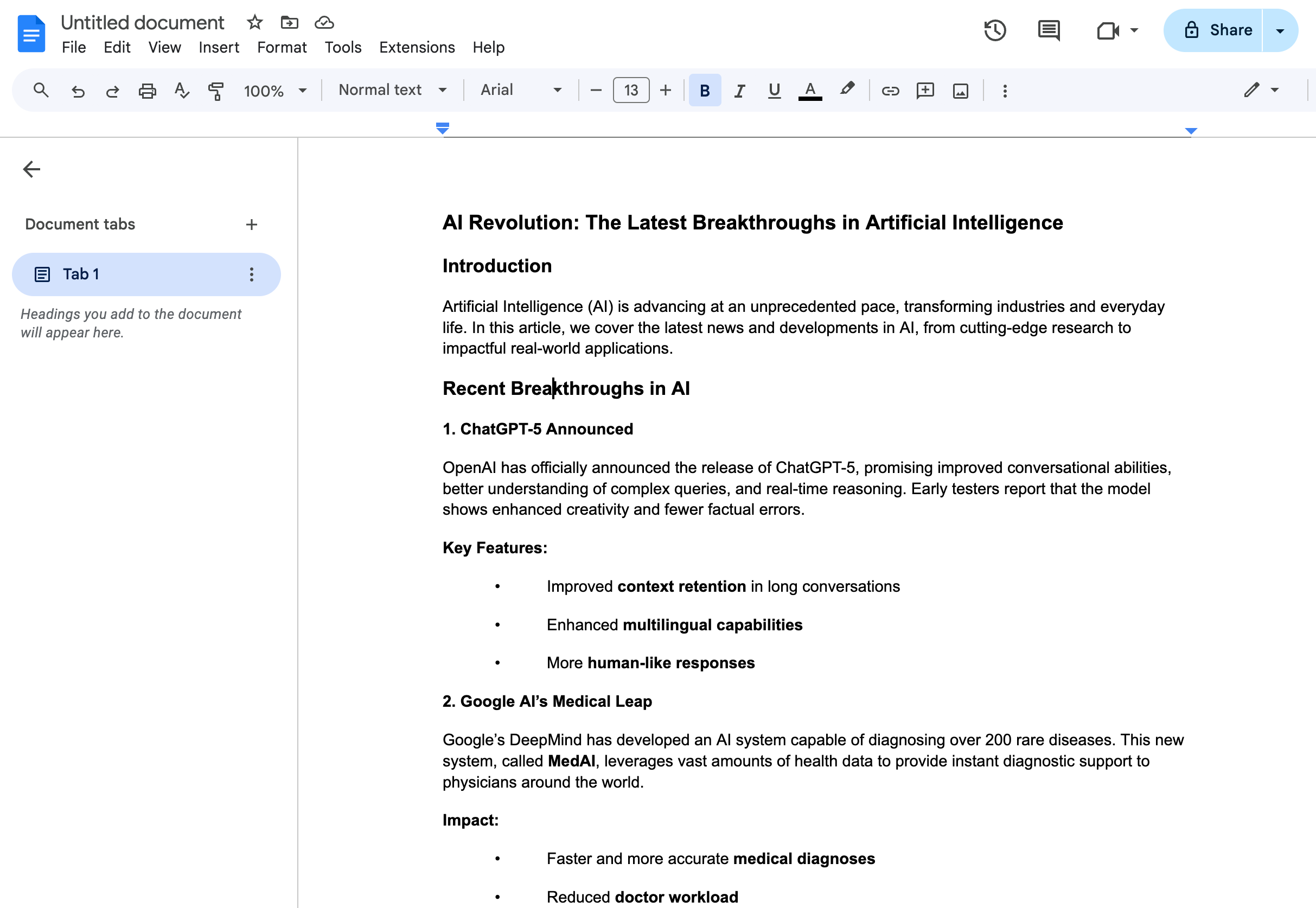
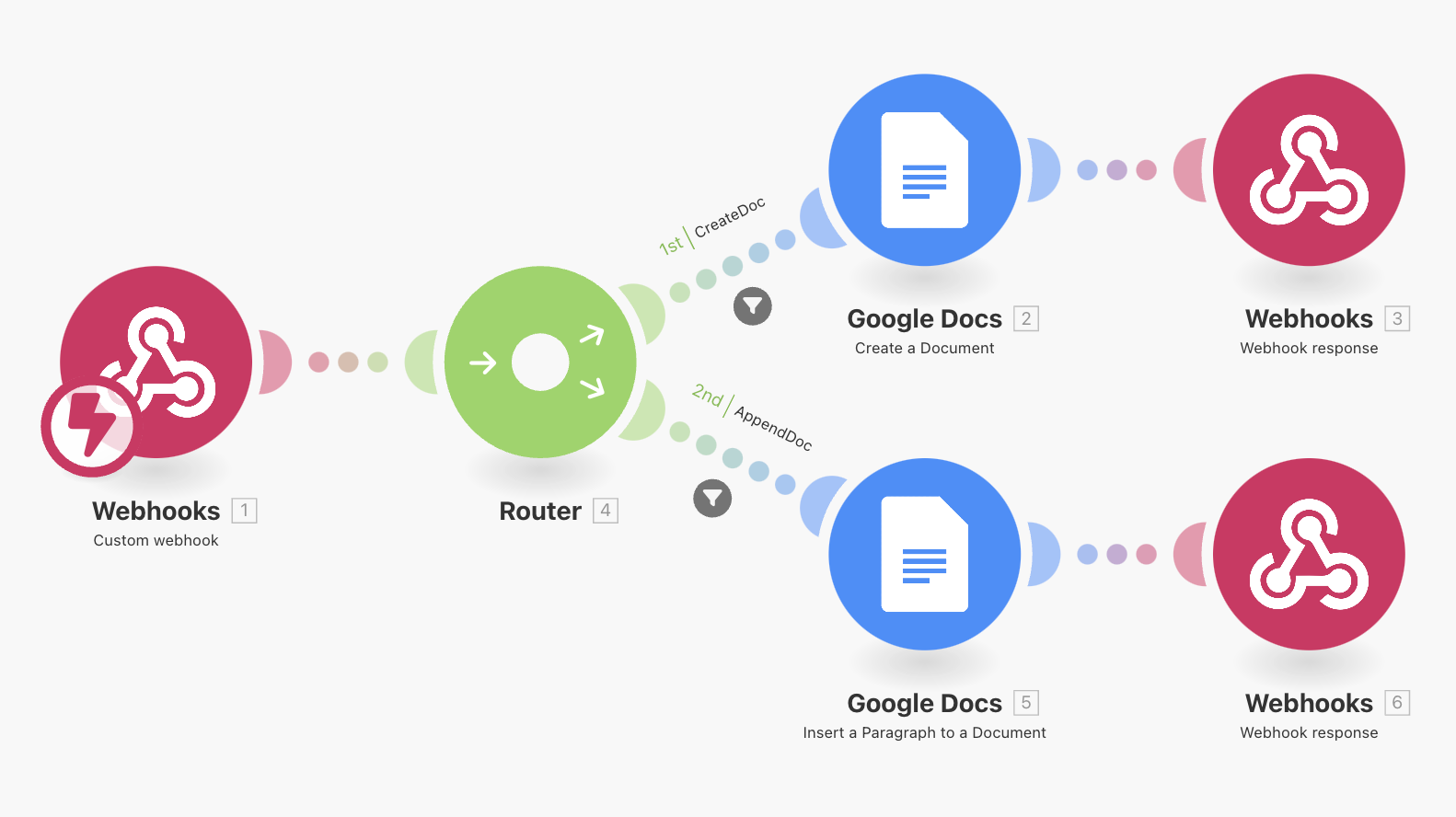
Hi guys,
I ended up creating a code node to do this. Claude seemed better than ChatGPT in generating tihs code - and here are the docs if you need to get it to add more functionality: Requests | Google Docs | Google for Developers
const markdown = $input.first().json.data;
// Function to convert Markdown to Google Docs API requests
function convertMarkdownToGoogleDocsRequests(markdown) {
const requests = [];
let index = 1; // Start inserting at position 1
// Split by line breaks to handle formatting separately
const lines = markdown.split('\n');
for (const line of lines) {
const rawText = line.trim();
if (!rawText) continue;
let text = rawText;
const startIndex = index;
// Remove the markdown symbols for heading and list indicators before inserting
if (text.startsWith("# ")) {
text = text.substring(2);
} else if (text.startsWith("## ")) {
text = text.substring(3);
} else if (text.startsWith("### ")) {
text = text.substring(4);
} else if (text.startsWith("#### ")) {
text = text.substring(5);
} else if (text.startsWith("- ")) {
text = text.substring(2);
} else if (text.startsWith("* ")) {
text = text.substring(2);
} else if (/^\d+\.\s/.test(text)) {
text = text.replace(/^\d+\.\s/, "");
}
// Remove bold and italic markdown before inserting text
// Store positions for later styling
const boldRanges = [];
const italicRanges = [];
// Find bold text positions (before removing markers)
let boldText = text;
const boldRegex = /\*\*(.*?)\*\*/g;
let boldMatch;
