Describe the problem/error/question
We are running a self-hosted n8n installation and are currently configuring queue mode with task runners for production scalability. However, we are experiencing a critical issue where workflows get stuck in the queue indefinitely and never complete execution. This affects all workflow types (manual, webhook-triggered, and scheduled executions).
Key symptoms:
- Workflows are enqueued successfully (we see “Enqueued execution X (job Y)” in logs)
- Workers never pick up jobs from the Redis queue Executions remain in “running” state indefinitely
- No actual workflow execution occurs
Infrastructure details:
- Multi-service architecture: Master (UI), Webhook, and Worker services
- All services deployed on AWS ECS Fargate
- Redis (AWS ElastiCache) as queue backend
- PostgreSQL (AWS RDS Aurora) as database
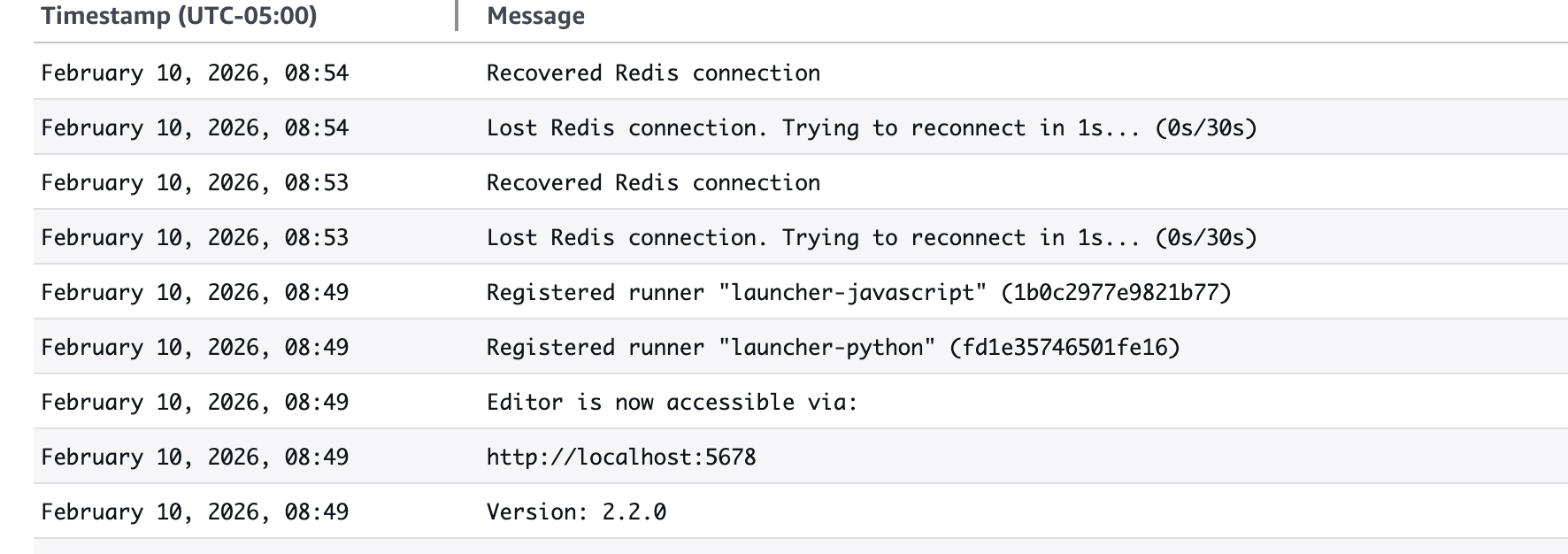
Pattern: Redis connection drops occur every 1-3 minutes across all services, followed by immediate reconnection.
What is the error message (if any)?
Master service logs:
Lost Redis connection. Trying to reconnect in 1s... (0s/300s)
Recovered Redis connection
Error handling CollaborationService push message
Error: Error handling CollaborationService push message
invalid input syntax for type uuid: "undefined"
Worker service logs:
Lost Redis connection. Trying to reconnect in 1s... (0s/300s)
Recovered Redis connection
Last session crashed
Please share your workflow
This issue affects ALL workflows regardless of complexity. Even simple test workflows with a single HTTP Request node get stuck in queue.
