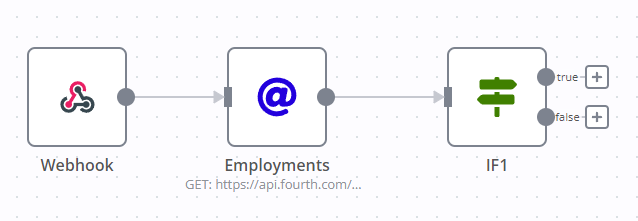
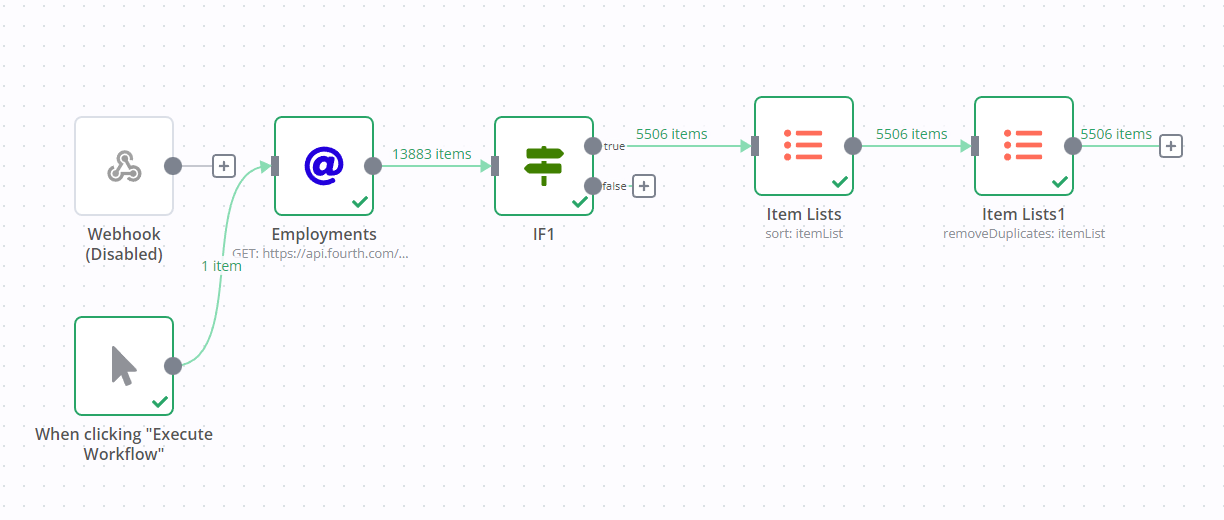
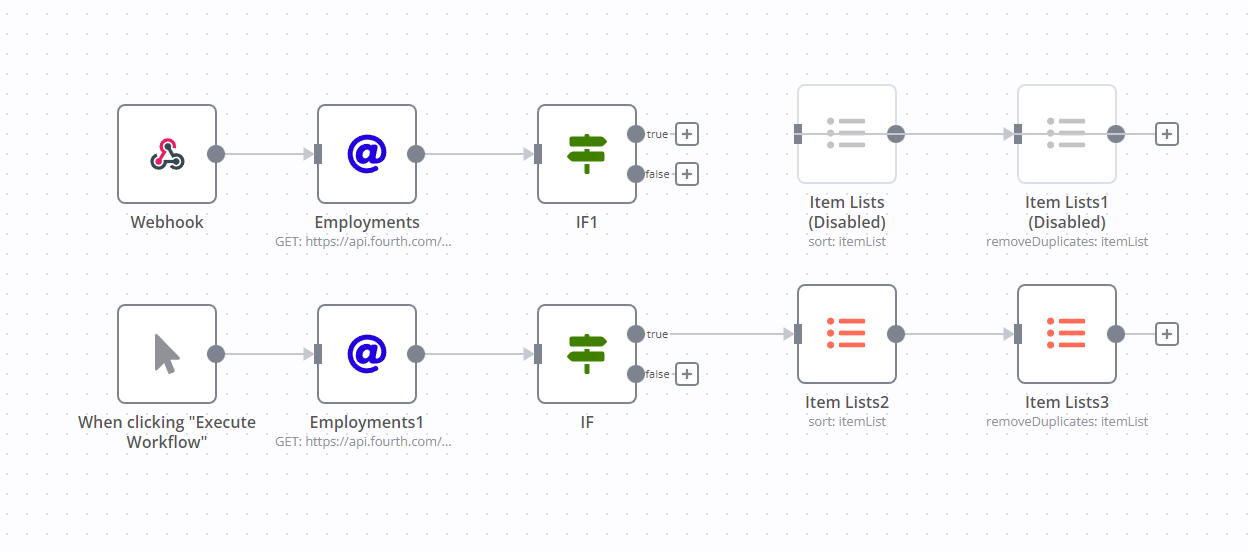
You should try to break up your workflow into smaller data units, using the Split in Batches node, it’ll help you process the same amount of data but use a bit less memory
Really super confusing! Never seen that before. Are you really sure that all n8n instances are running the same n8n version? Is there for sure nothing else on the worker running which eats up memory?
