Situation
First I want to clarify that I’m not trying to bad-mouth anything. n8n from what I have seen so far is an amazingly powerful tool for automation.
I’m currently evaluating whether n8n is something we could use for our integrations, but I more and more stumble upon issues when combining n8n with big datasets (> 200.000 entries). Please do correct me if any assumption here I make is wrong and could have been fixed by me missing that one specific setting changing it all.
Node / Typescript
I am all for browser applications, but I strongly doubt that processing larger data with for example the merge-function using node or the client-browser is a good idea. As soon as you work with larger datasets and you try to merge them you will obviously run into issues, as you are limited by the one-threaded nature of it all.
This also means the execution will always be extremely slow as soon as n8n needs to execute something itself like Code, Merge, … or the the browser straight up crashes due to the load when building the workflow. It is already very suspect to me that the browser application is it not lightweight at all and actually does seem to execute code and contain the data of the workflow at all times, which is entailing the need to introduce cloud- or on-premise services handling the heavy-lifting for n8n.
Also, looking at the merge-function again we can also see that its potentially going very, very deep into the stack when working with/on bigger data, prompting for the need to increase the stack-size in node. Otherwise we would run into stack size issues.
Consequences
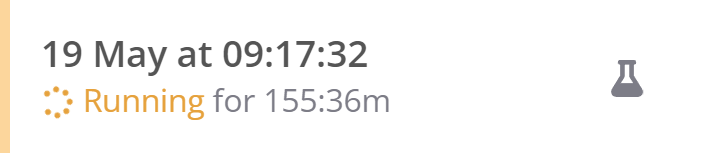
Workflows are unstable and have a very high chance to run indefinitley. Trying to stop the workflow does not work.
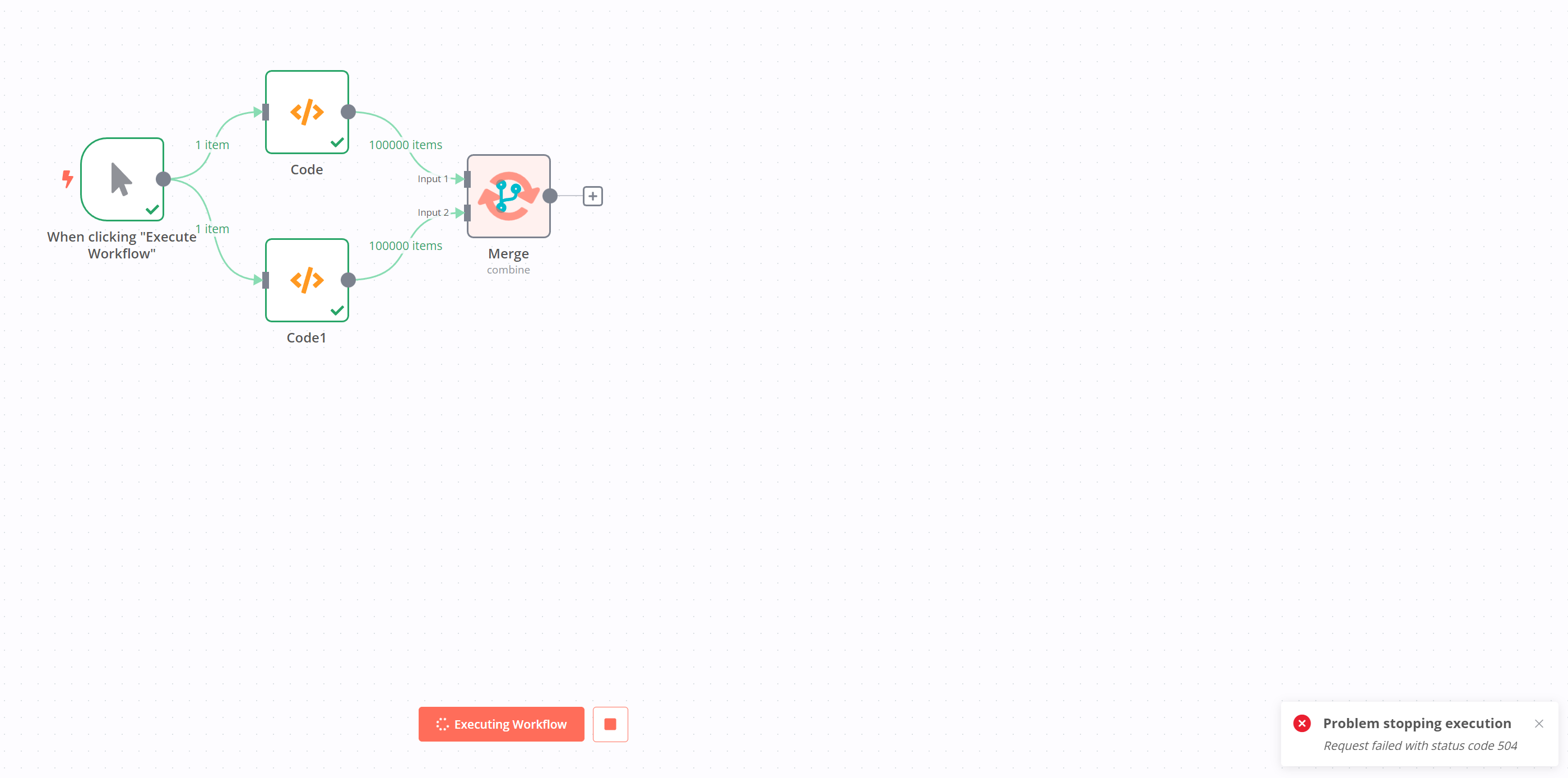
There is a big chance the site crashes when trying to interact with it while it is executing code or merging.
Extremely long execution times
Node stack-size issues

Ghost workflows that can not be deleted anymore and do not resolve themselves.
Conclusion
To bring the post to a question, are there any active plans to better improve for scale or will n8n be a use-case for smaller workload only?
As of now it seems like a fundamental technical limitation that could only be changed with a major overhaul of the system and its inner workings and it’d be understandable if that is not a current focus at all.
Information on your n8n setup
- n8n version: 0.227.1
- Database (default: SQLite): SQLite
- Running n8n via (Docker, npm, n8n cloud, desktop app): Docker
- Operating system: linux