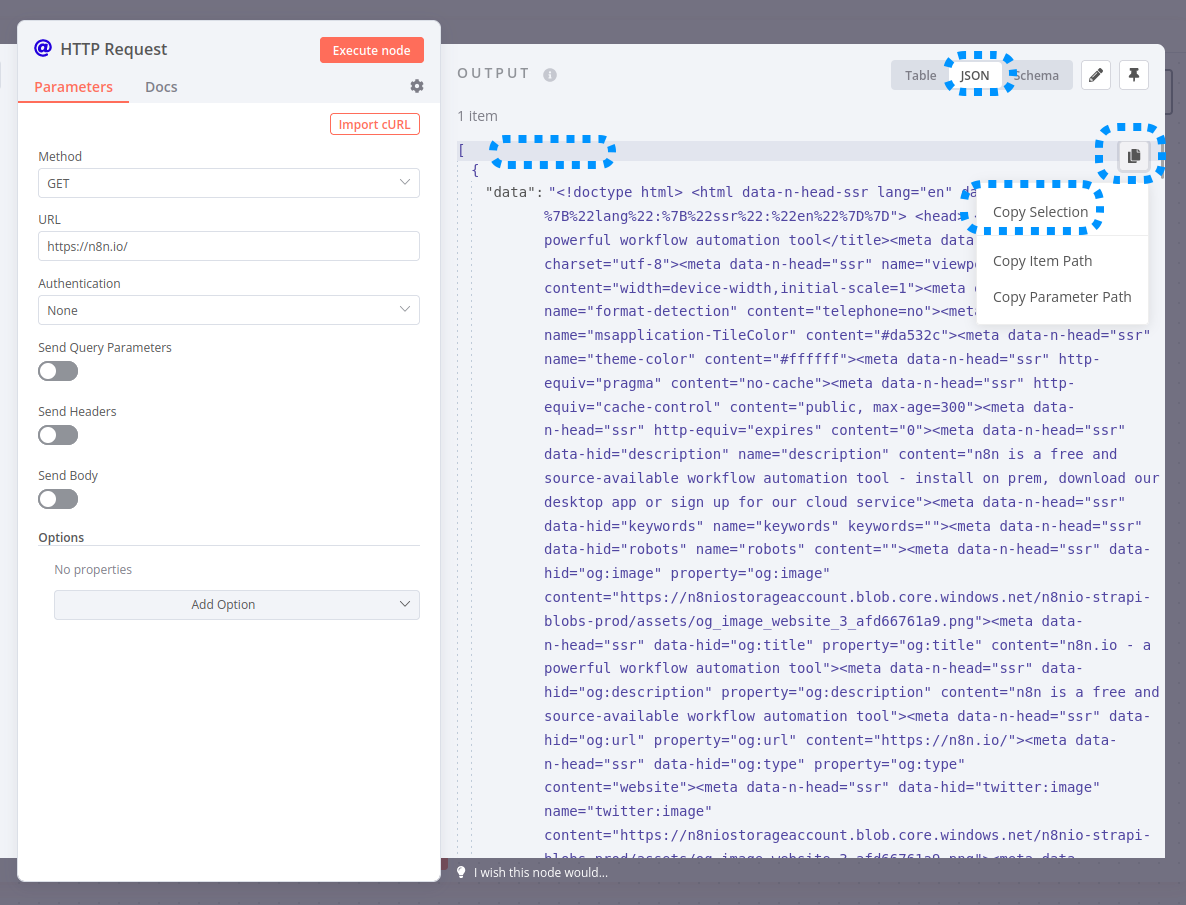
However, on your screenshot I don’t see any employees field (only a data field) in your incoming dataset. Perhaps you can share the URL your are fetching in your HTTP Request node or exact JSON data you are passing on to your Code node? You can copy it by selecting the first line of the JSON data, then using the Copy button and clicking Copy Selection:
When returning the data in your Code node you’d then need to make sure to return a valid n8n data structure.
Now on a more general note it is often easier to use the HTML node to extract data from a website using CSS selectors (instead of regular expressions), so you might want to check out this option out as well.
However, if you do have to use regular expressions in order to extract web content, here’s a quick example workflow doing so on [email protected]:
This would extract the copyright year from the n8n website as shown above, but you can of course adapt the example workflow as needed.
