![]() Hey everyone,
Hey everyone,
As I shared yesterday, the easybits Extractor just got released as a verified community node on n8n. With the setup now being faster than ever (auto-mapping + community node = about 2 minutes from zero to working extraction), I figured this is the perfect time to actually stress test the whole thing properly.
A few of you also asked me after my last posts about extraction accuracy – how well does it really hold up when the document quality drops? Clean PDFs are easy. Every solution handles those. But what about scanned copies, coffee-stained paper, or documents covered in pen scribbles? I wanted to answer that with actual numbers instead of guessing.
So I built a stress test workflow and I’m sharing it here so anyone can use it to benchmark their own extraction solution.
![]() What the workflow does:
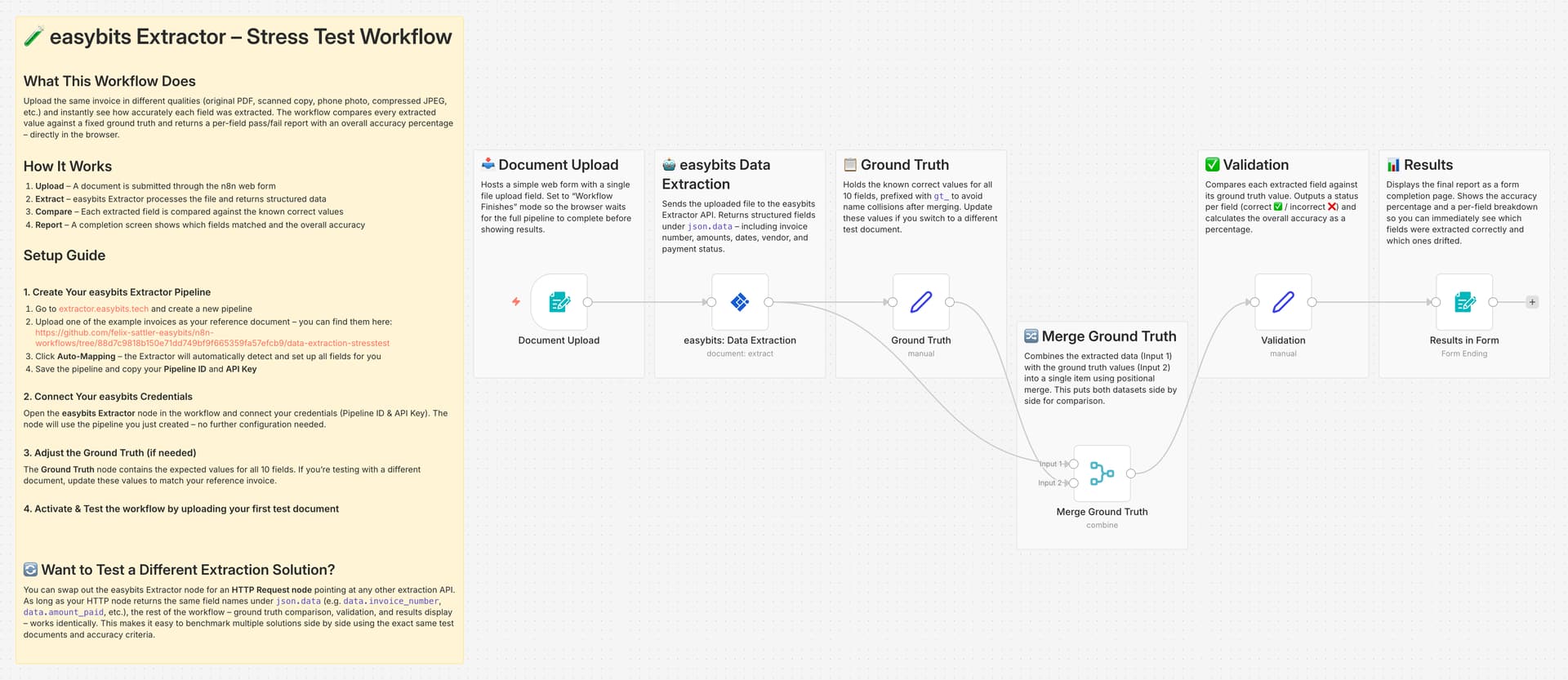
What the workflow does:
You upload a document through a web form. The workflow extracts the data, compares every single field against the known correct values (ground truth), and shows you a results page with a per-field pass/fail breakdown and an overall accuracy percentage. Upload, wait a few seconds, see the score. That’s the whole loop.
No Code node needed – the entire validation is built with native n8n nodes and expressions.
![]() The test documents:
The test documents:
I spent some time thinking about what actually makes a good stress test. Just degrading quality isn’t enough – you also need to test whether the extraction actually reads the document or just memorises where fields tend to appear. So I put together 11 test versions of the same invoice:
- Original – clean digital PDF. The baseline. Should be 100%.
