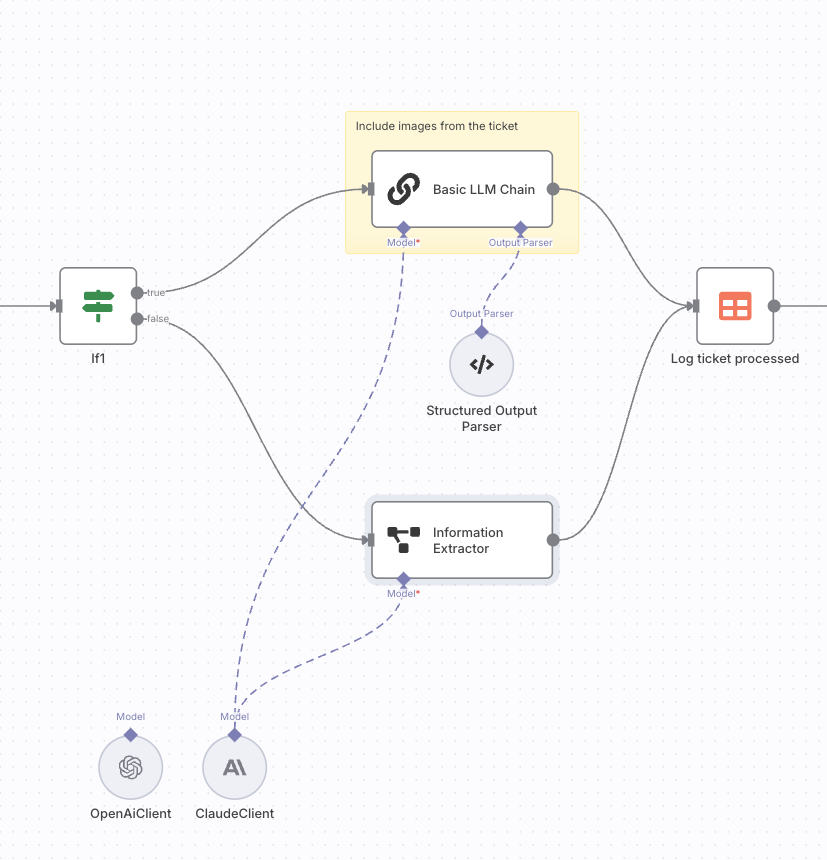
The idea is:
The Chat Messages parameter of the Basic LLM Chain node cannot dynamically parse multiple images input by the node.
The Chat Messages parameter of the Basic LLM Chain node cannot dynamically parse multiple images input by the node.
I’m actually in the same boat with you. I’m performing simple classification based on user’s input and sometimes that contains one or more images. Now I have to do IF but it causes me to duplicate the prompt, the input, etc.
Going forward I’m considering just to do a simple HTTP Request. However that comes at a price of losing all benefits of built in AI nodes.