If you need help with your specific transformation perhaps you can share the data you are currently processing as suggested above plus the result you would like to see? It’d be great if you could also confirm the version of n8n you are currently using.
I’m happy to switch to any method if Regex isn’t the best way to go about this.
I’ve added the output of the HTML element in this gdoc because it is pretty lengthy:
Ideally, I’d love to extract the following info from the HTML output:
Company Name
Follower Count
Company Description
Website
Industry
Employee Range
LinkedIn Employee Count
City & State
Year Founded
Specialties
Primary Location
If you can test it out and lmk how I can setup the HTML extractor to achieve this, I’d be really grateful.
I’ve tried the CSS selector too, but it didn’t really work out for me, so I tried the regex code node.
Thanks @tre, looks like it’s almost working seeing there is no more error.
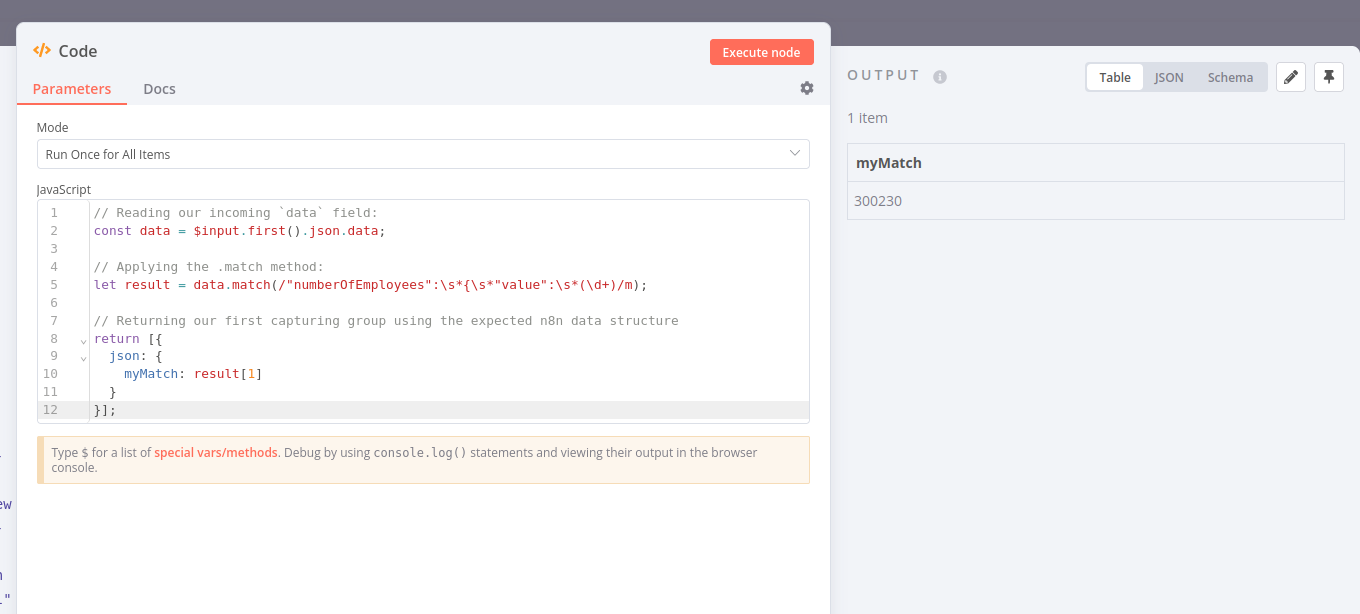
I actually think that what you are seeing here is not so much an n8n specific problem but a problem with how the match() method in JavaScript works:
If the g flag is used, all results matching the complete regular expression will be returned, but capturing groups are not included.
