Problem:
Some of our connected systems / APIs are sometimes not reachable for a couple of minutes. Hence I have to restart the failed executions by hand as soon as possible.
Idea / Solution Proposal:
It would be cool to have some kind of “Retry Policy” on a workflow basis to define per Workflow …
if it should be retried automatically or not and
how often and with what delay it should be retried
Unfortunately there is no CLI command to retry an execution, so I cannot build it myself.
Is it a valid idea? Anybody with same or similar issue?
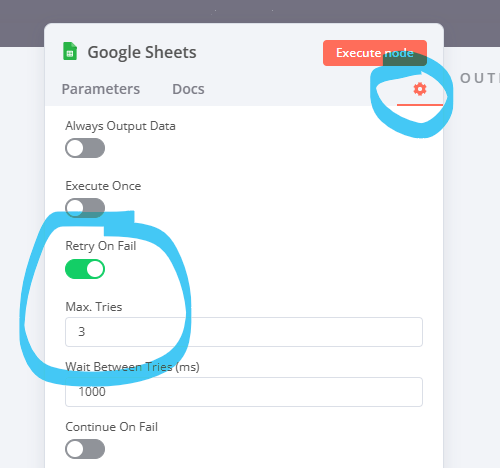
I have only just realised that there is a “Retry on Fail” in the nodes. Do you think it is possible to use this so that the API is requested again three times at five-minute intervals?
I think n8n should get to a point where certain process elements run on a meta-level. If I need companion nodes for each API node for …
data validation
data preparation
error handling
retry in case of error
then my workflow increases very quickly. A retry should not be part of the operational process, because you would copy an awful lot of nodes and the process would become very confusing.
While it’s possible at the moment with if + function nodes for shorter periods, totally agree that flexible retrying should be more intuitive to setup.
In the shorter term, would improving the “Retry on fail” node functionality be a solution to these pain points @BenW ? It would likely be simpler at first to improve node-level retrying before assessing workflow-level strategies.
A wait node capable of extended pauses is in the works, and those core changes will make it easier to add extended waiting in other contexts. With long waiting, we could make “Retry on fail” functionality configurable - perhaps parameters for # of retries and retry time interval (in sec, mins etc). Would also be interesting to explore functionality like exponential backoff (retry 1min later, then 2min, then 4 etc). to help in rate limiting scenarios.
For me, the existing retry mechanism has surprisingly solved most of my workflow errors. At the moment I only have to restart very few workflows by hand.
Oddly enough I raised a request internally a while back to allow an expression in the wait time which would allow this without needing another package.
Jumping in here to say that being able to retry a workflow at flexible intervals automatically would be super useful. It would be nice to not have to select it on every node—I like the way the workflow-level replay works. 5 seconds is not long enough, especially for Google Sheets.
I’ve been thinking about this problem a lot, and decided I needed a way to store all webhook requests and replay them as needed. This thought eventually led me to the discovery of hookdeck.com
So my plan moving forward is to send all webhooks into hookdeck.com which then forwards them to n8n
It would be amazing if this extra step wasn’t needed though…