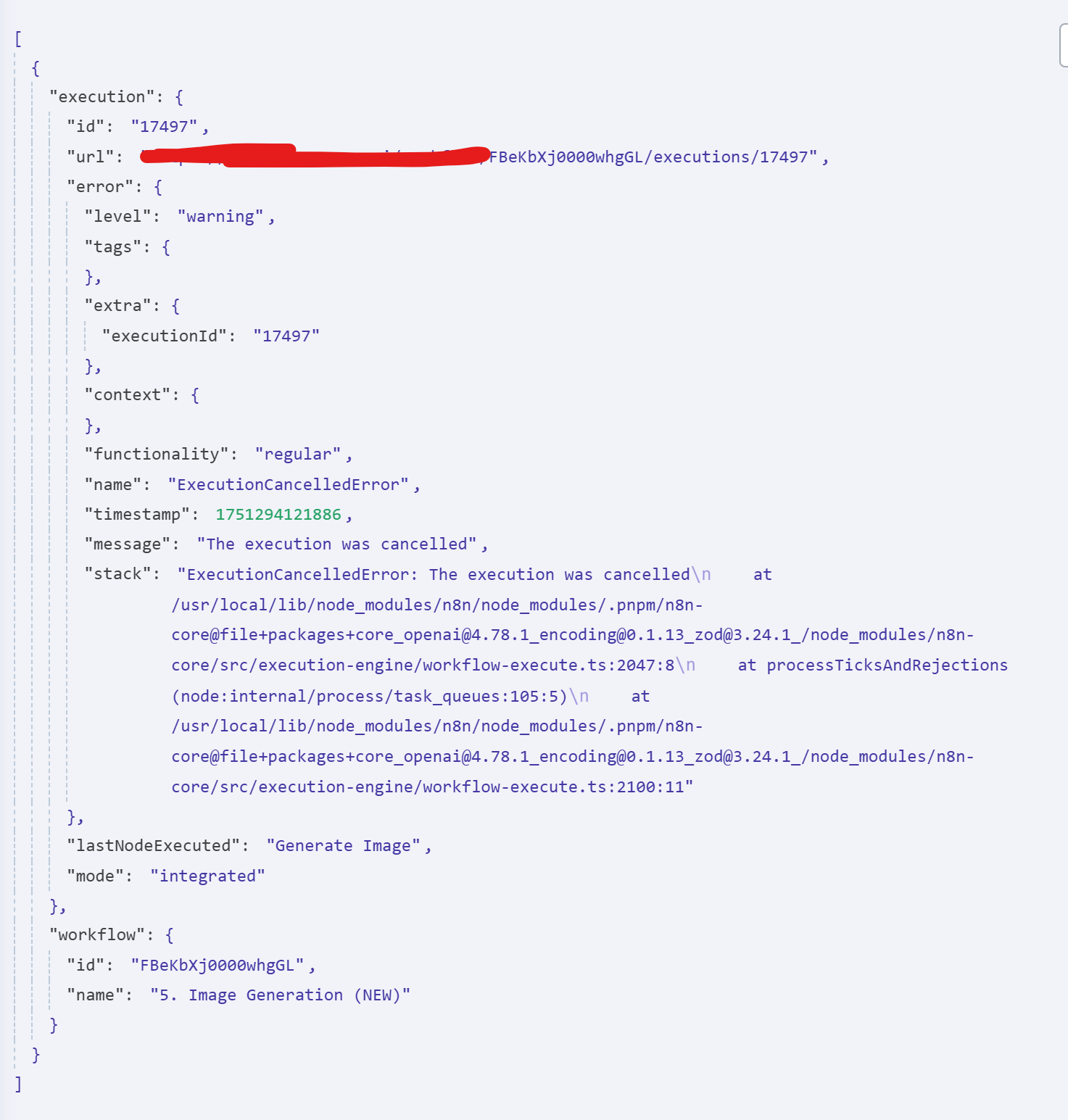
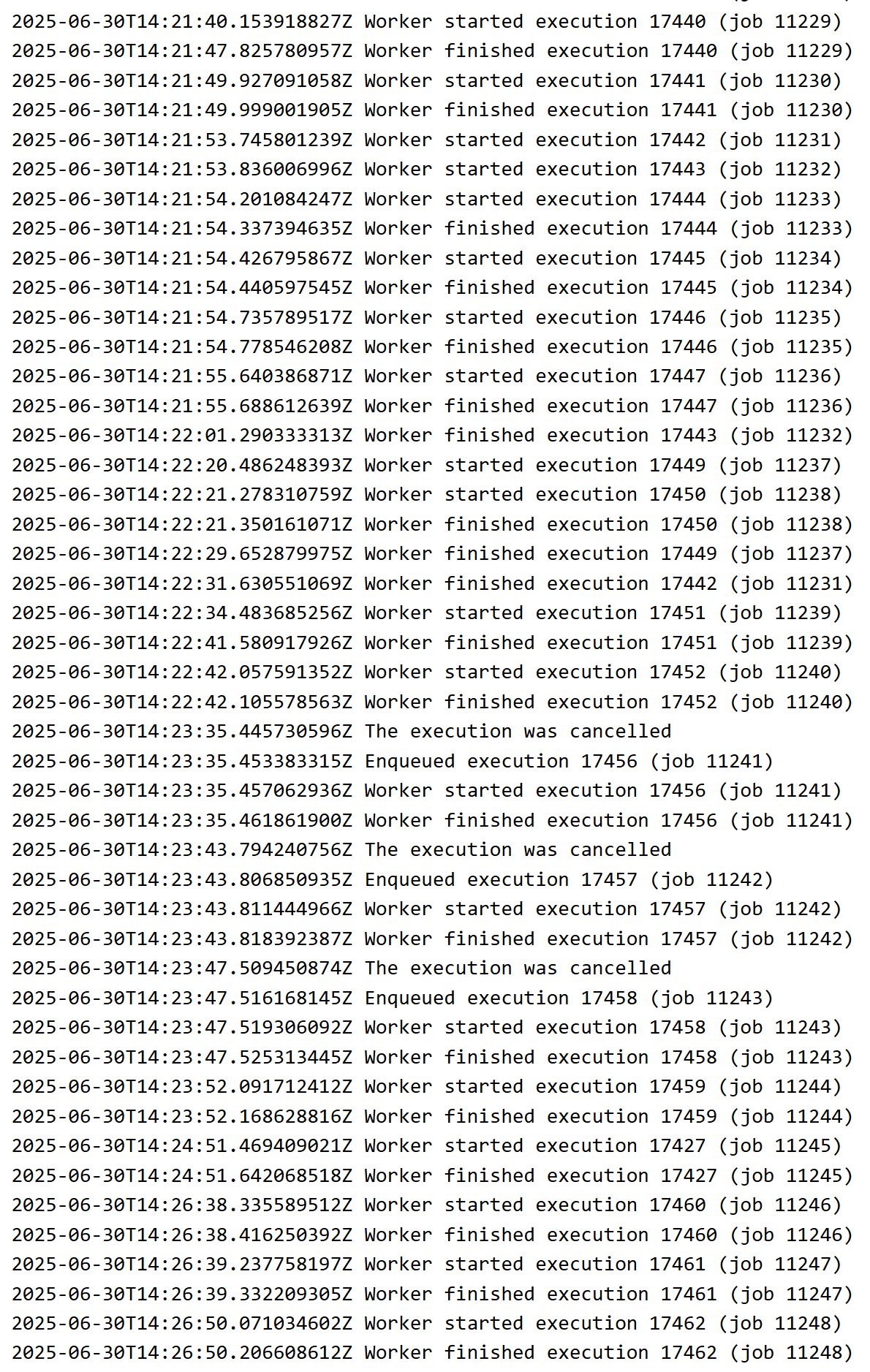
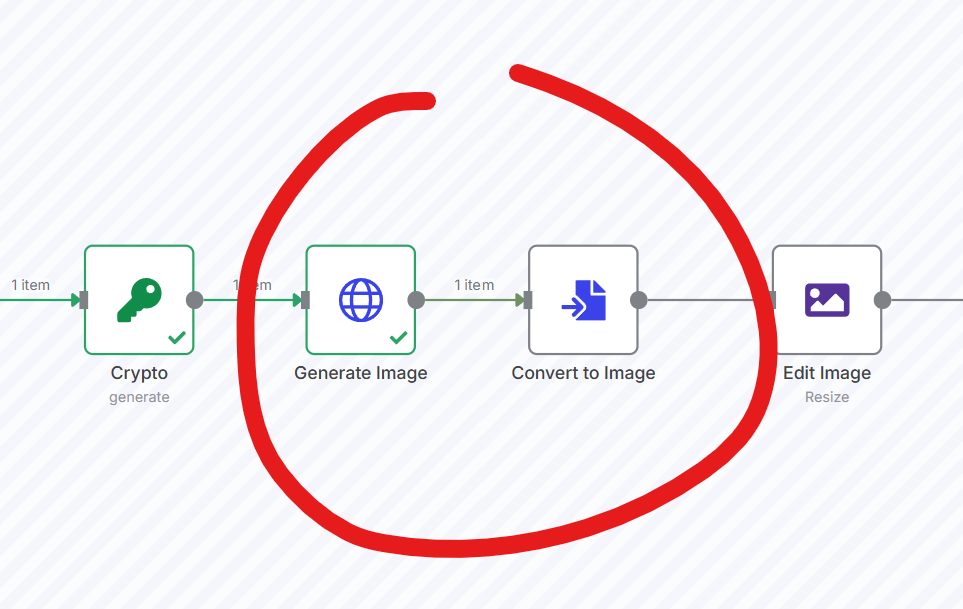
I feel like I’m facing a pretty big bug potentially within my N8n workspace. A bunch of workflows are just randomly getting canceled in workflows that just haven’t been edited or touched in many days.
This was happening on version 1.98.1, and the version was working perfectly fine until late last night when all of a sudden I wake up to multiple workflows just being spammed with canceled executions. Of course, no one was cancelling the executions. I’ve upgraded to the latest n8n version to no improvement.
It doesn’t even show that anything went wrong within the execution, it shows that all the nodes were working perfectly, and I can’t figure out why this is happening. It also pushing to the error workflow, but with to clear information.