- Versions 1–7 – progressive degradation. It starts mild with v1 (slightly aged scan, barely noticeable) and gets worse step by step. By v4 you’re looking at aged paper, coffee stains, and handwritten “Rec’d & OK” annotations. By v6, heavy coffee ring stains are sitting right on top of key fields. And v7 – “The Survivor” – has burn marks, pen scribbles (“WRONG ADDRESS? check billing!”), the amount due field circled and scribbled over, and half the document barely readable. If anything can extract data from that one, I’ll be impressed.
- 2 Layout Variants – same data, completely different visual structure. One uses a card-based layout with grouped sections, the other rearranges everything into a three-column format. These test whether the extraction actually understands the content or is just relying on positional patterns.
- 1 Handwritten Version – this one came from community feedback after my last post. Someone asked how extraction handles handwriting, so I added a fully handwritten version of the same invoice to the test set.
All test documents are available in my GitHub repo (link below), so you can use the exact same set to benchmark your own solution and compare results.
![]() How I set it up:
How I set it up:
The extraction side took about 2 minutes – created a pipeline on easybits, used the auto-mapping feature to detect the fields, dropped the verified community node into the workflow, connected credentials, done. The rest is native n8n: a Set node holding the ground truth values, a Merge node to combine extracted and expected data, a Validation node with expressions comparing each field, and a Form completion screen that displays the results directly in the browser.
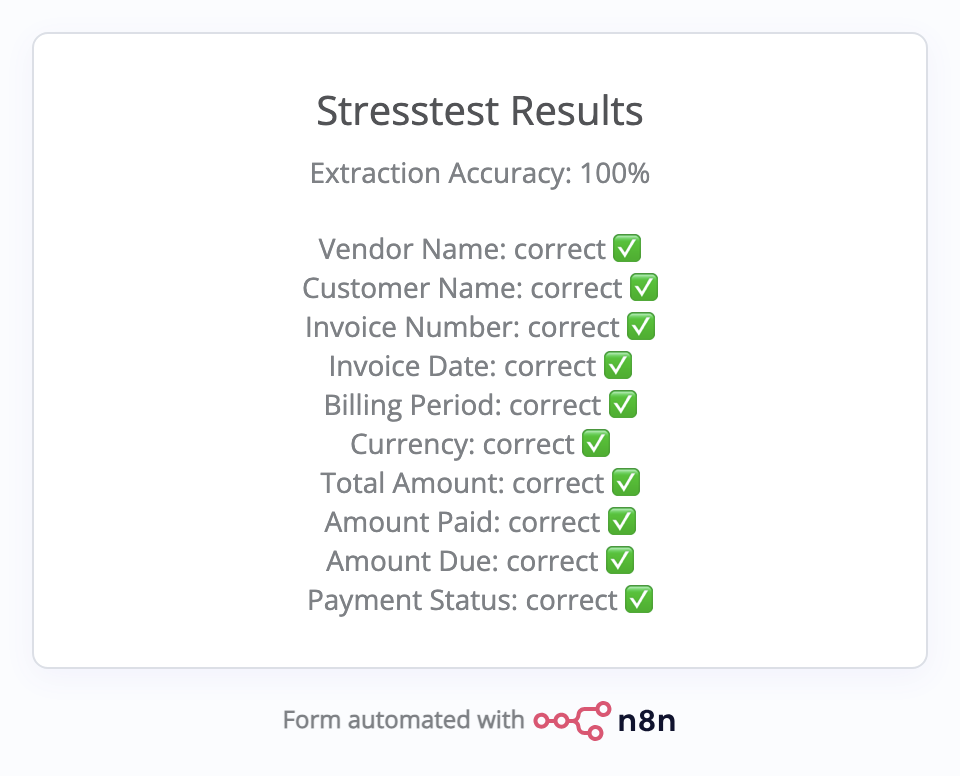
I’ve already done a first test run with the original invoice – 100% accuracy across all 10 fields, as expected. I’ll add a screenshot so you can see what the results page looks like.
![]() Want to test a different extraction solution?
Want to test a different extraction solution?
The workflow is designed to be solution-agnostic. You can swap out the easybits Extractor node for an HTTP Request node pointing at any other extraction API. As long as your response returns the same field names under json.data, the entire validation chain – ground truth comparison, per-field flagging, accuracy percentage, results page – works identically. So if you’re evaluating multiple tools, you can benchmark them all using the exact same workflow and test documents.
![]() What’s coming next week:
What’s coming next week:
I’m going to run all 11 documents through the workflow and share a full results breakdown here – accuracy percentages for every single version, from the clean original all the way down to the destroyed one and the handwritten version. I’ll also put together a short video walkthrough showing the workflow in action and how the results look across the different quality levels.
Links:
- Workflow JSON: GitHub link
- Test documents: GitHub repo
- easybits Extractor community node: Integration guide
Would love to hear if anyone runs the test with a different extraction solution – curious how the results compare. And if you have ideas for even nastier test documents, I’m all ears.
Best,
Felix