Share the output returned by the last node
No output is generated because workflows never execute - they remain queued indefinitely.
Information on your n8n setup
- n8n version: v2.0.0
- Database (default: SQLite): PostgreSQL (AWS RDS Aurora)
- n8n EXECUTIONS_PROCESS setting (default: own, main): own
- Running n8n via (Docker, npm, n8n cloud, desktop app): Docker containers on AWS ECS Fargate
- Operating system: Linux containers
Environment variables by service:
Master service (exclusive variables):
N8N_WORKER_MODE=master
N8N_DISABLE_PRODUCTION_MAIN_PROCESS=false
Webhook service (exclusive variables):
N8N_DISABLE_PRODUCTION_MAIN_PROCESS=false
Worker service (exclusive variables):
N8N_DISABLE_PRODUCTION_MAIN_PROCESS=true
N8N_CONCURRENCY_PRODUCTION_LIMIT=-1
Runner service (exclusive variables):
N8N_RUNNERS_AUTO_SHUTDOWN_TIMEOUT=0
Shared environment variables (all services):
Database Configuration
DB_TYPE=postgresdb
DB_POSTGRESDB_HOST=xxyyzz
DB_POSTGRESDB_PORT=5432
DB_POSTGRESDB_DATABASE=automation
DB_POSTGRESDB_SCHEMA=public
DB_POSTGRESDB_SSL_REJECT_UNAUTHORIZED=false
DB_POSTGRESDB_POOL_SIZE=10
DB_POSTGRESDB_CONNECTION_TIMEOUT=20000
Redis Queue Configuration
QUEUE_MODE=redis
QUEUE_BULL_REDIS_HOST=xxyyzz
QUEUE_BULL_REDIS_PORT=6379
QUEUE_BULL_REDIS_USERNAME=default
QUEUE_BULL_REDIS_TLS=true
QUEUE_HEALTH_CHECK_ACTIVE=true
QUEUE_BULL_REDIS_CONNECTION_TIMEOUT=30000
QUEUE_BULL_REDIS_TIMEOUT_THRESHOLD=30000
QUEUE_BULL_REDIS_DB=0
Execution Configuration
EXECUTIONS_MODE=queue
OFFLOAD_MANUAL_EXECUTIONS_TO_WORKERS=true
N8N_RUNNERS_ENABLED=true
N8N_RUNNERS_MODE=external
Network & URL Configuration
WEBHOOK_URL=https://n8n-webhook.company.io
N8N_EDITOR_BASE_URL=https://n8n.company.io
N8N_HOST=n8n.company.io
N8N_PORT=5678
N8N_PROXY_HOPS=1
Security & Permissions
N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
N8N_BLOCK_ENV_ACCESS_IN_NODE=true
N8N_GIT_NODE_DISABLE_BARE_REPOS=true
Operational Settings
N8N_METRICS=true
N8N_GRACEFUL_SHUTDOWN_TIMEOUT=30
License Configuration
N8N_LICENSE_AUTO_RENEW_ENABLED=true
N8N_LICENSE_DETACH_FLOATING_ON_SHUTDOWN=false
Custom Nodes Configuration
N8N_CUSTOM_EXTENSIONS=/home/node/.n8n/custom
Architecture:
- Master service: Handles UI and API (1 instance)
- Webhook service: Handles webhook endpoints (1-3 instances, auto-scaling)
- Worker service: Processes queue jobs (1-3 instances, auto-scaling)
- Runner service: External task runners
Has anyone experienced this behavior before? Looking at our environment variables configuration, do you notice any obvious misconfigurations that could prevent workers from picking up jobs from the Redis queue? We’re particularly concerned about the frequent Redis reconnections and whether our queue mode + task runners setup might have conflicting settings.