There was a problem sending hook: “nodeExecuteAfter”
There was a problem sending hook: “workflowExecuteAfter”
This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). The promise rejected with the reason:
Error [ERR_IPC_CHANNEL_CLOSED]: Channel closed
at new NodeError (node:internal/errors:372:5)
at target.send (node:internal/child_process:739:16)
at /usr/lib/node_modules/n8n/dist/WorkflowRunnerProcess.js:299:17
at new Promise ()
at sendToParentProcess (/usr/lib/node_modules/n8n/dist/WorkflowRunnerProcess.js:298:12)
at process. (/usr/lib/node_modules/n8n/dist/WorkflowRunnerProcess.js:371:15)
at pro
cess.processTicksAndRejections (node:internal/process/task_queues:95:5)
latest n8n ready on 0.0.0.0, port 5678
Version: 0.203.1
nodejs 18.0.0
Ubuntu Linux 22.04.1 (8B 4 cores)
Nov 19 13:09:47 vmi1086503 kernel: [ 3889.906767] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/user.slice/user-1001.slice/session-2.scope,task=node,pid=4506,uid=0
Nov 19 13:09:47 vmi1086503 kernel: [ 3889.906819] Out of memory: Killed process 4506 (node) total-vm:22203092kB, anon-rss:479468kB, file-rss:0kB, shmem-rss:0kB, UID:0 pgtables:7308kB oom_score_adj:0
Nov 19 13:09:47 vmi1086503 systemd[1]: session-2.scope: A process of this unit has been killed by the OOM killer.
Nov 19 13:09:47 vmi1086503 kernel: [ 3889.946583] oom_reaper: reaped process 4506 (node), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
Glad to hear you figured out what was wrong here @Edmunds_Priede, thanks for confirming!