Also just checked another install of n8n, completely separate sever, completely separate environment.
This time, it’s showing an extreme amount of errors on workflows that have completed successfully. Also showing an extreme amount of time that the workflow ran. The workflow below on average will not take more than 100ms, yet it’s showing absolutely crazy runtime.
Also, none of these errors triggered the error workflow set.
It’s nothing to do with Supabase. My Supabase instance is pretty rock solid. It is also self hosted and doesn’t show errors anywhere.
When you look at where the workflow is stopping, it’s after a successful image generation. It just needs to convert the Base64 string to a file, which it gets the string, but just cancels the workflow for some reason and never actually attempts to convert it to an image
Thanks for that clarification! Now I’m leaning towards a memory issue during Base64 conversion.
The image generation works fine, but when your worker tries to convert that Base64 string to a file locally, it’s probably hitting memory limits - maybe not every time, but when images are larger.
Quick tests:
Try generating smaller dimensions temporarily (512x512 vs 1024x1024+)
Add a Code node before conversion to check base64String.length
Monitor worker memory usage during conversion (htop)
Large Base64 strings can spike memory usage significantly.
That’s all I can say for now. More research is needed.
It’s a bit odd because it’s been working fine for the past month and only last night has the issue begun.
I’m hosting n8n on a dedicated sever, 4vcpu 16gb memory 160gb storage, and I currently have 10ish gb of memory free, so I assume n8n has more than enough to deal with