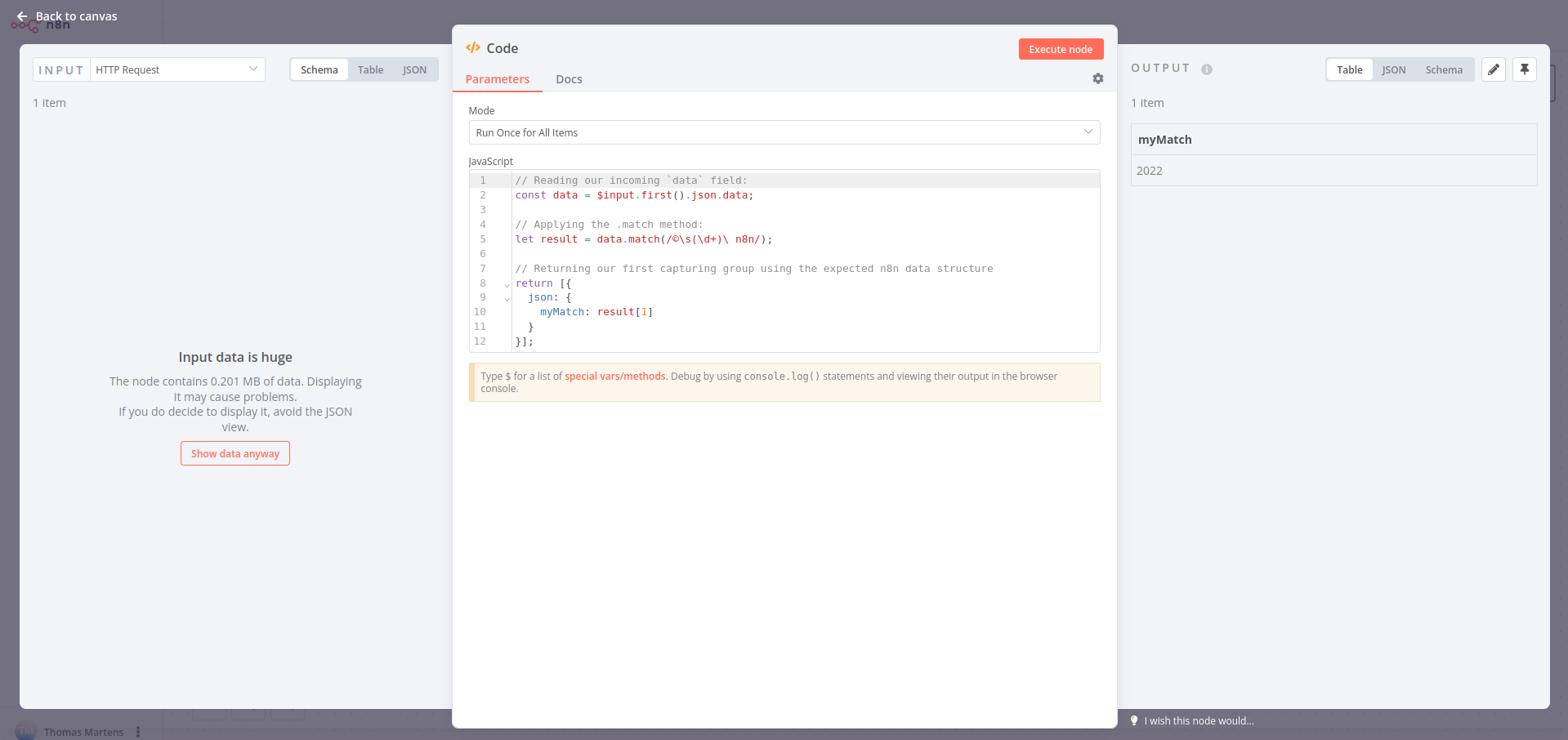
Seeing you are using the g flag in your regular expression, your capturing group is not being returned. If you just remove the g modifier this should work as expected:
// Reading our incoming `data` field:
const data = $input.first().json.data;
// Applying the .match method:
let result = data.match(/"numberOfEmployees":\s*{\s*"value":\s*(\d+)/m);
// Returning our first capturing group using the expected n8n data structure
return [{
json: {
myMatch: result[1]
}
}];
You are a lifesaver! This worked like a charm! Phew…Really grateful to you!