n8n can be quite memory hungry as it has no built-in limits when processing large amounts of data. If it’s mostly n8n consuming the memory on your system, it can be worth reducing the amount of data processed in a single workflow execution.
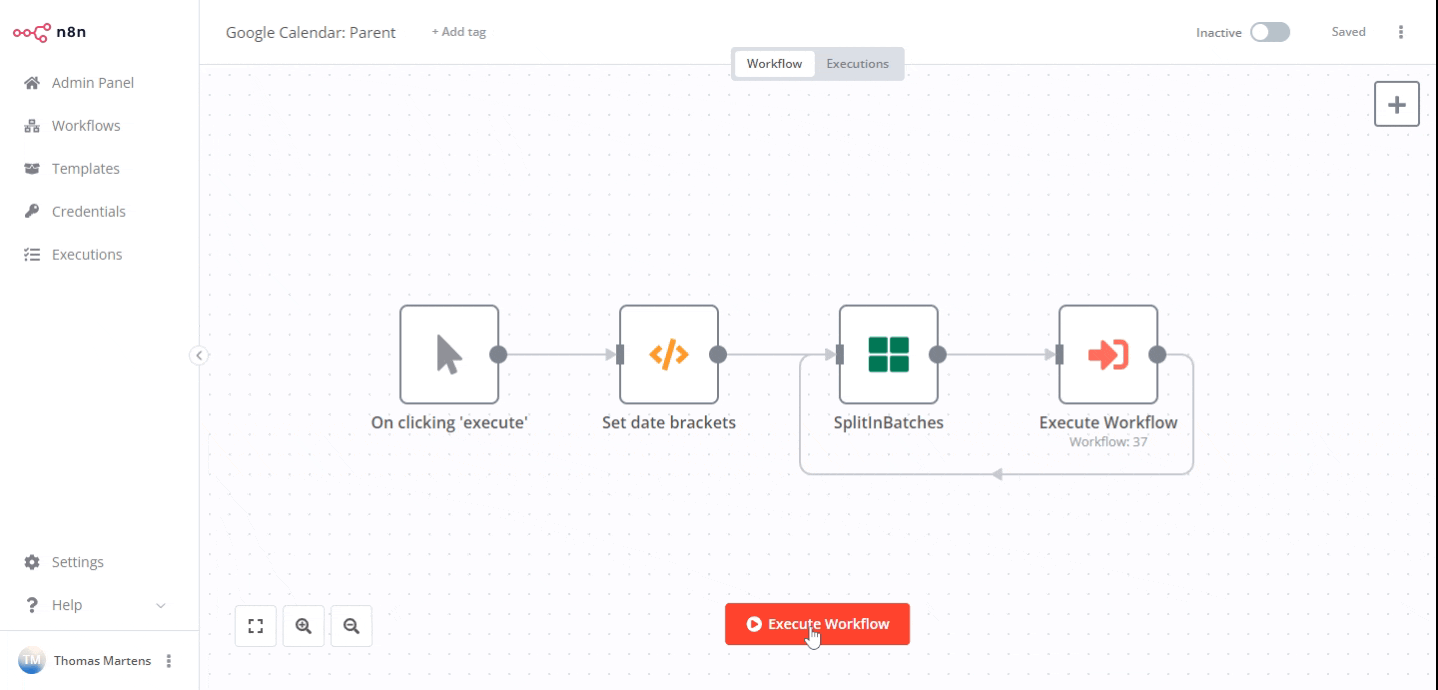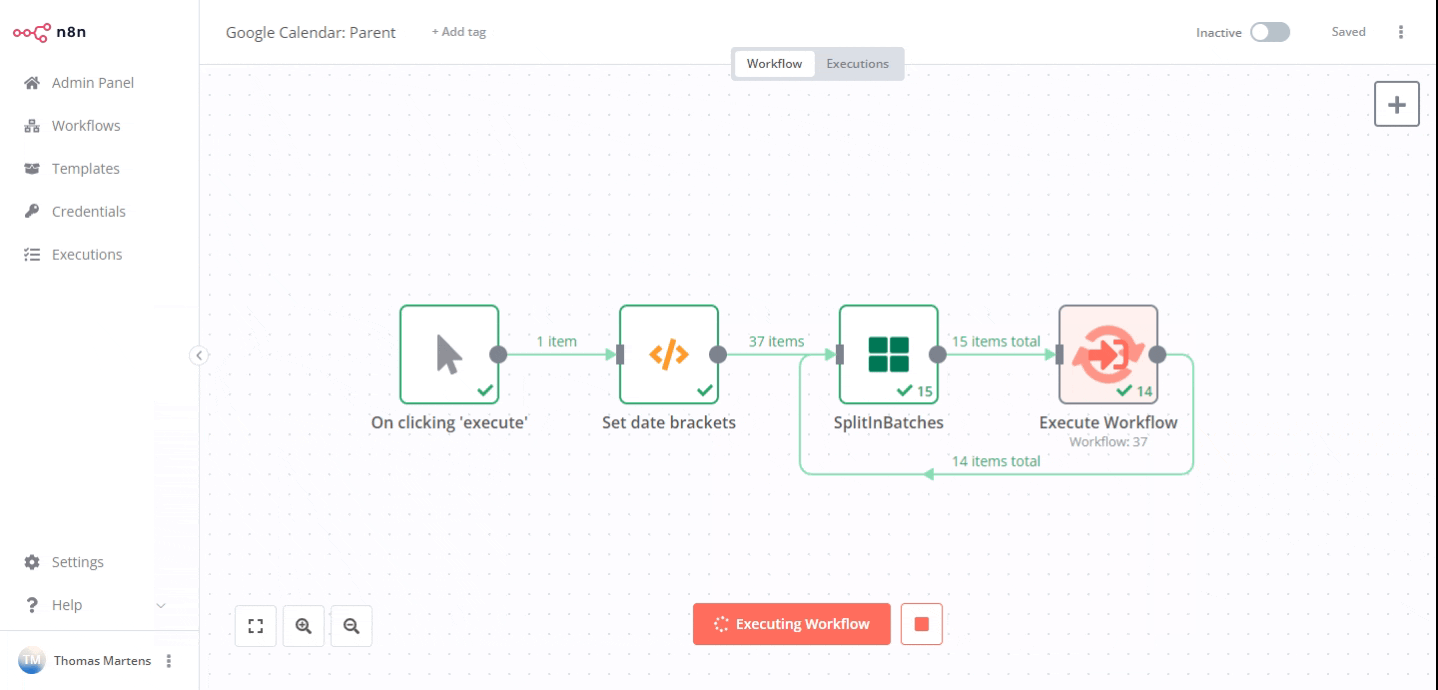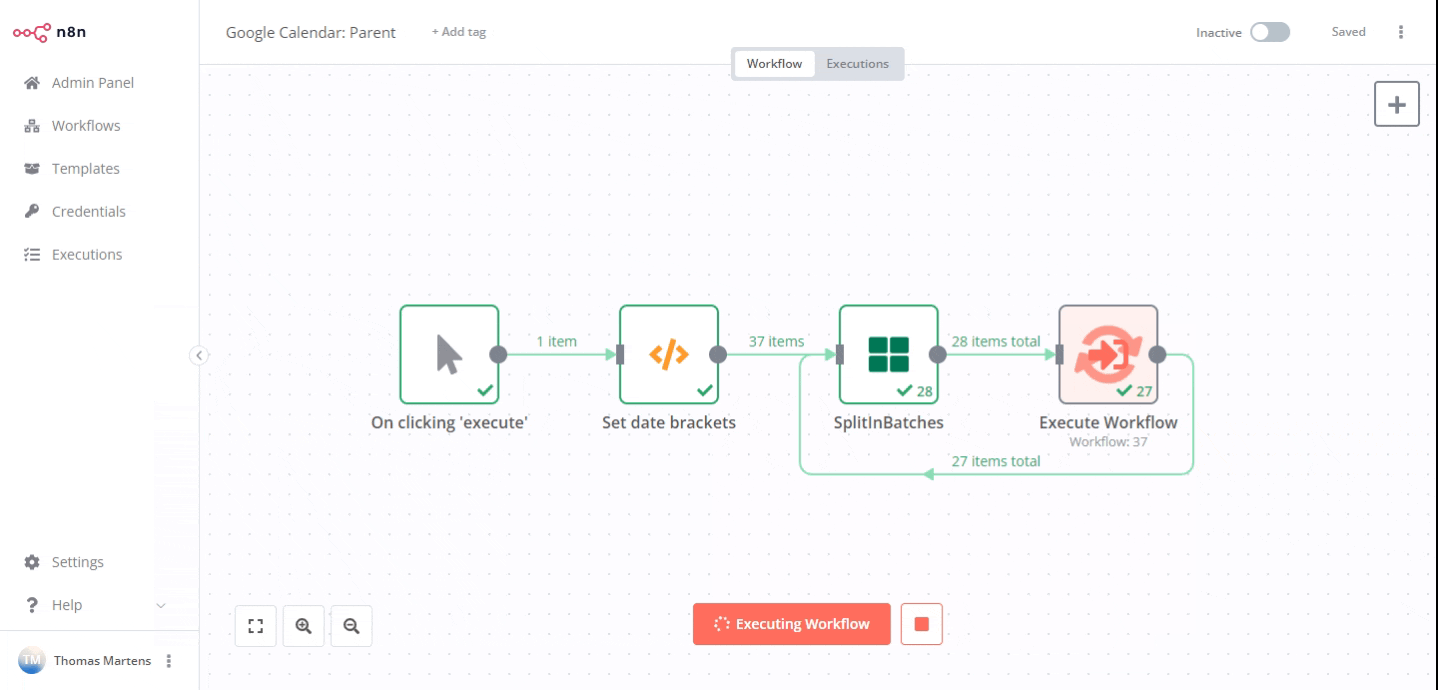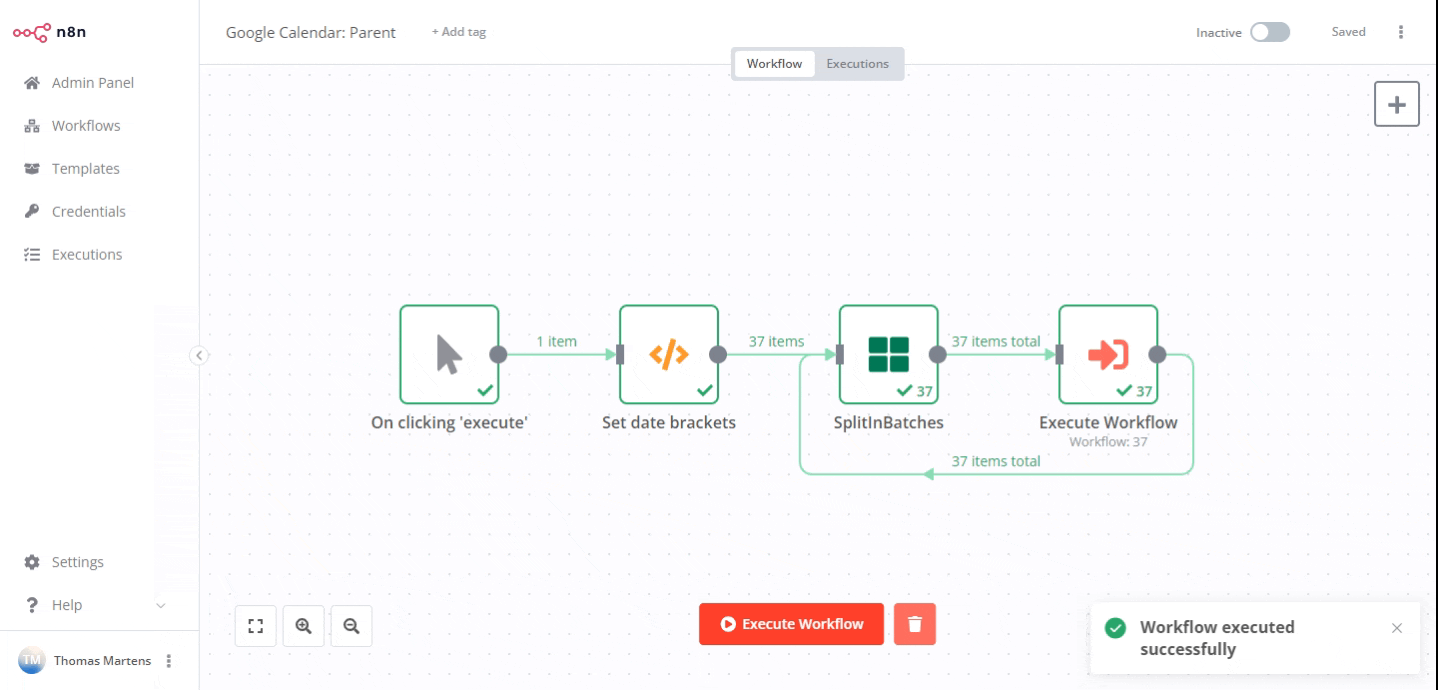
A quick example on how to address this in n8n: I was working with a user who had trouble importing all Google Calendar events the other day. In such a scenario it could make sense to first define a sensible pagination schema in the parent workflow (in this example case date ranges of one month each) and then have your parent call sub-workflows for each of these pages (with the sub-workflows only returning a very small dataset if any).
That way, memory would only be required for each sub-workflow execution processing only a sub-set of your data and would become available again afterwards.
The workflows looked like this:
Parent
Sub-workflow
Now only month worth of data would be processed at once rather than three years:
Great recipe, thanks! I noticed that you’d have an overlap between your end date of one month, and the start date of the next. I modified the one line of code as follows: upper: new Date(current_date.plus({month: 1}) - 10)
0.01s is enough granularity for me, but you could also -1 for 1/100th of a second or -1000 for a whole second.