while ((boldMatch = boldRegex.exec(text)) !== null) {
const innerText = boldMatch[1];
const start = boldMatch.index;
const end = start + boldMatch[0].length;
boldRanges.push({
text: innerText,
originalStart: start,
originalEnd: end
});
}
// Find italic text positions (before removing markers)
let italicMatch;
const italicRegex = /(?<!\*)\*(?!\*)(.+?)(?<!\*)\*(?!\*)/g;
while ((italicMatch = italicRegex.exec(text)) !== null) {
const innerText = italicMatch[1];
const start = italicMatch.index;
const end = start + italicMatch[0].length;
italicRanges.push({
text: innerText,
originalStart: start,
originalEnd: end
});
}
// Remove markdown indicators for bold and italic
text = text.replace(/\*\*(.*?)\*\*/g, "$1");
text = text.replace(/(?<!\*)\*(?!\*)(.+?)(?<!\*)\*(?!\*)/g, "$1");
// Insert clean text without markdown
requests.push({
insertText: {
location: { index: startIndex },
text: text + "\n"
}
});
const textEndIndex = startIndex + text.length;
// Apply heading styles based on original markdown
if (rawText.startsWith("# ")) {
requests.push({
updateParagraphStyle: {
range: { startIndex, endIndex: textEndIndex },
paragraphStyle: { namedStyleType: "HEADING_1" },
fields: "namedStyleType"
}
});
} else if (rawText.startsWith("## ")) {
requests.push({
updateParagraphStyle: {
range: { startIndex, endIndex: textEndIndex },
paragraphStyle: { namedStyleType: "HEADING_2" },
fields: "namedStyleType"
}
});
} else if (rawText.startsWith("### ")) {
requests.push({
updateParagraphStyle: {
range: { startIndex, endIndex: textEndIndex },
paragraphStyle: { namedStyleType: "HEADING_3" },
