We are having an issue when processing 10k records. the flow works fine, but then when it is done it causes crashes because of Memory usage. Without Queue mode enabled it is fine.
Below Is all from the same server I have updated the server to version 235 but results are the same for 225 and 228.
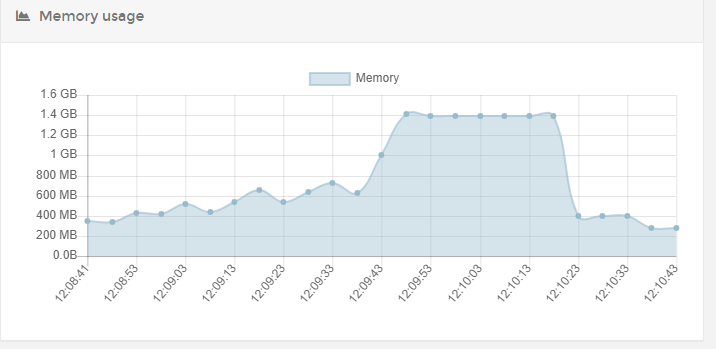
There also seems to be a dip before it peaks. and the executions are actually completed succesfully according to the executions tab.
Please let me know if you need any further info.
Queue Mode
1st run with limited data
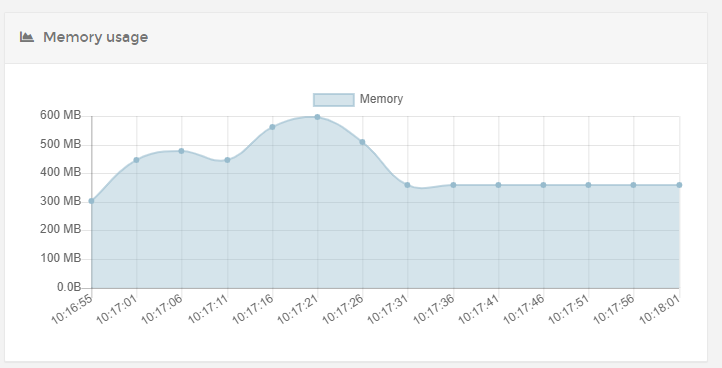
2nd run with 2x the data
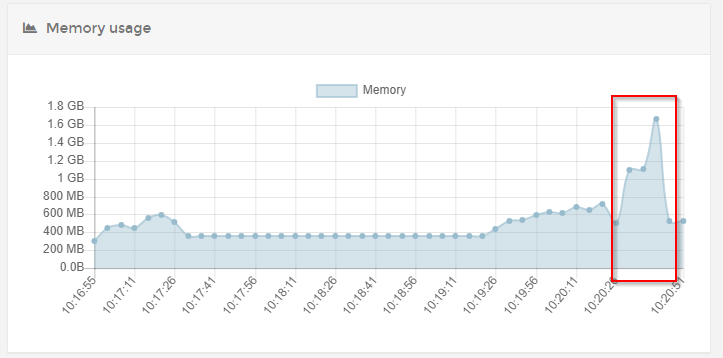
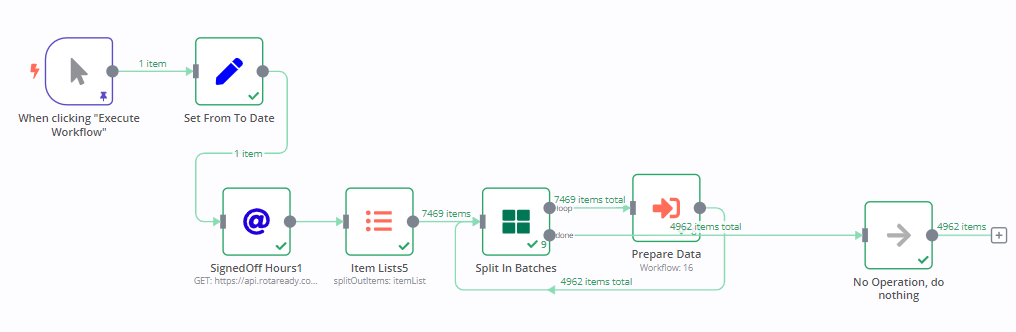
You can see that the normal usage is a bit higher as expected but now there is a huge spike after the workflow was done as marked in the image.
