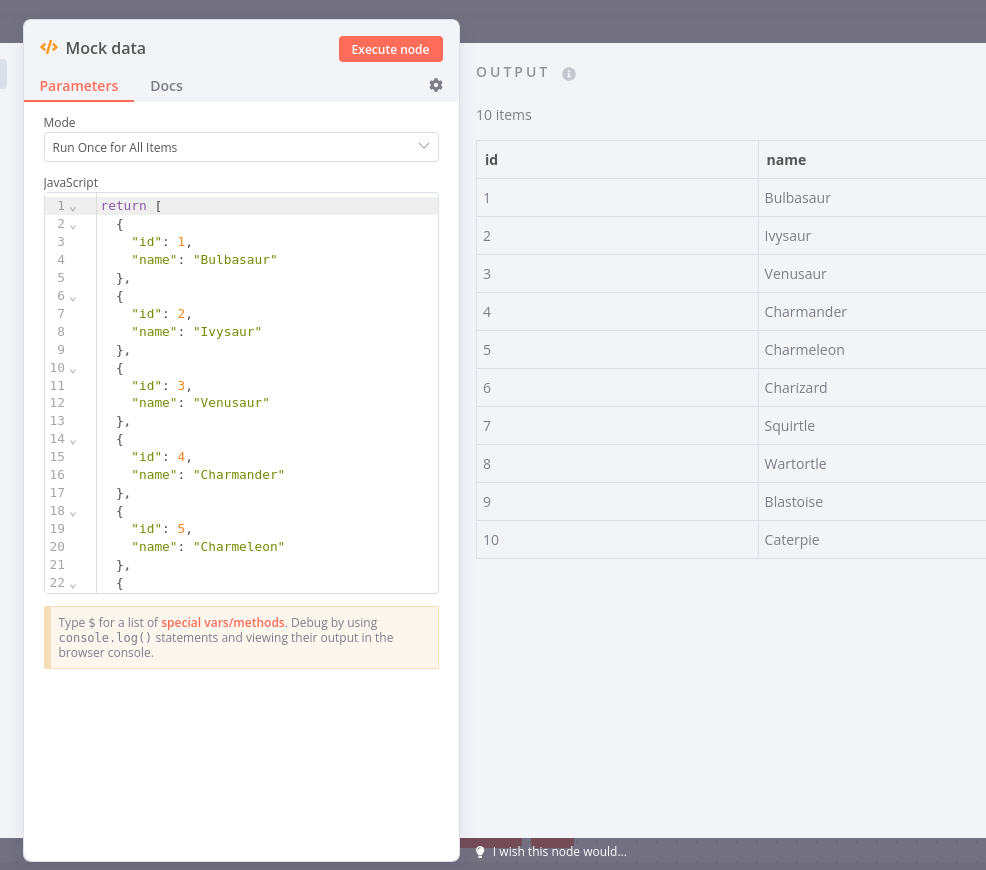
I have a flow for sending messages to Whatsapp from a spreadsheet in Google Sheets.
Basically, I configured the workflow to check every 10 minutes if there is a new contact in the spreadsheet and send messages.
I want to prevent contacts from receiving duplicate messages. For this, I currently have two configurations:
I have an item list node that checks for duplicates;
I have a column that is filled in whenever the workflow comes to an end. And I work with a filter to avoid sending messages to contacts that already have this tag.
I’ve had some embarrassing situations of sending many repeated messages and that’s why I’ve been creating these security locks.
Is there some setting I’m missing that could make the chance of duplicate even more remote?
For example: if for some reason the node that marks that the contact has already received the messages fails, I am exposed to the possibility of an endless duplication loop.
Hi @lfilippi, your approach seems very sensible to me and I can’t think of anything else to add. By using the Item Lists node for de-duplication you take care of removing duplicates in the current workflow, by using the additional table column you keep track of previously processed items.
Personally, I’d consider using a SQL database for a job like this as it allows enforcing constraints (for example, making sure a phone number exists only once in a table) and querying data in a very flexible way. On the other hand, setting up a full blown database adds a lot of complexity for a job like this.
Thank you @MutedJam. If the number of messages gains more scale I will consider your suggestion.
