It would help if there was a node for:
Ollama vision models
My use case:
Currently, image analysis is only available through the AI vendor nodes (Gemini, Anthropic, OpenAI). However, Ollama supports vision models that can analyze images. I’d like to use local Ollama vision models for image analysis.
Any resources to support this?
Are you willing to work on this?
Yes I have actually worked on this but I need some help before continuing
My question:
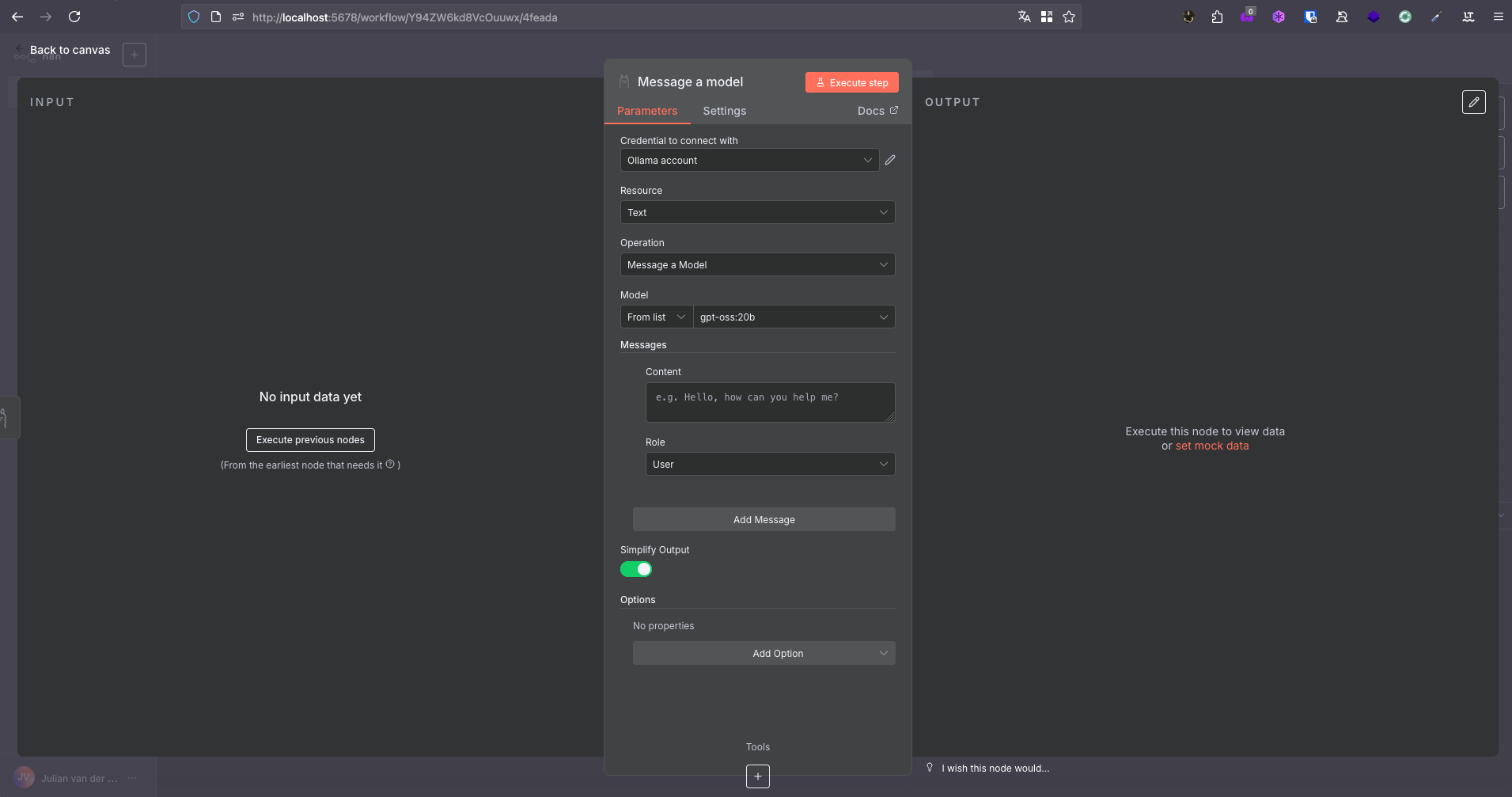
I’ve implemented this by adding Ollama as a new AI vendor (similar to Gemini/Anthropic/OpenAI), which works for vision tasks.
However, I’m questioning this approach because Ollama is not really like the other vendors. The vendor interface also feels empty because Ollama does not have that many capabilities. The other vendors have features such as image generation, which Ollama does not (yet)
Should I continue with Ollama as a separate AI vendor? Or should I change the AI agent node to allow image upload when using an Ollama chat model?
Here is my current implementation:
I have included screenshots.