fields: "namedStyleType"
}
});
} else if (rawText.startsWith("#### ")) {
requests.push({
updateParagraphStyle: {
range: { startIndex, endIndex: textEndIndex },
paragraphStyle: { namedStyleType: "HEADING_4" },
fields: "namedStyleType"
}
});
} else if (rawText.startsWith("- ") || rawText.startsWith("* ")) {
// Format as bulleted list
requests.push({
createParagraphBullets: {
range: { startIndex, endIndex: textEndIndex },
bulletPreset: "BULLET_DISC_CIRCLE_SQUARE"
}
});
// Add proper indentation
requests.push({
updateParagraphStyle: {
range: { startIndex, endIndex: textEndIndex },
paragraphStyle: {
indentStart: { magnitude: 36, unit: "PT" }
},
fields: "indentStart"
}
});
} else if (/^\d+\.\s/.test(rawText)) {
// Format as numbered list
requests.push({
createParagraphBullets: {
range: { startIndex, endIndex: textEndIndex },
bulletPreset: "NUMBERED_DECIMAL_ALPHA_ROMAN"
}
});
// Add proper indentation
requests.push({
updateParagraphStyle: {
range: { startIndex, endIndex: textEndIndex },
paragraphStyle: {
indentStart: { magnitude: 36, unit: "PT" }
},
fields: "indentStart"
}
});
}
// Calculate adjusted positions for bold and italic after removing markdown
let adjustment = 0;
let lastProcessedPos = 0;
// Apply bold formatting (with adjusted positions)
for (let i = 0; i < boldRanges.length; i++) {
const range = boldRanges[i];
// Adjust for any previous formatting markers removed
const adjustedStart = startIndex + range.originalStart - adjustment;
// Update adjustment for next element
adjustment += 4; // ** at beginning and end (4 characters total)
requests.push({