I’ve now made my own test data set and ran a flow on my own server and the AWS server. The differences are the hosting and also the version. My own server is on the latest (220) version.
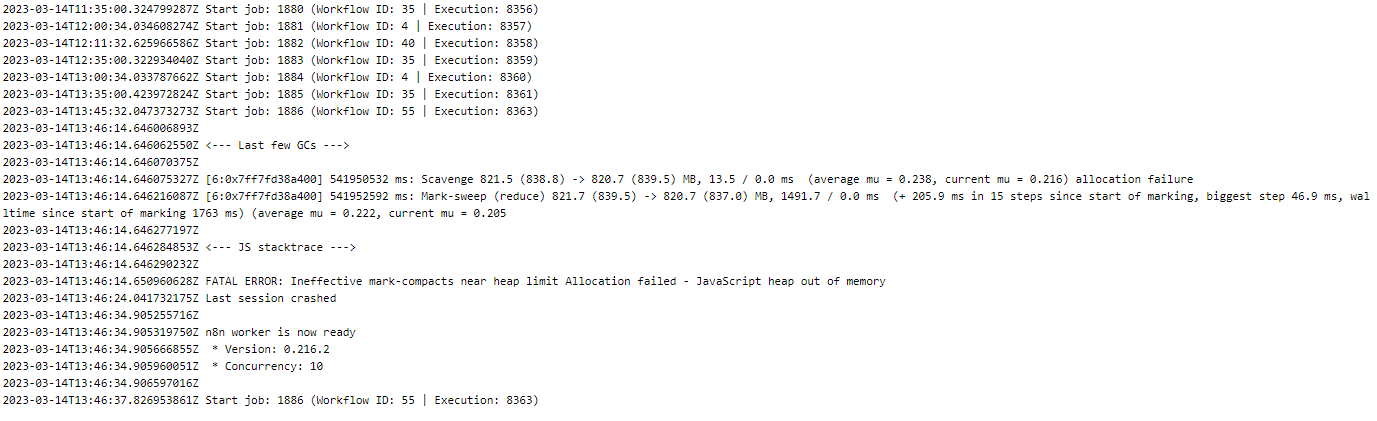
The difference is extreme. Can it be the version (216.2)?
I will update when I can, but couldn’t do it right away.
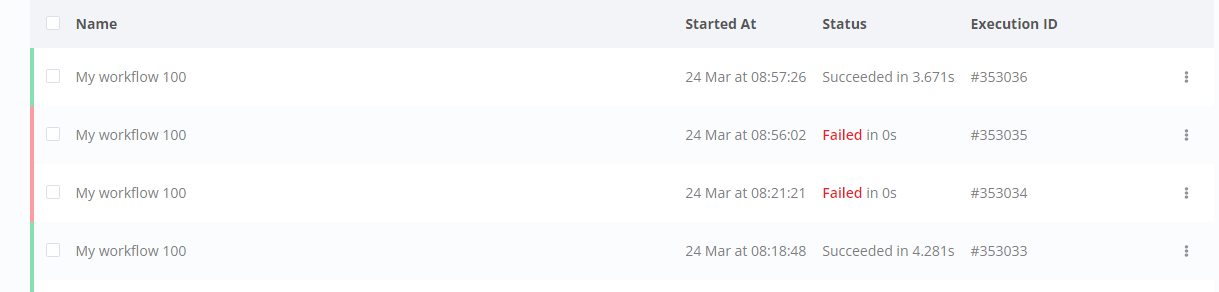
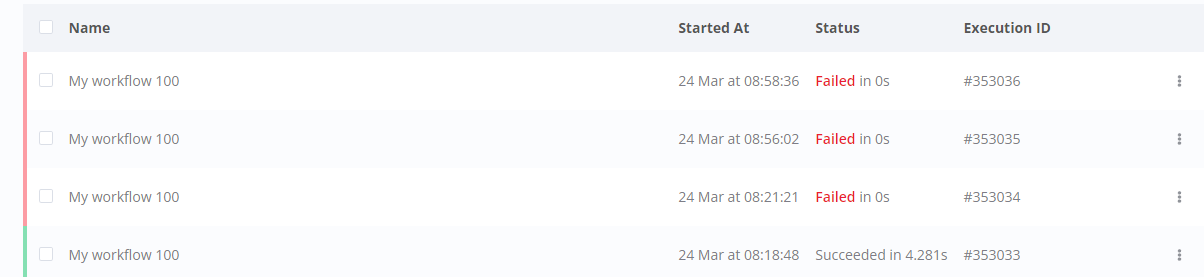
workflow
@BramKn Can you please also try versions 0.217.2, 0.218.0, and 0.219.1?
There are way too many changes between 0.216.x and 0.220.x. If you can help us narrow down the issue to a specific version, that could really help find what’s causing this.
The issue exists on 216 and on 220. So not sure what it will add to the conversation if I also test the ones in between.
Of course I can but will take some time, so I want to make sure it is useful.
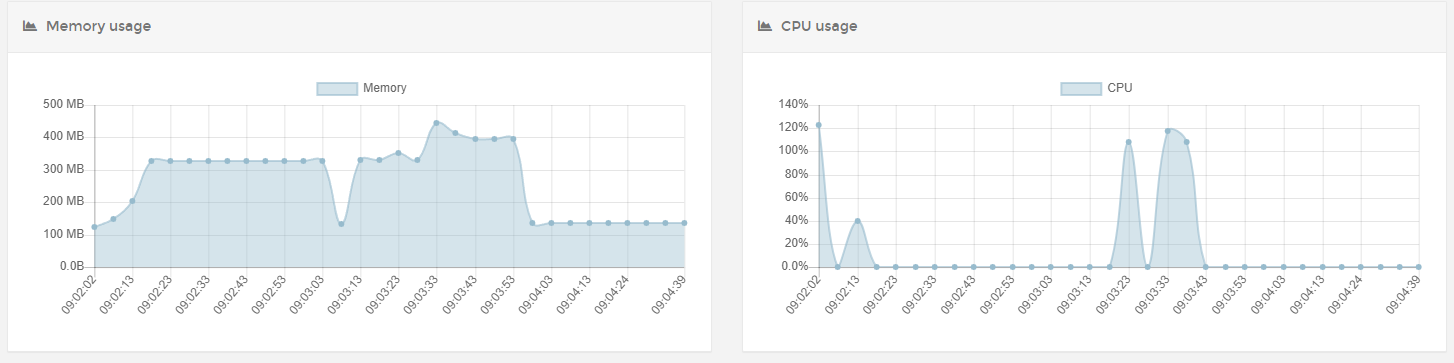
Not sure if you noticed, but the issue seems to be specific to AWS lightsail.
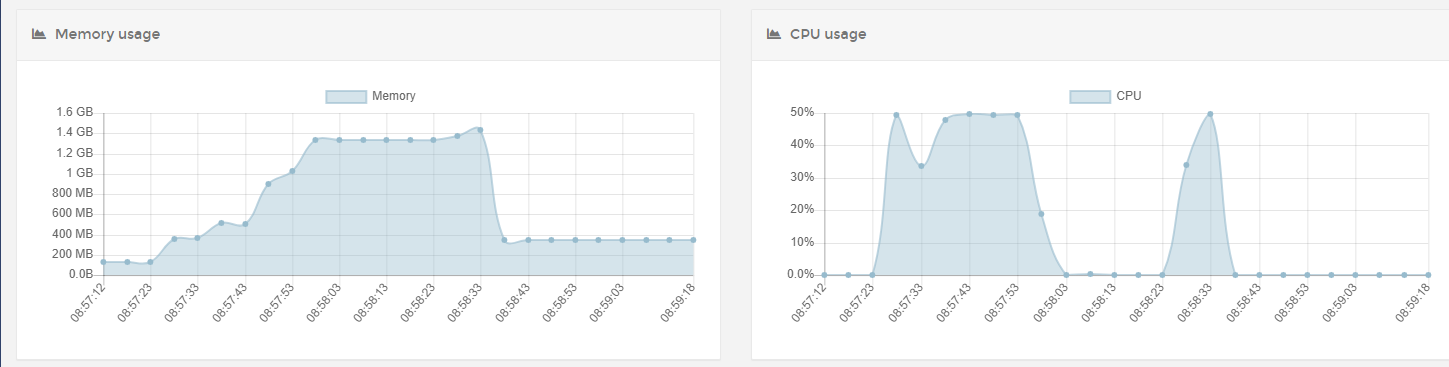
The only major difference between Lightsail vs a local server would be the amount of CPU available, which lead to difference in performance during garbage collection.
Considering the size of the JSON file being downloaded in the HTTP Request node, and that the Lightsail server has likely only one core available, I have a strong suspicion that garbage collection has something to do with this issue.
The reason I asked for testing other versions was because somehow I got the impressions that things were better before 216.2. But now that I read the thread again, I’m not sure what made me come to that conclusion. Sorry about that.
That said, I’m still not sure why queue mode would take more memory than main mode in this case
That is a good catch.
Then I would be able to reproduce it by limiting the cpu on my instance to see what it does I guess?
It is queue worker (activated triggered with webhook) vs queue manual trigger.
I am going to do a bit more testing tomorrow to see what I can find out.
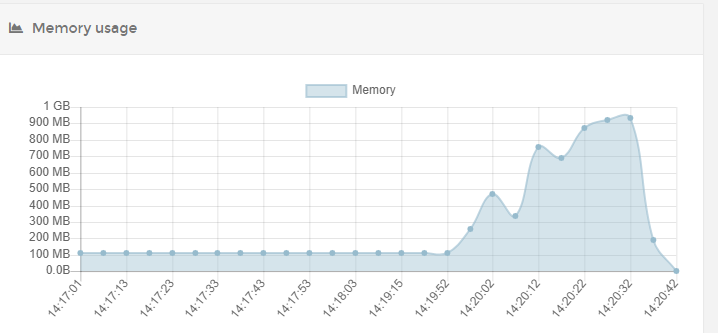
So you were right. Put my server on .5 cpu, and got the same result. now not crashing as it actually had more RAM to play with but you do see that the RAM goes up a lot.