Which comes to my feature requests : when building LangChain and AI workflow, I often have to run multiple AI Queries (for exemple for evaluating individualy the results of a retrieval operation).
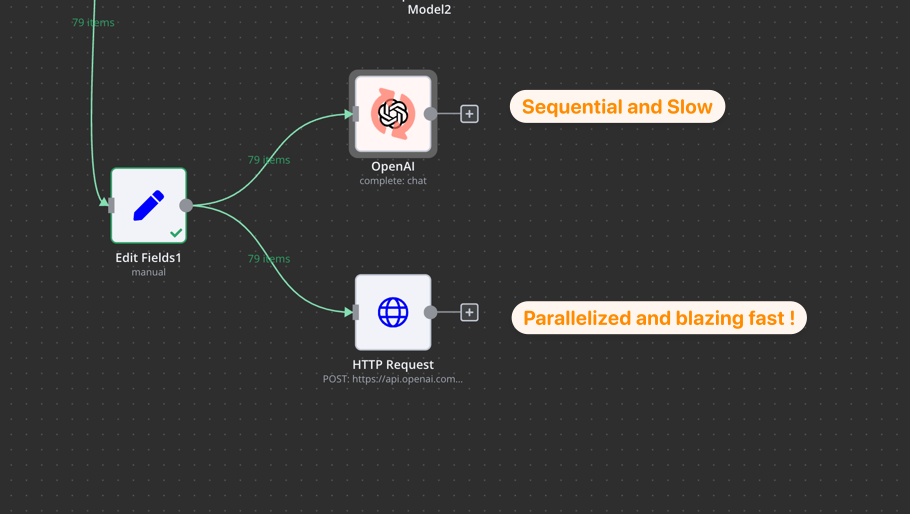
Current OpenAI node and LangChain nodes does not seem to support that. As a workarount I tried running the same requests in a HTTP node and it is really faster.
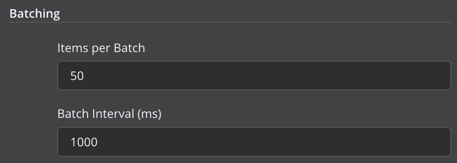
I think it would be convenient to have the batching options on AI node :
Good point, often for performance I recreate other node operations with the HTTP Node just for the batching!
What I think would greatly help a lot of nodes is allowing the developers of declarative nodes to make batching configurable, and also allow them to expose that settings to the user.
Can we please please have this?
We end up using the HTTP node for parallel requests which defeats the purpose of using n8n when we actually have to configure the endpoints ourselves for performance purposes.
good evening, is this adjustment now available for the community edition?
I just updated to 1.46.0, but the OpenAI node does not find this batching option at any time
@Jon All right? Can you help me as I come back to this version of the node? This batching issue interests me very much but in the OpenAI node I am not able to operate.
Hi @Jon
It is definitely missing on AI nodes. For exemple I often replace “information extractor” by http request to allow batching API calls. But using HTTP Request is not as comfortable because you have to work with API docs.