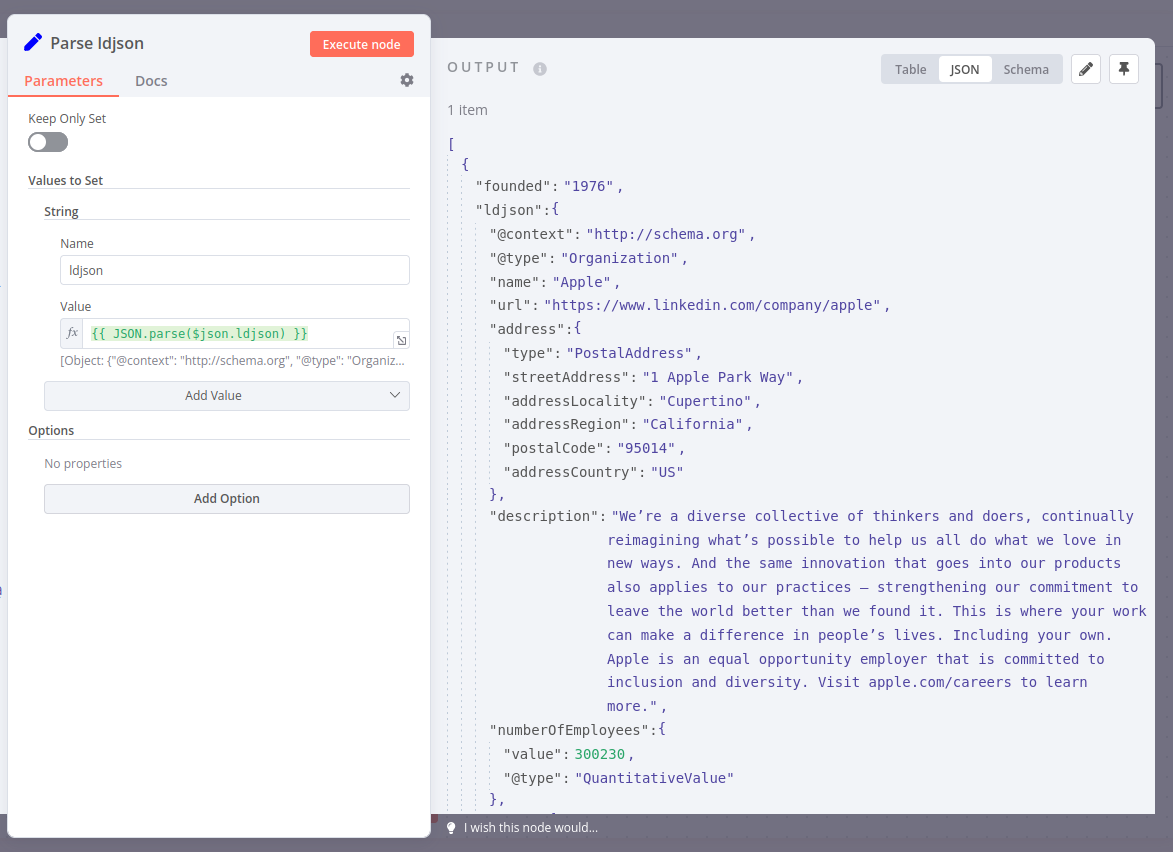
If it’s not too much trouble, can you help me figure out the regex code to extract the “about-us__foundedOn” value from the file I shared above?
The correct regex code should return “1976”, but I am unable to figure that out via chatgpt or any of the other tools online. This file is a bit too complicated to wrap my head around the regex code for this.
Hi @tre, this would be one of the things that are simpler with to extract using the HTML node and a CSS selector. You can use your browser to find suitable CSS selectors (I’ve described this here for example).
Specifically for the “foundedOn” value, a workflow like this should do:
I’ve also included the data from the ld+json script (which holds for example the employee count you were previously reading). This is the result:
the ld+json script worked like a charm using the set node!
I’ve also tried the css selector method you described and I was able to get the values from the htmlextractor, but I noticed a new problem while using the css selector.
When some companies don’t mention certain fields, the arrangement of those values changes. For example, apple’s linkedin has ‘Year Founded’ but Microsofts linkedin doesn’t have ‘Year Founded’
So, when I copy the css selector of the ‘year founded’ with apple as an example and run it for Microsoft, it returns the ‘Specialties’ value as the output.
Here’s the css selector I got from the inspect method using the html file I shared: #main-content > section > div > section.core-section-container.my-3.core-section-container–with-border.border-b-1.border-solid.border-color-border-faint.m-0.py-3.text-color-text > div > dl > div:nth-child(6) > dd
Is there anyway we could make it search the heading and return that output?
I figured it out! Goddamn it…I was using the css selector you shared:
[data-test-id=“about-us__foundedOn”] > dd
on Microsofts linkedin which returned a null value. I thought it was an error, but it just hit me MS doesn’t have year founded on their linkedin. After testing with another property, I realized its working properly.
Thanks a ton for the guidance on this @MutedJam - Really grateful to you.!