Theoretically more or less everything is possible to be implemented. The problem is just how complicated it will be. Throttling (if done properly to scale) is not that simple. After all, it would have to work across workflows. So it would have to coordinate via some kind central datastore like a database. Also, should it probably not simply fail, once it hits the limit, it should then kind of queue them and then process later (once there is again “space”).
So agree that it is important but for it to be created we probably have to create some abstraction layer that nodes can store and retrieve data from the database. That will be important here and also for other use cases. Like for example making it easy to check if something got already processed by a previous run (like for example items of an RSS-Feed).
But if the queue would only be per node the whole point of throttling would be gone or not? At least I would have expected that you want to avoid something like hitting some kind of API to fast. If it would not work on a global level for all workflows that run at the same time it would be useless.
It would only work for if there is a loop in a workflow and if it has a lot of items and the nodes afterward has to make a separate API request for each.
Indeed APIs are the use case. Across all workflows would be even better but isn’t really a requirement of mine - or even on the wishlist. For me each workflow is separate enough and would just get other API credentials with separate quotas.
But you do bring up an interesting point:
For some APIs these quotas might be per method call or per general usage. For the latter one would need some kind of contextual key and counters. Redis comes to mind. On the other hand for the most simple use cases requiring some externals storage sounds like overkill when just some in-memory counter would be good enough.
However, a throttling node like you need would probably cause problems right now. Releasing just a few items at a time and then keep on processing until the “end” is not what n8n got build to do. So to allow something like that it would for sure need quite some changes.
What you, however, could do for now is to use the “Split In Batches” node like in this workflow:
You could so loop over all items one after another (or 5, 10 or whatever) and save in a Function-Node the last time it got executed (probably best in the node-context). Depending on that you can then do a timeout and wait.
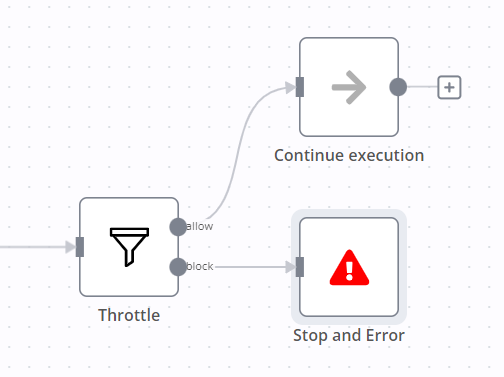
I created an n8n community node, n8n-nodes-throttle, which might have the functionality you are looking for. It allows you to set the minimum allowed interval between executions and blocks the execution if the interval is too small.
Please test this node and share your experiences or suggestions.