We are running n8n in queue mode with two worker nodes.
We use the WAIT node to wait for more than 65 seconds. But when we the time to resume the workflow comes, both the workers are picking the job and are running this. This results in workflow getting executed 2 times.
How can we prevent this double execution?
Note - This does not happen if I run just 1 worker node
What is the error message (if any)?
NA
Please share your workflow
NA
Share the output returned by the last node
NA
Information on your n8n setup
n8n version: 0.236.0
Database (default: SQLite): postgres
n8n EXECUTIONS_PROCESS setting (default: own, main): NA
Running n8n via (Docker, npm, n8n cloud, desktop app): Docker
You are on an older verison of n8n so I would start with an update and see if that helps, Can you also share the configuration you are using for the workers and main instance and we can see if we are able to reproduce this.
Can you let me know how I can run multiple worker nodes in my local machine? I will try to reproduce this locally and will be able to share more details.
Are you able to find out how you have n8n deployed at the moment? I suspect someone would know and it would be very handy to have that information so we can try to reproduce this. If you want to try and reproduce this on your own you can follow the queue mode docs we have on our site but to be honest it would be more useful to know the actual details of how you are running it now.
We have a kubernetes setup of n8n where we have used official helm chart v0.136.0 for n8n v0.236.0.
Execution Mode - Queue
Docker Image - n8nio/n8n:0.236.0
Horizontal Pod Autoscaling configuration (HPA) for worker - min 2 & max 4
Redis is running in Standalone mode within that kubernetes cluster
That post seems unrelated and is more around webhooks and calling them rather than wait nodes. The settings you gave look like they should be ok, What does the workflow look like in the execution log?
