Thx you very much for your answer.
Ok now i get to understand better why it keeps lasting for longer time than the defined timeout.
I had the idea of slit in batch already .
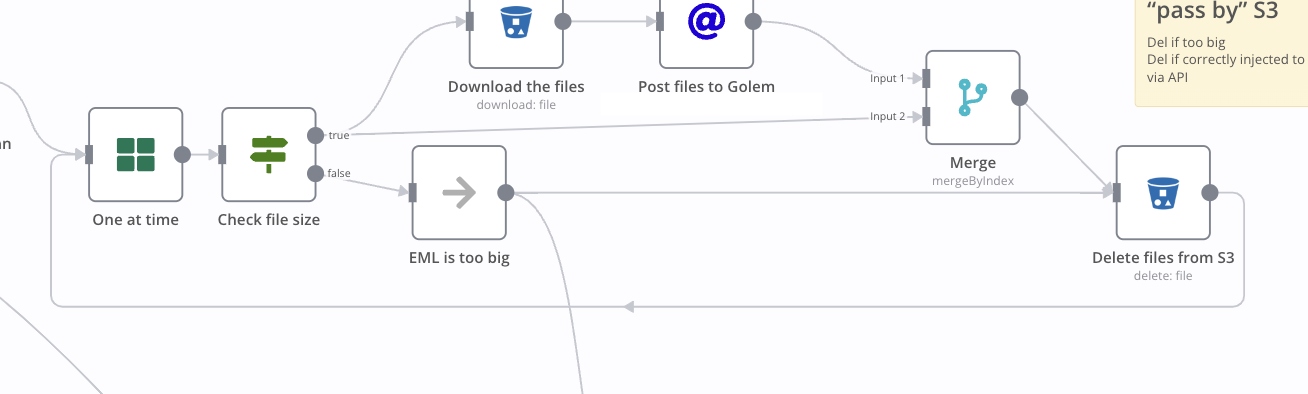
But sometime, you know, one node last for ever because something went wrong and that’s what happended with my “delete file” node.
It’s disappointing that i can’t easily implement the “Fail fast and retry” principles setting up timeouts.
Thanks a lot for you time i’ll take a look to check how to works around the S3 default timeout using the HTTP node as you advice it to me in my other ticket.
Cheers have a great day .
William