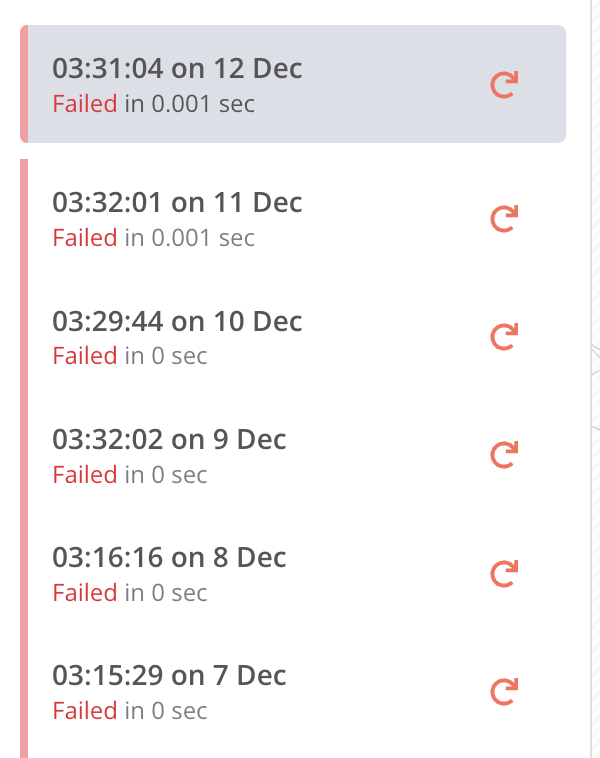
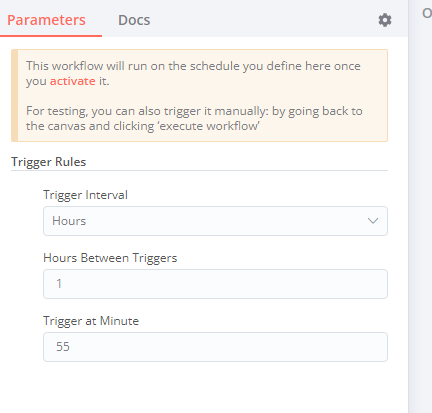
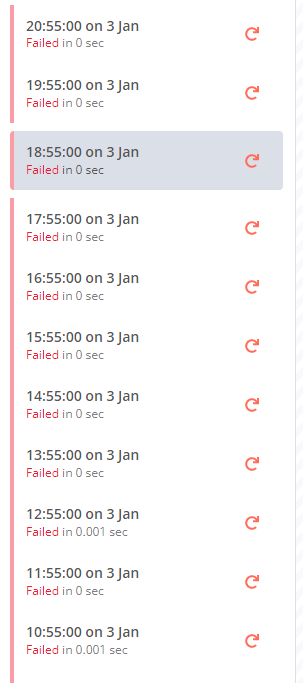
My workflow fails in 0.0s when triggered by cron, but manual execution work correctly. The workflow is pretty big and unfortunately I can’t share it, but it does a lot of requests. The issue started a few n8n updates ago (my current version is 0.205.0) and refactoring the workflow into separate workflows that trigger each other did not help. There are no error messages, it just fails.
If manual executions work and seeing that it seems to fail immediatly, it might have to do with your cron node. Can you share a screenshot of your cron node configuration? Are you also able to share a screenshot of your execution view to see whether any node after the cron node runs?
the physical log file has a lot of these (105805 is the one in the SS above)
{“level”:“error”,“message”:“Problem with execution 105805: Unable to find data of execution "105805" in database. Aborting execution… Aborting.”,“metadata”:{“file”:“WorkflowRunner.js”,“timestamp”:“2023-01-05T07:26:55.284Z”}}
and there are 2 warnings about isLuxonDateTime
{“level”:“warn”,“message”:“There was a problem sending message to UI: Cannot read properties of undefined (reading ‘isLuxonDateTime’)”,“metadata”:{“file”:“NodeExecuteFunctions.js”,“function”:“sendMessageToUI”,“timestamp”:“2023-01-05T05:35:17.503Z”}}
PS: I’ve tried a very simple 2 node flow, one schedule node and one SMTP mail… It doesn’t work either. This probably relates to the k8s setup somehow, not n8n itself, I just am unable to find clues as to why
I’ve found the problem, writing it here in case someone makes the same stupid mistake…
A few days ago we had a problem while upgrading the n8n version, it got stuck during the initial DB migration phase on k8s and we’ve setup a new DB for the installation to test things.
Now I found that the “secret in k8s” for worker config was not reverted to prod DB name, it was on the test DB name.
main pod DB → n8n
worker pod DB → n8n_test
hence they were linked via the encryption key, but not via DB and it caused this erratic behavior.
Ah wow, would def. have taken me a while to figure that out.
Thank you very much for sharing. I am sure it will be helpful for somebody else in the future. Also something we should look into and throw an Error which makes discovering that easier.