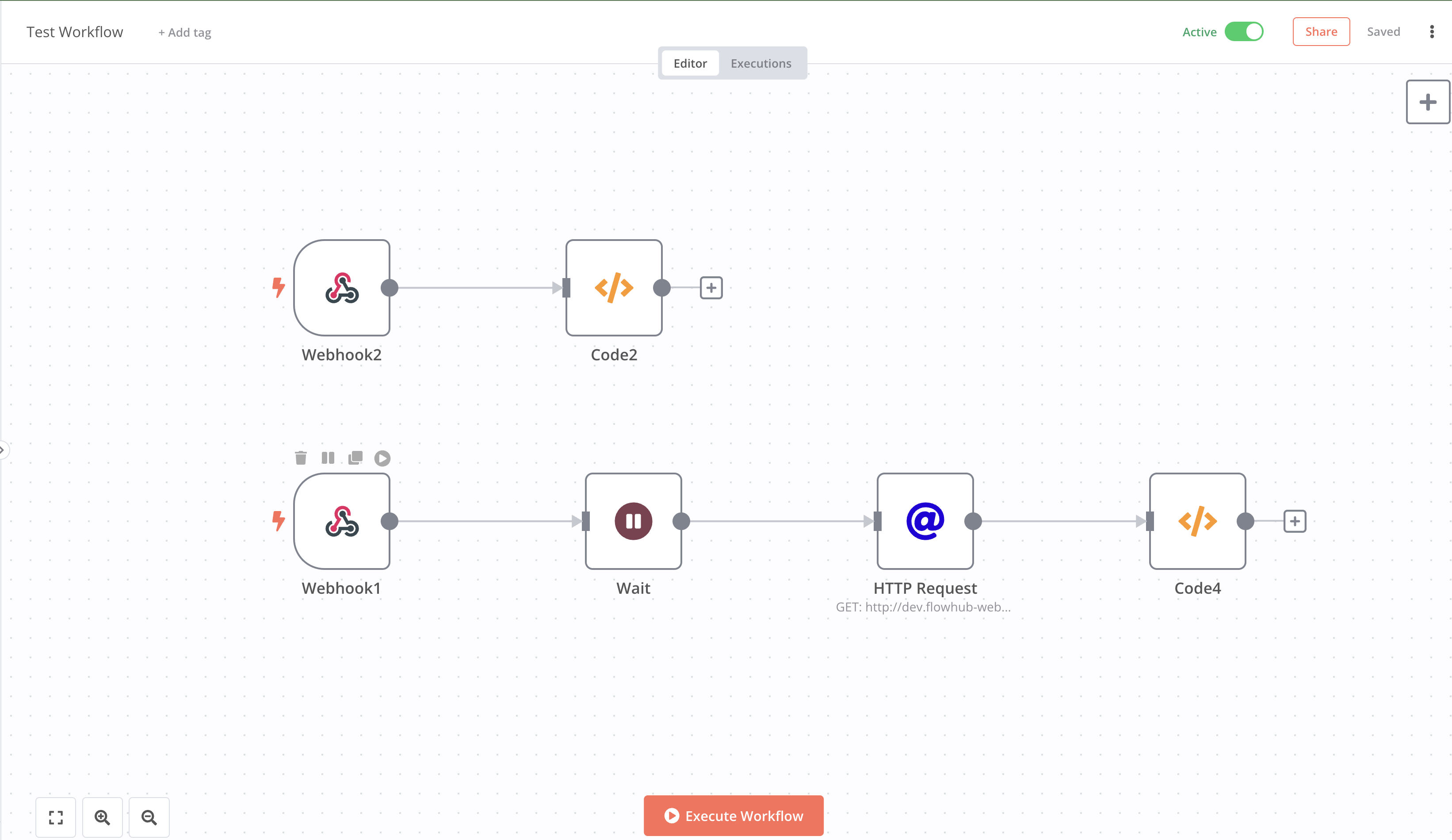
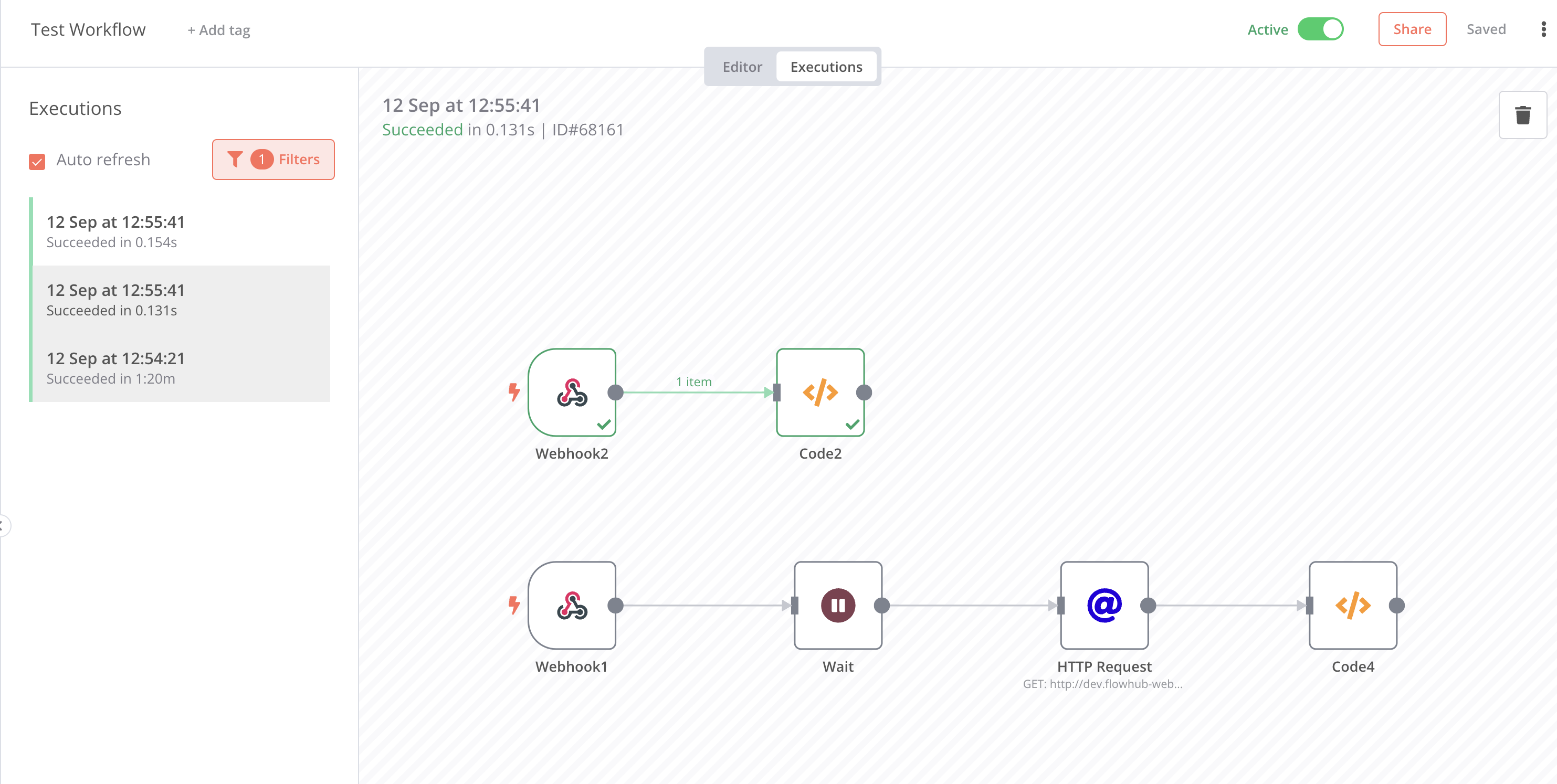
I was able to reproduce this with a simpler workflow while having 2 worker nodes.
In this case, Webhook2 is called twice after wait time (from flow with Webhook1 as starting node).
Description of Workflow:
Flow which has webhook trigger “Webhook1” has the does the following
I have just given this a go and for me it is only running once, Can you share your helm chart so I can see how you have the workers running? Do you also have multiple webhook workers or is it just the one?
At the moment this looks like it could be a configuration issue but you are also on an older n8n version so it could be worth trying a newer release.
Instead of calling a webhook could you try the execute workflow option and try calling another workflow that way to see if that also results in the triggering happening twice.
Yes, we are currently running 2 instances of main, webhook and worker containers in our Kubernetes cluster. Please let me know if you need any other information.
Also regarding the usage of latest version - Please confirm if this docker image (1.6.1) is the latest stable version to use for production environment.
Just to check something there… Are you sure you are running 2 main instances of n8n? We only support running one and having 2 can cause issues, I would double check this and make sure you only have the one main instance.
We consider any version tagged as latest to be the version to use for production but normal best practices would apply so make sure you upgrade a test environment first and do any testing you need to do before signing it off for yor change.
As you are moving from pre v1 to v1 you will also need to follow the migration guide as v1 contains a number of breaking changes.