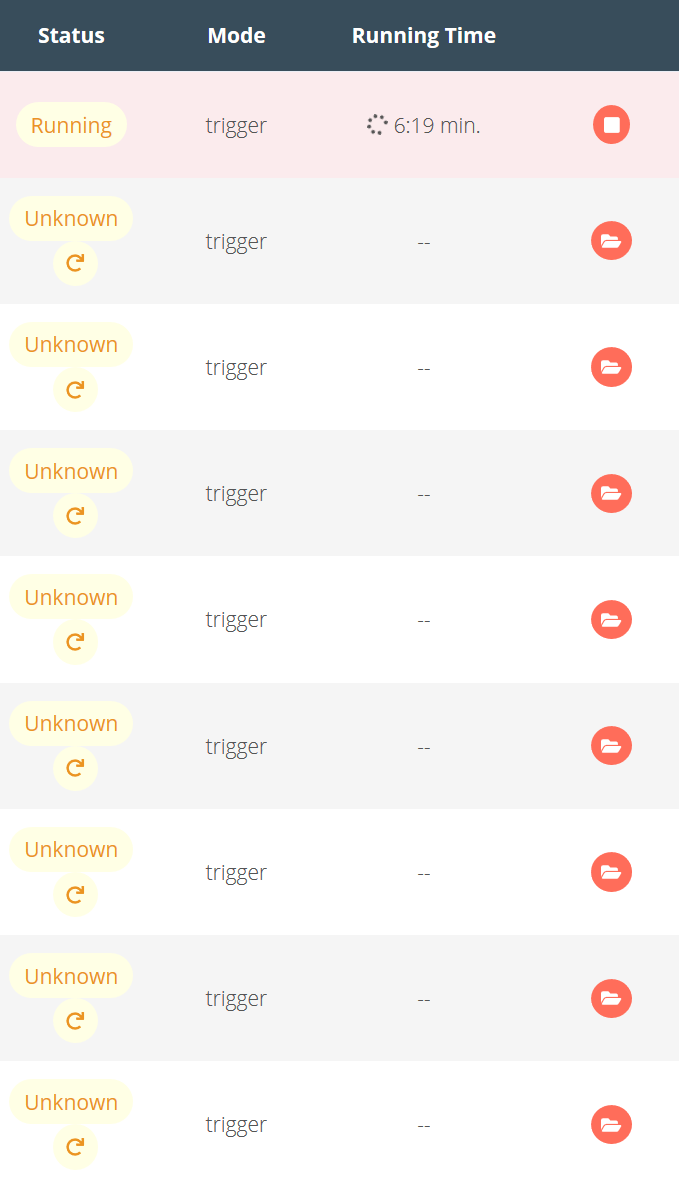
“The workflow execution is probably still running but it may have crashed and n8n cannot safely tell”
My error log file seems to be flooded with Accessing non-existent property 'MongoError' of module exports inside circular dependency
N8N is currently using 3.7GB of ram, Sqlite database was 128GB but vacuumed it back to 13GB
Loading workflows tend to take some time and the execution history window is even worse, Sometimes times out with the error message that the API Server could not be reached
TypeError: Cannot read property 'process' of undefined
at Timeout._onTimeout (/usr/lib/node_modules/n8n/dist/src/ActiveExecutions.js:57:56)
at listOnTimeout (node:internal/timers:556:17)
at processTimers (node:internal/timers:499:7)
ERROR RESPONSE
Error: The execution id "548830" could not be found.
at /usr/lib/node_modules/n8n/dist/src/Server.js:1144:27
at processTicksAndRejections (node:internal/process/task_queues:93:5)
at async /usr/lib/node_modules/n8n/dist/src/ResponseHelper.js:76:26
Very strange. How do you run n8n? Is it running in “main” (so that all execution run in the main process) or “own” (so that all executions start an own process)?
hm, can not think of anything that changed which should cause that behaviour. Can you maybe try setting the environment variable EXECUTIONS_PROCESS=main. That will reduce the number of processes accessing the SQLite DB and maybe could help.
Also just noticed that time-outs seem not to work sometimes due to this, I got 50 second time-outs setup on the workflows, n8n fails to stop them so they keep on running
Actually should running in “main” help. Will reduce the memory and CPU needed, as each process has to load the whole n8n, so if you have 6 running in parallel it has it running 7x (main process + 6 executions) vs. just 1x. Would only cause problems if the workflows are very CPU intensive but the most are normally not, esp. if they talk with some kind of API.
All the workflows are based on data polling to send out notifications and such (Hence why they are executed every minute), Not sure how intensive that is, As soon as i switched to “main” n8n first of all started extremely slow, tried to start all the workflows and crashed shortly after due to memory
The machine running n8n has 6 cores and 16GB’s of ram which i would believe should be sufficient,
I ran htop during both startups (with and without “main”) and main appeared to be using far more system resources
About trying a new database, if i use a new database and activate the workflows all the services which i sent notifications to would be absolutely bombarded since no old execution data is available (Not really an option as this is running in a production enviroment aswell)
hm that sounds strange. Running in “main” is definitely MUCH less resource-intensive. It will need much less RAM as it does not have to start an own process, and also less CPU as the whole starting of the different processes does not have to be done (which will use almost 100% of a CPU for around a second every time). The only disadvantage resource-wise is that it will only use a single CPU (and not all 6), but considering your use case that should not be a problem at all. Even running multiple such workflows a second should not be a problem with “main” at all, while it would for sure be a problem with “own”.
Can not think of a reason why “main” could use more resources than “own”.
Honestly do not understand the part with the new database, seems like you are reading somehow old executions in current ones.
The things mentioned above are the only ideas I have. Interestingly did nobody else report any issues regarding 0.118.1 yet. If really the version update caused the problem it is probably best to roll back the version to the older one and see if the problem disappears again.
What i was referring to with the data was WorkflowStaticData as it’s used to check if new data has being added, If i would use a new database all the StaticData would be lost, correct?
With updating the “Unknown” status appeared, before updating i had a problem with “Error” Statusses which were empty