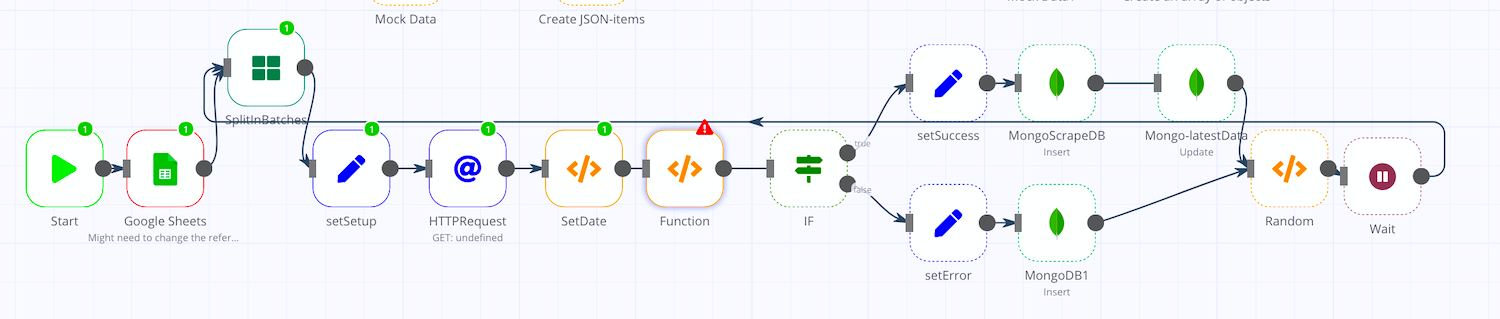
I have a scraping workflow. I have a list of 500+ URLs to scrape. I thought that by using split in batches with batch size of 1, it will run smoothly because it completes the entire process on 1 item before restarting the process on the next item. However, I am getting the “unknown reason” crash and sure enough the logs refer to a JavaScript memory error.
<--- JS stacktrace --->
FATAL ERROR: MarkCompactCollector: young object promotion failed Allocation failed - JavaScript heap out of memory
<--- Last few GCs --->
[895:0x559a2502df80] 285750 ms: Scavenge (reduce) 491.5 (493.2) -> 491.3 (499.2) MB, 8.5 / 0.0 ms (average mu = 0.524, current mu = 0.218) allocation failure
[895:0x559a2502df80] 285798 ms: Mark-sweep (reduce) 493.2 (499.2) -> 493.0 (503.0) MB, 41.0 / 2.7 ms (+ 882.9 ms in 169 steps since start of marking, biggest step 56.0 ms, walltime since start of marking 1385 ms) (average mu = 0.453, current mu = 0.413
Can someone explain what is the best way to split this into separate workflows?
I was thinking that the part after the IF node could be split into three separate workflows (one for true and one for false). Woudl that help?
Another consideration is that the documents I am retrieving are fairly large (up to 5mb per document). I’m open to suggestions on best practice here - should I run some functions on HTTP Request output to reduce the size that I save to to MongoDB documents?
Following what Jan explained in the post below should do it. I think moving everything between the Splitbatches node and the Wait node to its own workflow and use the Execute Workflow node to call the new workflow. That way, per each execution, the memory will be freed up.
Thanks for the quick reply @RicardoE105. I have separated it into two workflows. Workflow 1 triggers workflow 2 and the data is passed through. But when Workflow 2 calls Workflow 1, I can’t figure out how to make it get the next URL from Google Sheets.
update - hadn’t connected Execute Workflow node in Workflow 1 back to the Split in Batches node!
However - I am still getting crashes so I’d like to ensure that there is only one execution of each workflow running at a time. i.e. Workflow 1 starts, Workflow 1 executes Workflow 2 and end and stops, Workflow 2 starts, Workflow 2 ends, Workflow 1 starts with next item. I’ll have a think how to do this
The current solution would still keep the execution data until all the 500+ URLs are processed, which can result in the crash.
To avoid this, you can take the following approach:
Add a new column in your sheets to keep a track of which URL got scrapped
Fetch the URL that have not been scrapped, and pass only one URL to the next nodes
Scrape the data and at the end of your workflow update the Scraped? field in your Sheet to true.
Since your workflow will have a fresh execution for each URL, the data will be stored per execution for each URL separately. This alternate approach should solve your issue
Worked perfectly! So satisfying so see CPU usage spike and drop using htop
Can you explain one thing - why does the execution log show that Workflow 1 is always running? My guess is the SplitInBatches node causes it to stay alive rather than “complete” at the end of each item being passed on to Workflow 2.
Yes, the workflow will keep running unless all the items have been split and processed. Once the processing is complete Workflow 1 will return to either Success or Error state, based on the output.