updateTextStyle: {
range: {
startIndex: adjustedStart,
endIndex: adjustedStart + range.text.length
},
textStyle: { bold: true },
fields: "bold"
}
});
}
// Reset adjustment for italic formatting
adjustment = 0;
// Apply italic formatting (with adjusted positions after bold markdown is removed)
for (let i = 0; i < italicRanges.length; i++) {
const range = italicRanges[i];
// Adjust for previous bold formatting and previous italic markers
let adjustedStart = startIndex + range.originalStart;
// Count how many bold markers appear before this italic position
let boldAdjustment = 0;
for (const boldRange of boldRanges) {
if (boldRange.originalEnd <= range.originalStart) {
boldAdjustment += 4; // ** at start and end
}
}
// Count how many italic markers appear before this position
let italicAdjustment = 0;
for (let j = 0; j < i; j++) {
if (italicRanges[j].originalEnd <= range.originalStart) {
italicAdjustment += 2; // * at start and end
}
}
adjustedStart -= (boldAdjustment + italicAdjustment);
requests.push({
updateTextStyle: {
range: {
startIndex: adjustedStart,
endIndex: adjustedStart + range.text.length
},
textStyle: { italic: true },
fields: "italic"
}
});
}
index = textEndIndex + 1; // +1 for the newline
}
return requests;
}
// Convert Markdown to Google Docs API requests
const requests = convertMarkdownToGoogleDocsRequests(markdown);
return {
docs_request: { requests }
};
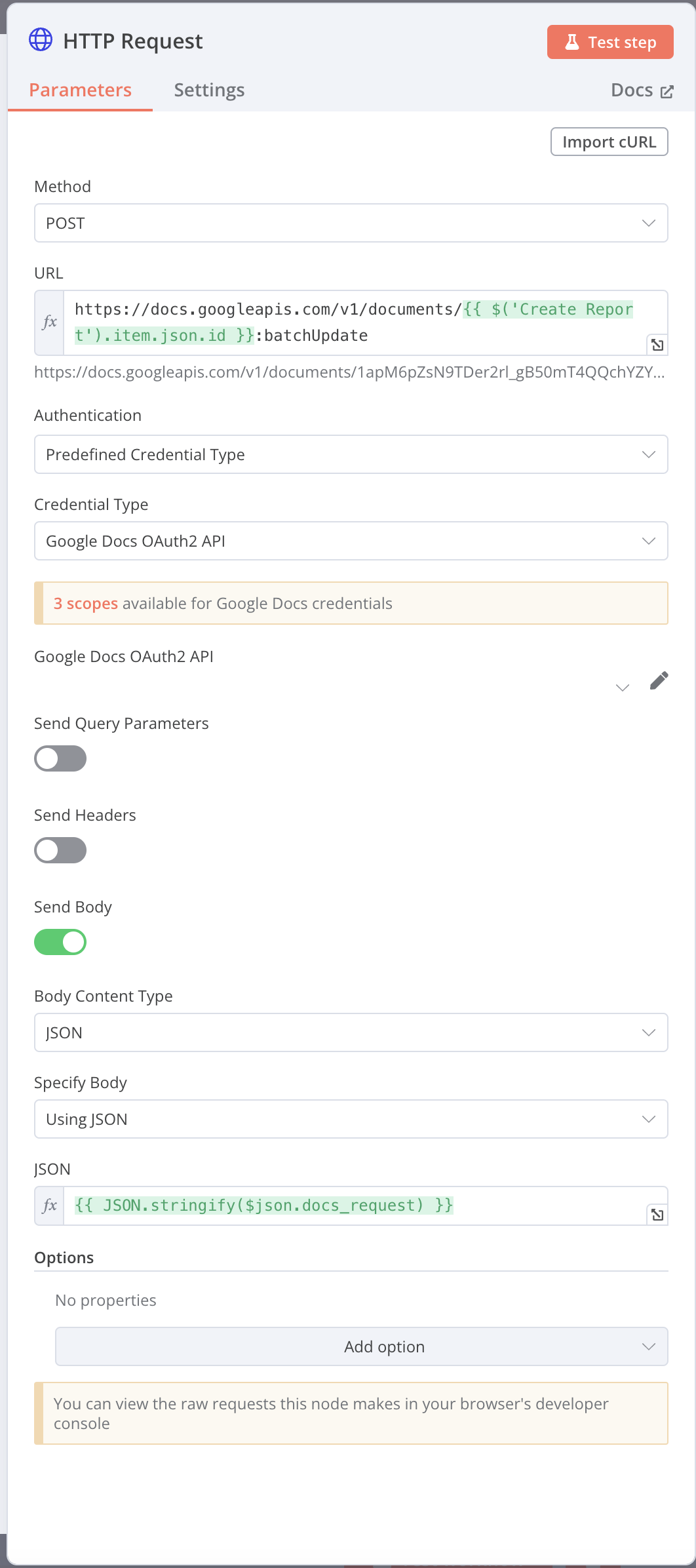
Note that it returns the request you’d need to send to Google Docs in the docs_request parameter, and then you can use it in a node like this: