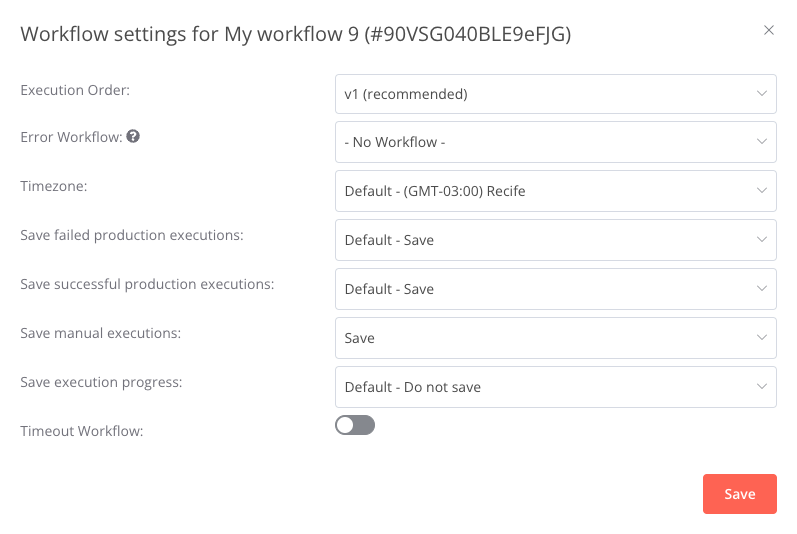
I have a problem scheduling my wait (when it is longer than 65 seconds)
As soon as I update or downgrade my Stack everything works as expected but, after a few hours, the flows do not continue after the wait, I have tried to look for a logic for the failure but without success.
I also noticed that when wait is not working, when I look at the logs in Docker, it does not update in real time, I need to exit and click on log again, when wait is working the logs appear alone at the same time. time that executions begin.
Is there a chance you’re using n8n with an unstable network connection preventing your worker from picking up the job as it should? Are you also seeing this behaviour when not using queue mode (and instead have your main instance execute the jobs)?
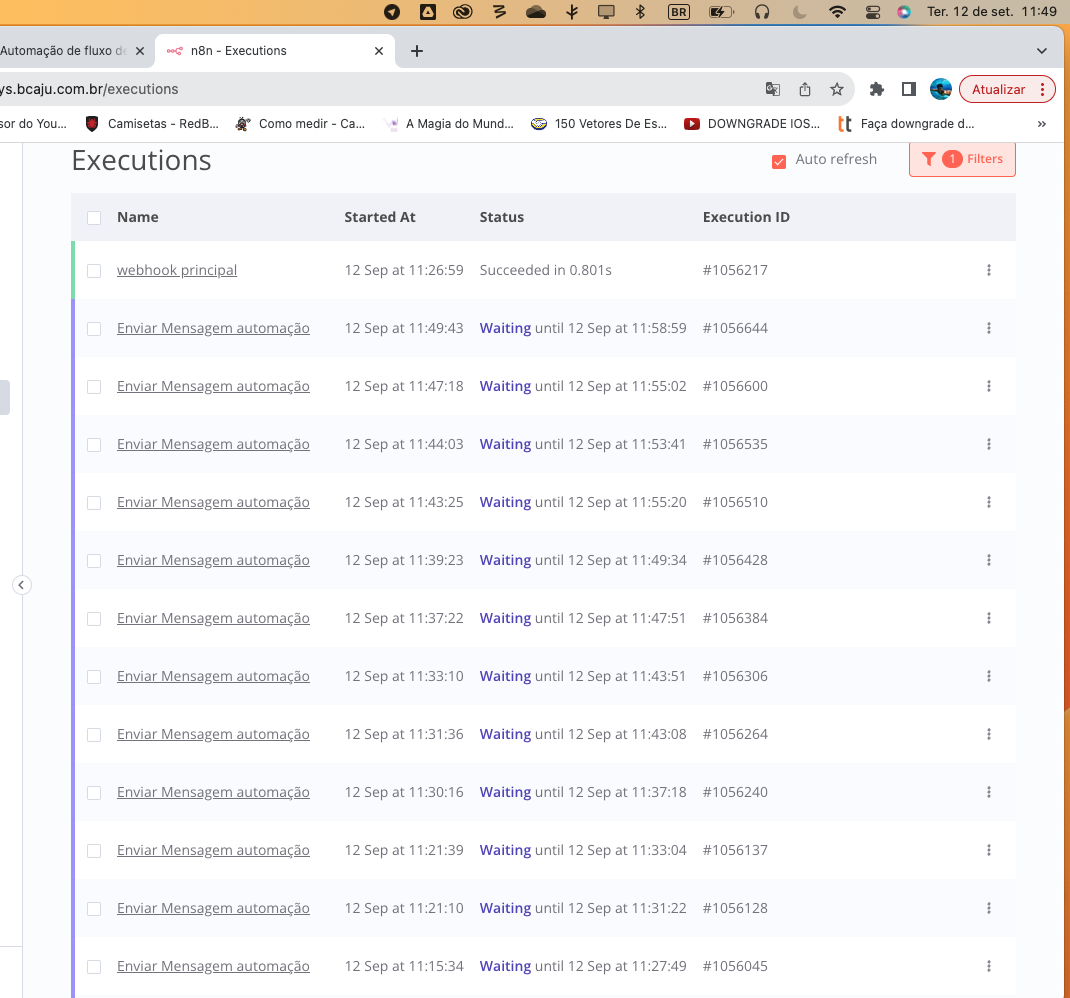
I believe it is not a case of instability in the connection, as I believe that this way it would only fail sometimes, and in this case, at some point all “wait” stops working, as you can see in the image below.
when I update or upgrade the n8n version and everything works perfectly for some time, for example yesterday I updated the n8n at 4:00 pm and it was working perfectly until today at 10:30 am, when they all stopped working.
Could you create an automation that generates several of these “waits” for the next 24 hours?
Could you share the stack you used in your installation?
In which database table and column is the data from a wait schedule saved?