I do understand that the graph doesn’t tell the full story but it is quite worrying.
3rd run with a bit more data (normal load for this flow, excluding the rest of the flow at noOp)
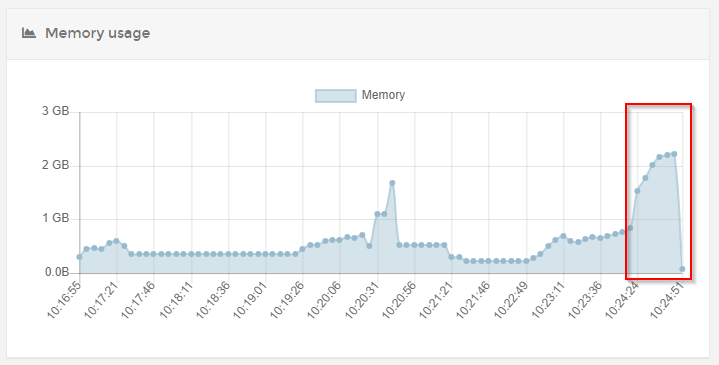
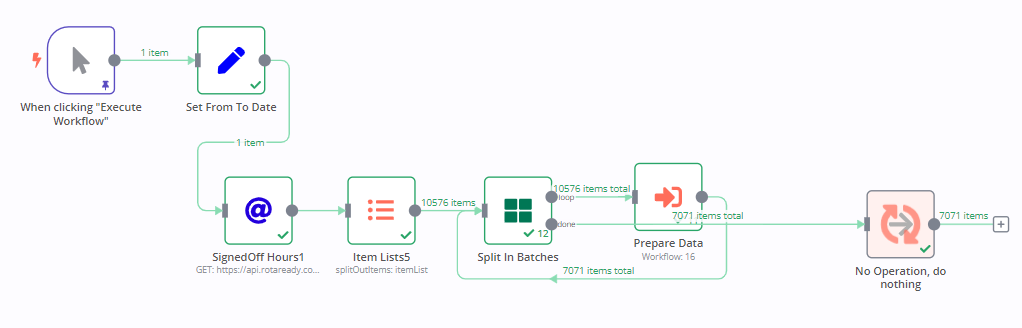
So another graph that shows a bit more data as is expected and then another huge peak after the workflow was done. Execution logs show succesful workflows for all of the above
Regular mode
Run with the same data as 3rd from above, same server same verything except Queue mode disabled.
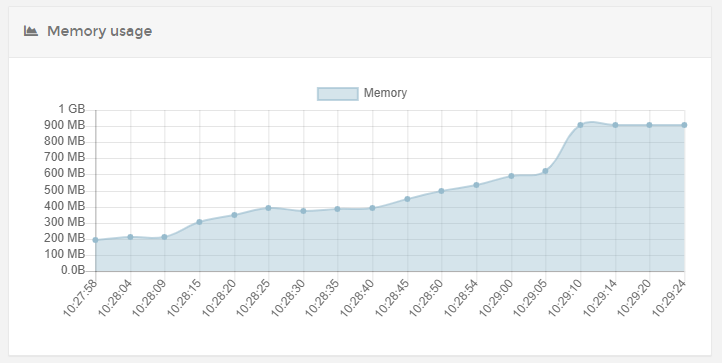
No issue at all, there is a jump but nowhere near as extreme as the one in Queue mode.
Server info:
AWS EC2
2vcpu
4Gb
We had a similar issue with Garbage collection with 1vcpu or less. So this could be the issue again but it seems very odd to me.
Information on your n8n setup
- n8n version: 225 + 228 + 235
- Database (default: SQLite): Postgres (amazon RDS)
- n8n EXECUTIONS_PROCESS setting (default: own, main): Queue
- Running n8n via (Docker, npm, n8n cloud, desktop app): Docker
- Operating system: Docker Default image of n8n