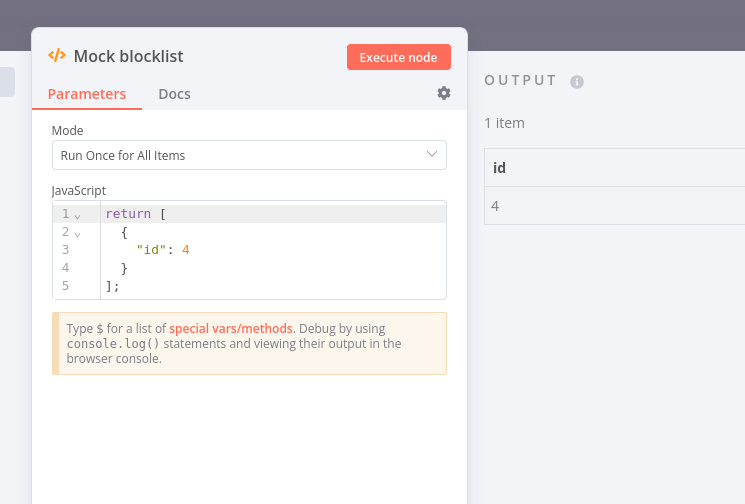
I want to have a list of banned numbers. But I’m stuck in the deployment, see if you can help me:
I created a new spreadsheet with the list of banned numbers. Before sending the messages, I want to check if any of the numbers are in the message sheet and delete the row if so.
The Whatsapp number is my unique identifier for both spreadsheets. Is it possible to do that? I have tried in a few ways but have not been successful.
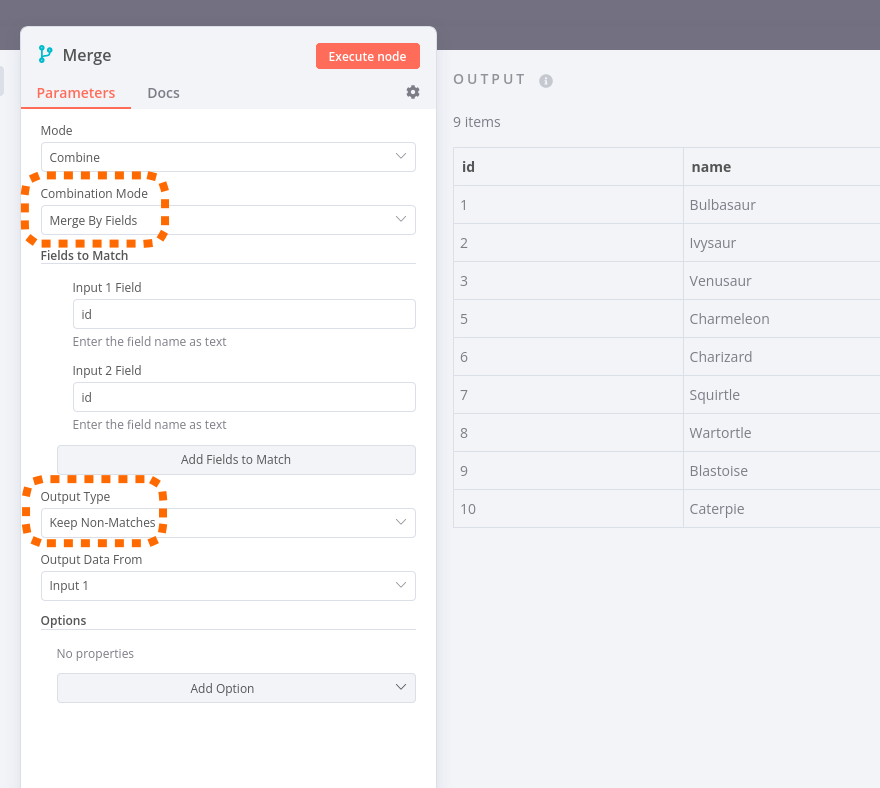
This ensures that only those items from my “data” list pass the Merge node that don’t exist on the “block” list (using the id field of each item). So in this case, Charmander with id 4 wouldn’t pass the Merge node:
Is there any value separator in the CONTAIN operation? I would like to add multiple words in a filter. Or is it necessary to create multiple condition blocks?
Is there any way to interrupt the workflow operation if the MERGE node fails?